- The paper introduces Self-Filtered Distillation (SFD) to improve patent classification by leveraging LLM-generated trust indicators for enhanced reliability.
- It employs a three-stage process that evaluates reasoning quality using metrics such as self-consistency, class entailment alignment, and LLM agreement score.
- Experimental results on the USPTO-2M dataset demonstrate significant performance improvements, with higher F1 scores and strong alignment with human judgment.
Self-Filtered Distillation with LLMs-generated Trust Indicators for Reliable Patent Classification
The paper introduces a novel framework, Self-Filtered Distillation (SFD), aimed at improving patent classification by leveraging reasoning quality as a supervision signal. The framework reinterprets LLM-generated rationales as trust indicators, systematically addressing shortcomings inherent in treating rationales as ground-truth labels.
Framework Overview
Self-Filtered Distillation (SFD)
The SFD framework consists of a three-step process designed to evaluate and utilize the reasoning generated by LLMs:
- LLM-Based Prediction and Reasoning Generation: In this initial stage, an LLM predicts labels and generates rationales for a given patent document. The generated rationale is not directly used for training but serves as auxiliary information to estimate the reliability of the input sample.
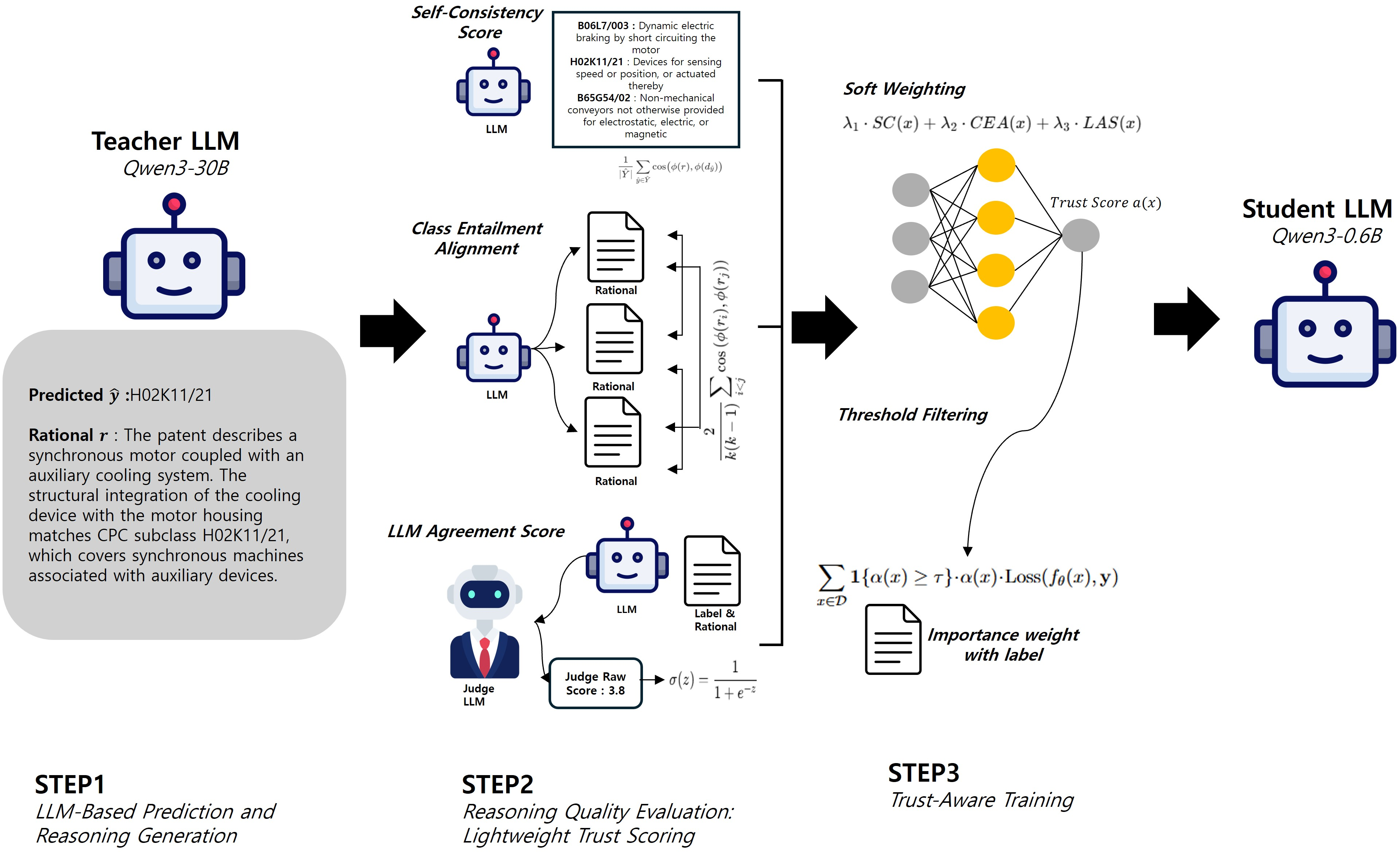
Figure 1: Overview of the proposed Self-Filtered Distillation(SFD) framework: It consists of three stages.
- Reasoning Quality Evaluation: The quality of the rationale is assessed using three unsupervised metrics: Self-Consistency (SC), Class Entailment Alignment (CEA), and LLM Agreement Score (LAS).
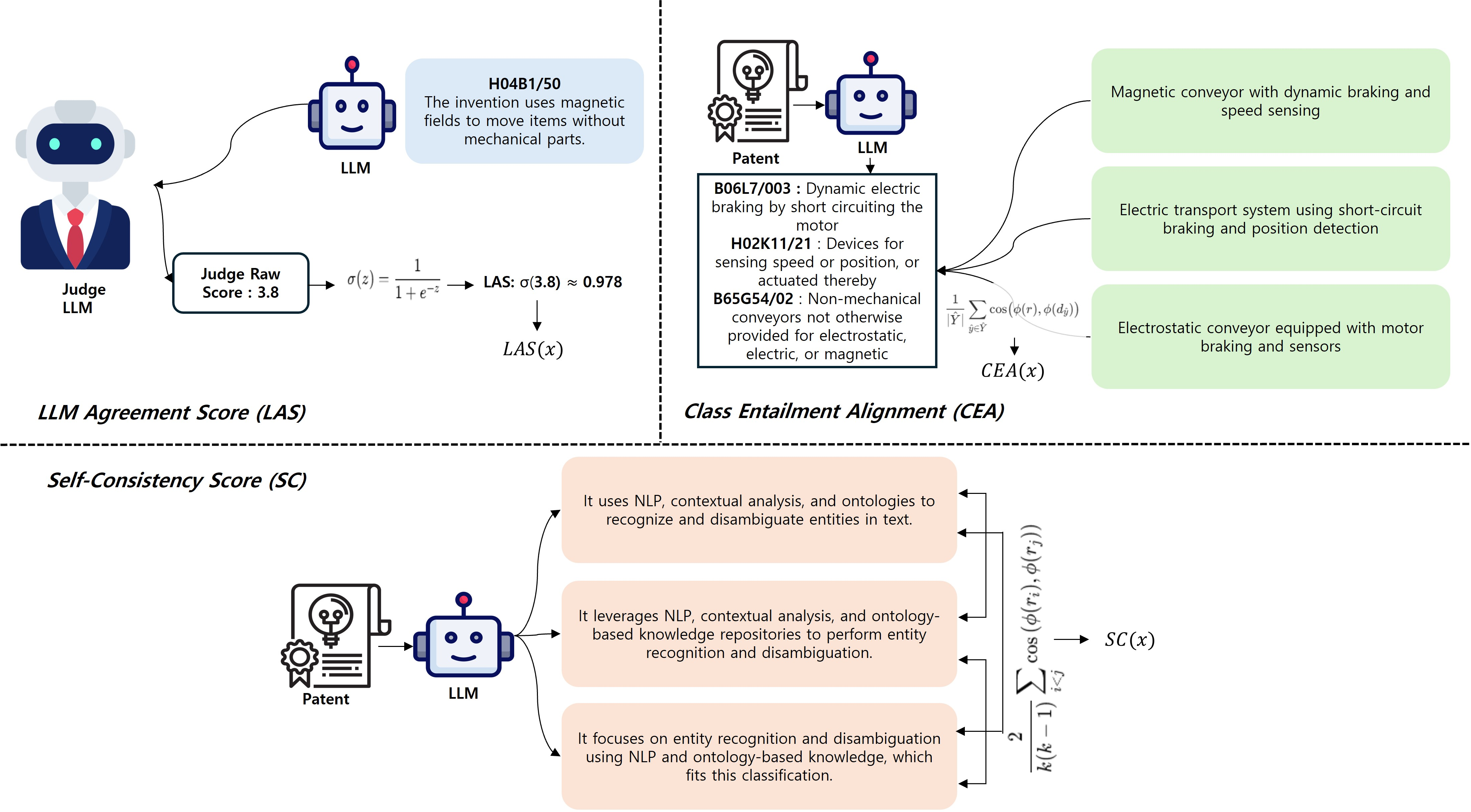
Figure 2: Overview of the three trust indicators in our Reasoning Quality Evaluation.
- Trust-Aware Training Control: The calculated trust score determines the influence of each training sample, employing soft weighting and threshold-based filtering to mitigate the impact of low-quality rationales.
Methodology
Trust Metrics
Self-Consistency (SC) assesses the consistency of rationales by averaging the cosine similarity between sentence embeddings of multiple rationales generated for the same input. Higher SC values indicate stable and consistent reasoning.
Class Entailment Alignment (CEA) measures the semantic coherence between the rationale and the class-specific definitions. Using LLMs, formal definitions of predicted CPC codes are generated and aligned with the rationale to ensure classification relevance.
LLM Agreement Score (LAS) provides external validation by employing an independent LLM as a verifier. This metric assesses the plausibility of reasoning-label pairs to enhance the trustworthiness evaluation beyond model-generated confidence.
The final trust score, Combined Trust Score (CTS), aggregates these metrics to modulate training contributions, ensuring reliability and robustness in patent classification.
Experimental Results
Empirical evaluations on the USPTO-2M dataset highlight the efficacy of the SFD framework:
- Comparison with Baselines: SFD exhibited superior performance across multiple metrics, achieving an F1-Micro score of 0.960 and an F1-Macro score of 0.404, outperforming conventional distillation methods [Table 1].
- Threshold-Based Filtering: Progressive thresholding substantially improved macro-F1 and subset accuracy, with optimal filtering at Ct > 0.9 yielding peak reliability [Table 2].
- Ablation Study: The study demonstrated the critical role of each trust metric, with CEA playing the most significant part in enforcing semantic coherence [Table 3].
- Correlation with Human Judgment: Trust scores correlated strongly with human assessments, particularly emphasizing CEA's domain-centric role [Table 4].
Conclusion
The SFD framework innovatively incorporates rationale quality into training processes, establishing a new paradigm for reliable patent classification. By using trust metrics to evaluate LLM-generated rationales, it enhances predictive performance and interpretability, aligning closely with human judgment in complex patent domains.
Future work aims to extend this methodology to other high-stakes domains, such as biomedical and legal texts, enhancing the generality and robustness of trust-aware learning paradigms.