- The paper introduces MemGraph, a framework that leverages memory graph traversal to extract entities and ontologies for enhanced patent matching.
- MemGraph integrates retrieval augmentation and generation guidance, achieving up to 17.68% improvement in matching accuracy and reducing model uncertainty.
- Empirical evaluations across various LLM backbones demonstrate MemGraph’s robustness and scalability for applications in intellectual property management.
Enhancing Patent Matching in LLMs via Memory Graph Traversal
Introduction
Patent matching is a central task in intellectual property management, requiring the identification of semantically similar patents to support innovation tracking, infringement prevention, and prior art search. The complexity of patent documents—characterized by hierarchical classification, domain-specific terminology, and intricate semantic relationships—poses significant challenges for automated matching systems. While LLMs have demonstrated strong capabilities in semantic understanding, their performance in patent matching is often limited by vocabulary mismatch and insufficient exploitation of hierarchical patent ontologies. The paper introduces MemGraph, a framework that augments LLM-based patent matching by traversing a memory graph derived from the LLM's parametric memory, enabling the extraction of both entities and ontologies to guide retrieval and matching.
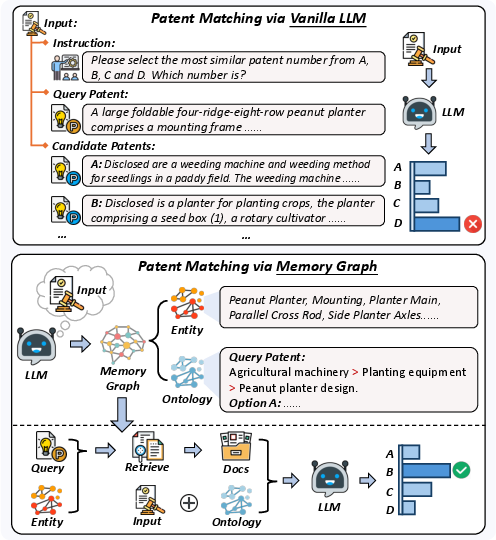
Figure 1: MemGraph integrates a memory graph into LLM-based patent matching, enabling comprehensive semantic understanding and accurate similarity assessment.
Methodology
Memory Graph Augmentation
MemGraph operates within a Retrieval-Augmented Generation (RAG) paradigm, enhancing both the retrieval and generation stages by leveraging two latent variables: ZIR (entity-based query expansion) and ZGen (ontology-based reasoning guidance). The memory graph is constructed by prompting the LLM to traverse its parametric memory, extracting:
- Entities (Ve): Specific technical concepts, components, or methods central to the patent's innovation.
- Ontologies (Vo): Hierarchical categories and relationships, typically aligned with the International Patent Classification (IPC) system.
The traversal is performed via structured prompts, enabling the LLM to autoregressively decode relevant entities and ontologies for both query and candidate patents. These extracted elements are then used to expand the query for retrieval and to guide the reasoning process during matching.
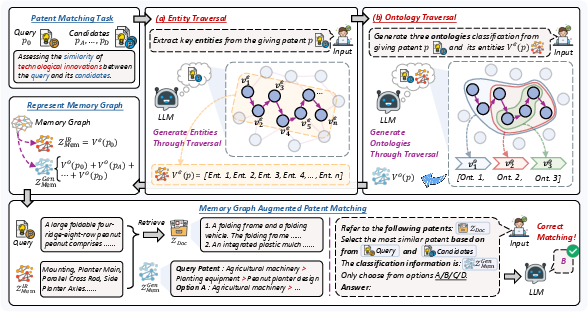
Figure 2: The MemGraph pipeline, illustrating entity and ontology extraction via memory graph traversal and their integration into retrieval and matching.
Integration with RAG
- Retrieval Enhancement: The query patent is expanded with extracted entities (ZIR), improving the relevance of retrieved documents by focusing on domain-specific terminology.
- Matching Enhancement: Ontologies (ZGen) for both query and candidate patents are incorporated into the generation context, enabling the LLM to reason over hierarchical relationships and reduce prediction uncertainty.
This dual augmentation addresses both vocabulary mismatch and semantic ambiguity, allowing the LLM to leverage both internal memory and external evidence more effectively.
Experimental Evaluation
Dataset and Baselines
Experiments are conducted on the PatentMatch dataset, comprising 1,000 patent matching questions across eight IPC sections and two languages. Baselines include vanilla LLMs, chain-of-thought (CoT) prompting, domain-specific fine-tuned LLMs (MoZi, PatentGPT), and standard RAG models.
MemGraph achieves a 17.68% improvement over baseline LLMs and a 10.85% improvement over vanilla RAG models in average accuracy. Notably, MemGraph demonstrates robust generalization across different LLM backbones (Llama-3.1-Instruct8B, Qwen2-Instruct7B, GLM-4-Chat9B, Qwen2.5-Instruct14B), outperforming larger models with smaller, well-augmented architectures.
Ablation Studies
Ablation experiments isolate the contributions of ZIR and ZGen:
- Entity-based retrieval (ZIR): Yields a 3.8% improvement over vanilla RAG, particularly in domains with specialized terminology.
- Ontology-based reasoning (ZGen): Provides a 9.2% improvement, with the largest gains in categories requiring hierarchical semantic understanding.
- Combined augmentation: Delivers the highest and most consistent performance across all IPC sections.
Utilization of Retrieved Patents
MemGraph's ontology guidance (ZGen) enables LLMs to resolve conflicts between internal memory and noisy external evidence, narrowing the performance gap in scenarios where retrieved patents are misleading. In "Miss-Choice" scenarios (where the correct patent is absent from retrieved evidence), MemGraph outperforms vanilla RAG by up to 9.3%, demonstrating superior robustness to retrieval noise.
Reasoning Process Analysis
MemGraph reduces model uncertainty (as measured by perplexity) and improves reasoning quality, with GPT-4o preferring MemGraph's chain-of-thought outputs in 61.1% of cases compared to 15.4% for vanilla LLMs and 23.5% for vanilla RAG. This indicates that memory graph traversal enhances both confidence and interpretability in patent matching decisions.
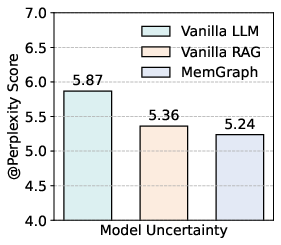
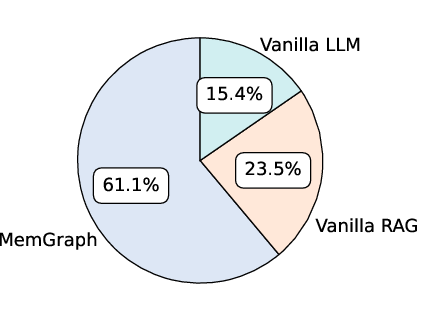
Figure 3: Evaluation results showing reduced perplexity and improved reasoning win rates for MemGraph compared to baseline models.
Case Study
A detailed case analysis reveals that MemGraph's entity and ontology extraction enables precise matching by focusing on domain-specific ingredients and hierarchical classification, whereas vanilla LLMs and RAG models are misled by procedural similarities and general terms. MemGraph's approach ensures that matching decisions are grounded in both technical detail and categorical relevance.
Implications and Future Directions
MemGraph demonstrates that explicit traversal of the LLM's parametric memory to extract entities and ontologies substantially improves patent matching performance, generalization, and reasoning quality. The framework is model-agnostic and can be integrated with various LLM architectures, suggesting broad applicability in other domains requiring hierarchical semantic understanding (e.g., legal document analysis, biomedical literature matching).
Theoretical implications include the validation of memory graph traversal as a mechanism for bridging internal and external knowledge in LLMs, mitigating vocabulary mismatch, and enhancing interpretability. Practically, MemGraph offers a scalable solution for IP management systems, reducing reliance on extensive domain-specific fine-tuning and improving robustness to retrieval noise.
Future research may explore:
- Automated construction and dynamic updating of memory graphs for evolving domains.
- Extension to multi-modal patent matching (e.g., integrating diagrams and claims).
- Application to other knowledge-intensive retrieval and matching tasks.
Conclusion
MemGraph provides a principled framework for enhancing LLM-based patent matching by traversing the memory graph to extract entities and ontologies, thereby improving retrieval relevance, reasoning quality, and robustness to noise. The approach yields strong empirical gains and offers a pathway toward more interpretable and effective AI systems for intellectual property management and other hierarchical semantic tasks.