- The paper introduces a Memory-Augmented Latent Transformer (MALT) architecture that efficiently handles long video sequences using compact memory vectors.
- It employs noise augmentation and innovative training methods to maintain consistent image quality and prevent error accumulation over extended horizons.
- Experiments demonstrate state-of-the-art performance, with an FVD score of 220.4 on UCF-101 for 128-frame video generation and robust text-to-video synthesis.
MALT Diffusion: An Advanced Framework for Video Generation
MALT Diffusion represents a noteworthy advancement in the generation of long videos using diffusion models, tackling the challenge of synthesizing videos with extended temporal horizons while maintaining image quality and consistency. The paper introduces a Memory-Augmented Latent Transformer (MALT) architecture, enhancing the capabilities of diffusion models to handle long-term video generation by efficiently utilizing memory vectors to store contextual information.
Core Contributions
Memory-Augmented Architecture
The architecture builds upon existing diffusion transformers, incorporating recurrent memory attention layers tailored to manage long video sequences. The novel aspect involves encoding previous contexts into compact memory latent vectors, enabling the model to condition its generation process on an extended temporal context without excessive computational overhead.
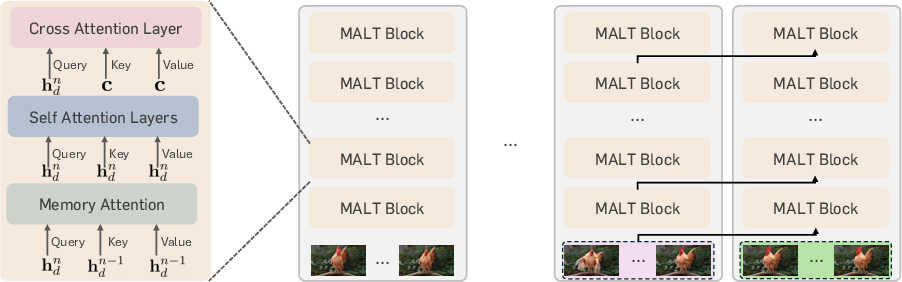
Figure 1: MALT model architecture. We add memory attention layers to the existing diffusion transformer architectures, which are operated recurrently across segments of short video clips.
Efficient Training Techniques
MALT employs innovative training techniques focusing on robustness to noisy memory vectors, enhancing the model's ability to generate consistent quality over a long horizon and preventing degradation due to error accumulation. This is achieved through noise augmentation and sophisticated objective functions designed for long-term stability.
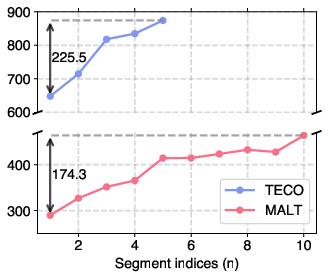
Figure 2: Error propagation analysis. FVD values on Kinetics-600 measured with a part of segments in the entire videos.
The model's efficacy is demonstrated through experiments on prominent benchmarks, yielding impressive results such as an FVD score of 220.4 on UCF-101 for 128-frame video generation, outperforming the previous state-of-the-art. Additionally, MALT showcases competence in text-to-video generation by producing stable quality videos extending beyond 2 minutes, with robust frame consistency from start to end.

Figure 3: Long video prediction results on UCF-101. Each frame has 128×128 resolution. We visualize the frames with a stride of 16.
Implications and Future Directions
The advancements proposed by MALT have significant implications in fields like autonomous driving and surveillance where long-term video consistency is crucial. Moreover, the architecture lays groundwork for future exploration into more efficient models capable of handling even longer sequences, potentially with optimizations derived from LLM methodologies to further extend context understanding.
The potential expansions could involve integrating hardware optimizations or new attention mechanisms to further refine video generation capabilities. Additionally, examining the interplay between memory compression techniques and diffusion efficiency would be a promising area to reduce computational demands while expanding generative capabilities.
Conclusion
MALT Diffusion stands as a formidable technique in video generation, significantly improving memory handling and long-term consistency in generated media. Its application not only paves the way for handling complex video synthesis tasks but also offers avenues to explore further innovations in generative models with extended temporal capabilities. The approach signifies a critical step towards achieving scalable, high-quality video synthesis across diverse application domains.