- The paper introduces a novel block-wise scanning state-space architecture to maintain extended temporal video memory in video world models.
- It integrates frame-local attention with diffusion forcing techniques to generate high-fidelity frames with consistent long-term memory.
- Experimental results on Memory Maze and Minecraft benchmarks demonstrate superior performance in PSNR, SSIM, and LPIPS while maintaining constant inference time.
Long-Term Memory in State-Space Video World Models
Introduction
The paper "Long-Context State-Space Video World Models" addresses the challenge of maintaining long-term memory in video world models, especially in the context of interactive applications where real-time, infinite-length video generation is essential. Traditional video diffusion models encounter limitations due to the high computational costs associated with processing extended sequences and short attention memory spans, leading to inconsistent environments during interactive simulations. This research proposes a novel architecture leveraging state-space models (SSMs) to overcome such limitations while ensuring computational efficiency.
Proposed Methodology
State-Space Models with Block-Wise Scanning
The core innovation in this approach is a novel architecture design exploiting SSMs through a block-wise scanning strategy. By dividing spatial dimensions into blocks of size (bh,bw,T), the model strategically balances temporal memory and spatial coherence. This method contrasts with the existing models where all temporal tokens become distant in a linear scan, affecting long-term dependencies significantly. The block-wise scanning enhances expressivity and ensures each block handles temporal sequences efficiently, preserving more extended memory with constant inference time (Figure 1).
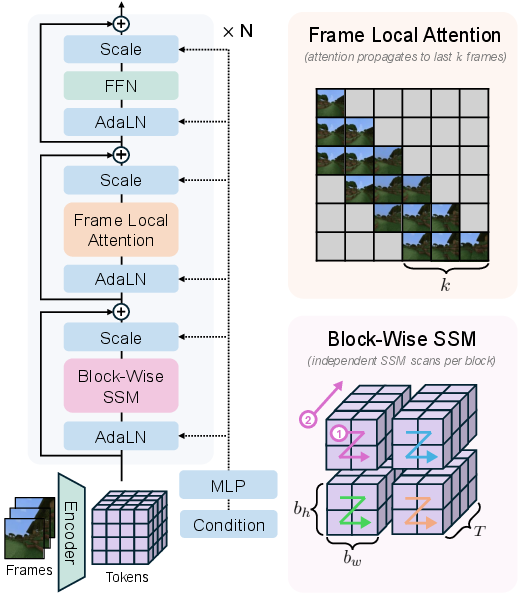
Figure 1: The architecture illustrates usage of SSM scanning in blocks, promoting extended temporal memory with spatial coherence.
Enhanced Attention Mechanisms
The study incorporates frame-local attention alongside SSMs, enabling bidirectional processing within individual frames while maintaining causal relationships across previous frames. This mixed approach helps in preserving high fidelity in frame generation and ensures temporal consistency (Figure 2).
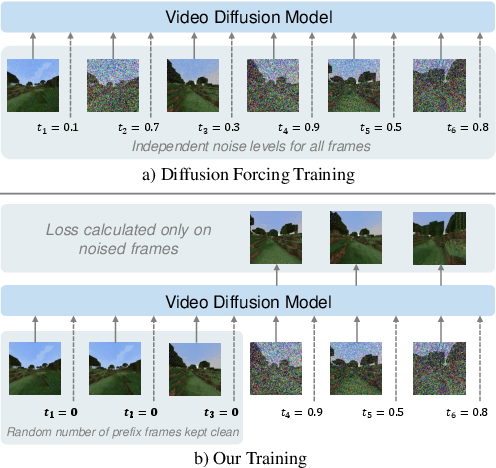
Figure 2: An illustration of the improved training mechanism. Noised frames being trained against clean context frames to leverage long-term dependencies.
Long-Context Training and Inference
The training process addresses typical shortcomings of diffusion models capturing long-term dependencies by mixing standard diffusion forcing with an innovative approach—maintaining a random-length prefix of frames as clean context ensuring exposure to diverse noise levels across frames. This method not only enhances long-context learning but provides efficient inference with consistent memory usage by maintaining a tracking state for previously generated frames.
Experimental Evaluation
Experiments conducted over the Memory Maze and Minecraft datasets demonstrate the proposed method significantly surpasses baseline models like Mamba2 and traditional causal models in terms of maintaining temporal memory and offering high fidelity to ground truth frames. The spatial retrieval task, which demands accurate trajectory backtracking, showed the model's ability to maintain long-term memory efficiently (Figures 5 and 7).
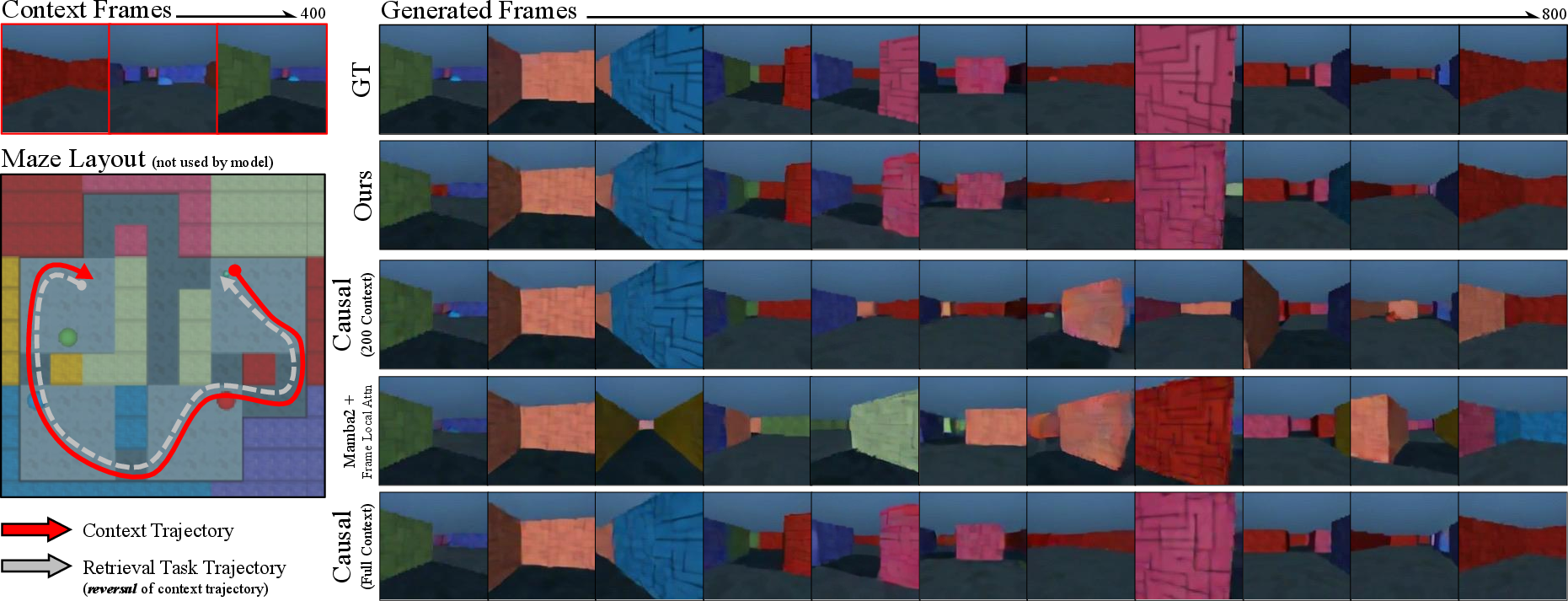
Figure 3: High fidelity to ground truth in retrieval tasks, showcasing our model's superior memory over extended frames.

Figure 4: Consistent PSNR performance over increasing frame distances, indicating the model's robust long-term memory retention compared to limited context models.
Moreover, the proposed method demonstrates efficient task solving in speciated reasoning tasks, where it outperformed limited context causal transformers and maintained high statistical similarity metrics like SSIM, LPIPS, and PSNR even across challenging trajectories.
Evaluation metrics of training and inference costs highlight the computational efficiency of the approach. By leveraging block-wise SSMs, the model achieves a balance between performance and resource consumption (Figure 5), with linear training complexity and constant inference time—the ideal scenario for interactive applications needing infinite rollouts.
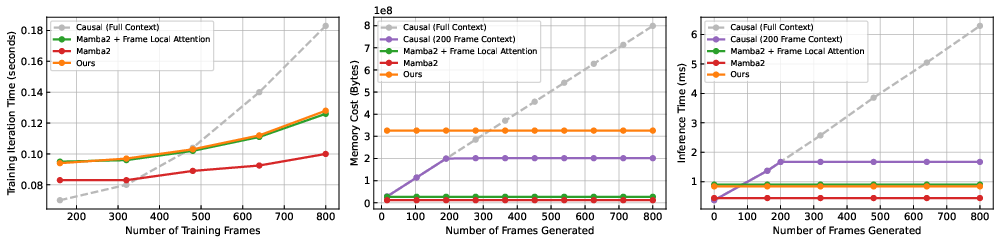
Figure 5: Our model maintains consistent memory efficiency and computational time, clearly outperforming baseline methods concerning scaling.
Conclusion
This paper proposes a robust architecture advancing the performance of video world models by effectively managing long-term memory without incurring prohibitive computational costs. By introducing block-wise SSM and enhanced diffusion forcing techniques, it offers a comprehensive solution to issues with current state-of-the-art models. Future research could focus on higher resolution video applications and further optimizations to support interactive real-time frame generation.
Ultimately, "Long-Context State-Space Video World Models" offers a novel direction in addressing the resource and memory constraints of video diffusion models, laying groundwork that could benefit applications across gaming, simulations, and other interactive media technologies.

