- The paper presents a self-aware RL framework that enables LLMs to autonomously generate and solve tasks with intrinsic feedback.
- It leverages self-aware difficulty prediction and limit-breaking to dynamically adjust task challenges based on model capabilities.
- Experimental results show up to a 77.8% improvement in reasoning tasks, achieving substantial gains with only a minimal data increase.
The Path of Self-Evolving LLMs: Achieving Data-Efficient Learning via Intrinsic Feedback
Introduction
The paper "The Path of Self-Evolving LLMs: Achieving Data-Efficient Learning via Intrinsic Feedback" (2510.02752) investigates a novel approach to enhance LLMs using reinforcement learning (RL) with minimal data constraints. The complexity and enormous data requirements for training LLMs often act as significant bottlenecks, making this research pivotal in seeking efficiency. The research introduces a paradigm where LLMs generate and solve tasks autonomously through a self-improvement loop, underpinned by self-aware mechanisms.
Self-Aware Reinforcement Learning
Self-aware reinforcement learning (RL) is introduced as an advanced mechanism to make LLMs cognizant of their intrinsic capabilities. By integrating self-awareness, the models can dynamically gauge task difficulty, prioritize tasks that best challenge their capabilities, and seek external data only when reaching intrinsic capability limits. This framework leverages two primary mechanisms:
- Self-aware Difficulty Prediction: The generator agent models the complexity of tasks and predicts the success rate of solver agents. It predicts how challenging a new task will be based on its current state, facilitating an adaptive curriculum that tailors task difficulty to align with the model’s evolving capabilities.
- Self-aware Limit Breaking: Agents are trained to recognize tasks that exceed their capabilities and can proactively seek external guidance, such as querying a stronger model, to overcome these limits. This minimizes reliance on extensive data while dramatically increasing the efficacy of external interventions.
Methodology
The methodology relies on a dual-agent framework: a generator agent creates tasks with a difficulty rating, while a solver agent attempts to solve these tasks. This loop is designed to reduce stagnation in learning by prioritizing suitably challenging tasks:
- An agent adept at self-assessment can balance task difficulty against current abilities, fostering a conducive environment for progressive learning.
- The empirical formulation of the training reward, combined with a rollout accuracy assessment, underlines the congruence between task difficulty and agent capability, allowing task difficulty to increase progressively with model competency.
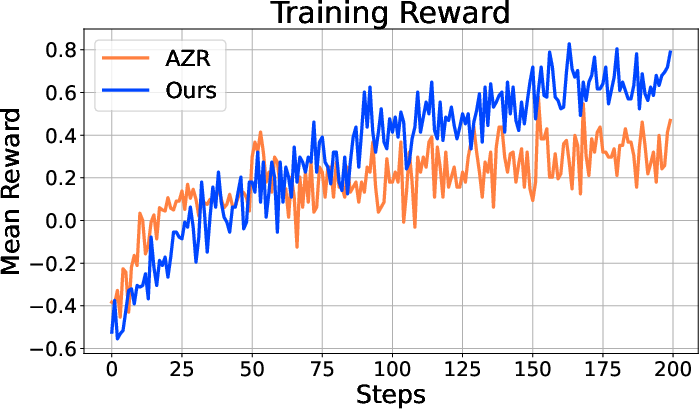
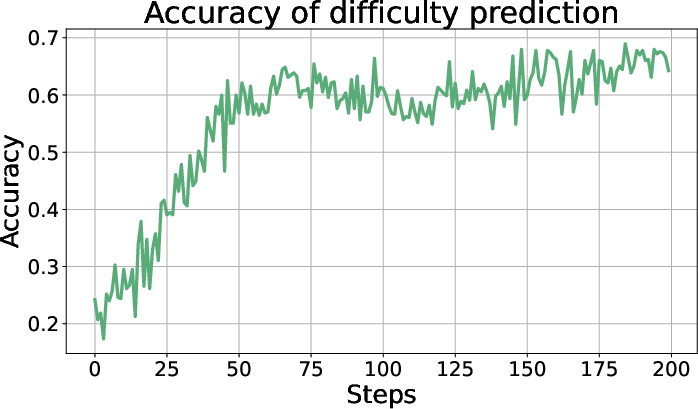
Figure 1: The training Reward of self-aware RL stably increases as the training continues. The reward is lower at the first few steps since the dialogue template is more complicated in comparison to the baseline. After the agent has been fitted to the new dialogue template, the training reward of self-aware RL quickly increases and surpasses the baseline reward.
Experimental Results
The proposed self-aware RL framework demonstrates substantial performance gains across various benchmarks, achieving an average improvement of 53.8% on mathematical reasoning tasks with only a 1.23% increase in data usage. This indicates the mechanism’s effectiveness in reducing data dependency while enhancing task-solving capabilities:
- On tasks such as MATH500 and AMC'23, improvements of 29.8% and 77.8% respectively, underscore the paradigm's robust generalization capabilities.
- Coder benchmarks also witnessed marked improvements, with notable enhancements in solving unseen or new domain problems, confirming the framework’s promising utility in data-constrained scenarios.
Discussion
The introduction of self-aware RL marks a strategic shift in model training, emphasizing intrinsic feedback over external data reliance. This approach not only enhances learning efficiency but also shifts the focus from dataset size to the quality and complexity of learning tasks. The adaptive curriculum formed through self-awareness predicates significant theoretical implications for AI, suggesting pathways to more autonomous learning systems that optimize their own training processes.
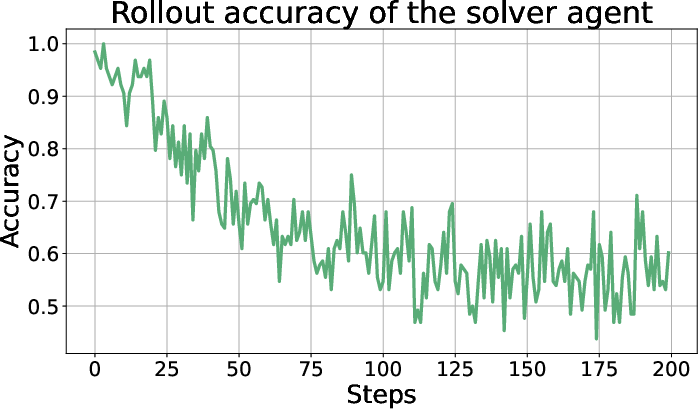
Figure 2: Accuracy of rollouts generated by the solver agent. The accuracy is initially high, reflecting that the generator did not generate challenging tasks without training. As the training continues, the difficulty of generated tasks increases and the rollout accuracy gradually decreases, was finally stabilized around 0.6.
Conclusion
The research establishes a compelling case for self-evolving agents capable of self-directed learning with minimal data interventions. By introducing self-aware RL, the study underscores the potential for LLMs to achieve substantive advancements in capability and reasoning precision without their traditional data constraints. Future research could expand upon this framework, applying it to more complex interactive environments or integrating it with other machine learning paradigmatics for enhanced cognitive and operational efficiencies.

