- The paper introduces TabImpute, which employs a pre-trained transformer for zero-shot missing-data imputation, enabling fast and accurate entry-wise predictions.
- It utilizes a synthetic data generation process to mimic realistic missingness patterns, resulting in a model that generalizes well on 42 diverse datasets.
- Benchmark results on MissBench show TabImpute outperforms 11 traditional methods, highlighting its practical impact in domains with incomplete data.
Introduction to TabImpute
This research article introduces TabImpute, a pre-trained transformer model aimed at addressing the prevalent issue of missing data in tabular datasets. The authors highlight the limitations of existing imputation methods and propose an innovative approach that leverages a tabular foundation model, TabPFN, to perform fast and accurate zero-shot imputations without requiring fitting or hyperparameter tuning during inference. The work is anchored on three key innovations: an entry-wise featurization conducive to efficient computations, a synthetic data generation process that mimics realistic missingness patterns, and a comprehensive benchmark suite, termed MissBench, for evaluating imputation methods.
Methodological Contributions
The authors contribute a novel entry-wise featurization protocol, which characteristically accelerates the imputation process by facilitating parallel predictions of missing values. This is particularly advantageous over the TabPFN's previous column-wise imputation approach, achieving a substantial computational speedup. Besides, they establish a synthetic training pipeline that generates data with diverse and realistic missingness structures, enabling the model to generalize well to various real-world scenarios.
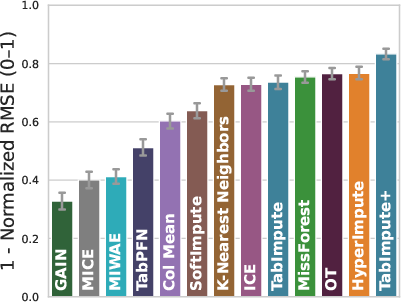
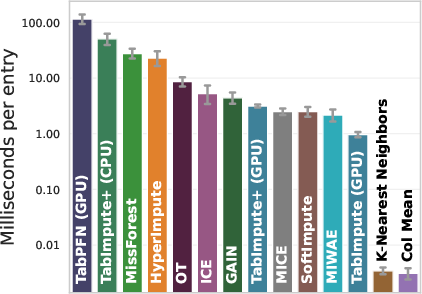
Figure 1: Evaluation on real-world OpenML data: MissBench comparing TabImpute and TabImpute+ with other methods.
The paper also introduces MissBench, a comprehensive benchmark spanning 42 OpenML datasets across different domains, implemented with 13 nuanced missingness patterns. This benchmark demonstrates TabImpute's competitive edge over 11 established imputation techniques, supported by results reflecting its superior imputation accuracy and efficiency.




Figure 2: Synthetic missingness patterns implemented in MissBench showcasing varied observed and unobserved data.
Theoretical and Practical Implications
From a theoretical standpoint, TabImpute represents a significant shift towards generalized tabular data solutions using the transformer architecture typically reserved for sequential and text data. The implication here is twofold: it underscores the transformative potential of deep learning in tabular data processing, and it opens avenues for exploring advanced attention-based architectures in this domain.
On the practical front, the model's zero-shot capability implies that it can be seamlessly deployed in heterogeneous environments without necessitating costly retraining or parameter adjustments. This is especially impactful in domains where data incompleteness is rampant—such as healthcare, economics, and engineering—facilitating more reliable machine learning model training and inference.
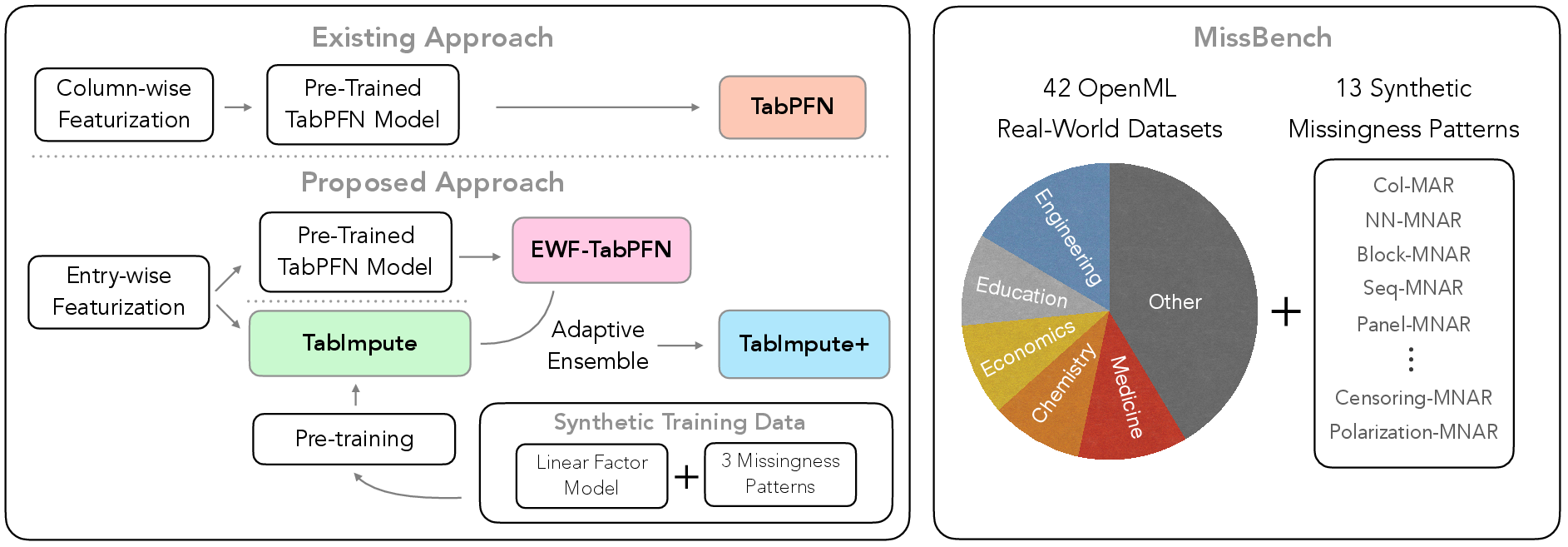
Figure 3: Overview of the contributions, highlighting the model architecture and benchmark evaluation process.
Future Developments and Directions
The future trajectory for TabImpute and its framework is robust. Further developments could involve enhancing the model to handle categorical data and scaling the architecture to accommodate larger datasets, acknowledging the current computational challenges highlighted by the authors. Additionally, there exists potential in leveraging TabImpute for causal inference settings, treating such applications as missing-data problems.
Given the model's underlying architecture similarity with TabPFN, improvements to the latter will likely benefit TabImpute directly. Innovations in neural attention mechanisms, scalability, and foundational models for tabular data, such as those introduced in recent works like TabICL and TabFlex, could offer immediate architectural enhancements to TabImpute.
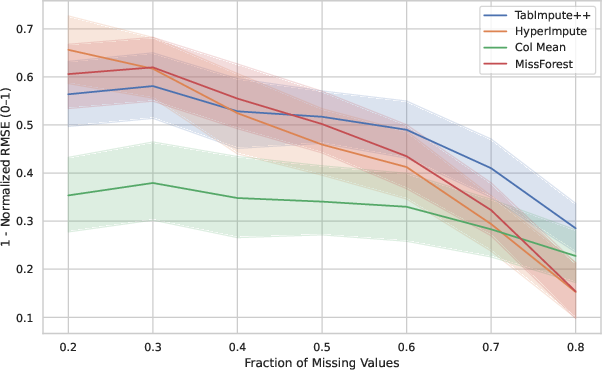
Figure 4: Imputation accuracy versus fraction of missingness for MCAR showing TabImpute+'s optimal performance.
Conclusion
TabImpute stands as a robust solution to missing data imputation in tabular datasets. This work not only bridges the gap in existing imputation methodologies but also sets the stage for future advancements in tabular foundation models. By integrating broader architectural improvements and extending its application scope, TabImpute has the potential to redefine data handling and preparation in various scientific and business contexts. The open dissemination of the model's code and weights, as described by the authors, invites the academic community to explore and extend the potential of this transformative approach further.

