- The paper introduces MTabGen, a novel diffusion model that unifies imputation and synthetic data generation for tabular datasets.
- It employs dual diffusion processes and a transformer encoder-decoder with conditioning attention to capture complex inter-feature dependencies.
- Experimental results highlight enhanced ML efficiency, improved statistical similarity, and robust privacy risk mitigation across diverse datasets.
Diffusion Models for Tabular Data Imputation and Synthetic Data Generation
Introduction and Motivation
The paper presents MTabGen, a novel diffusion model architecture for tabular data imputation and synthetic data generation. The motivation stems from the limitations of existing generative models—GANs, VAEs, and prior diffusion models—when applied to tabular data, especially in scenarios with mixed feature types, high dimensionality, and privacy constraints. MTabGen introduces three principal innovations: a conditioning attention mechanism, a transformer-based encoder-decoder denoising network, and dynamic masking. These components enable the model to flexibly handle both missing data imputation and synthetic data generation within a unified framework, while maintaining strong performance across diverse datasets.
Model Architecture and Methodology
MTabGen builds upon the TabDDPM framework, extending it with several key enhancements:
- Dual Diffusion Processes: Separate Gaussian and multinomial diffusion processes are used for continuous and categorical features, respectively, preserving feature-specific statistical properties throughout the forward and reverse diffusion steps.
- Transformer Encoder-Decoder Denoising Network: The denoising network is implemented as a transformer encoder-decoder. The encoder processes conditioning features (unmasked and/or target variables), while the decoder attends to both masked and conditioning features, leveraging cross-attention to model complex inter-feature dependencies.
- Conditioning Attention Mechanism: Unlike previous approaches that concatenate or sum condition and feature embeddings, MTabGen uses the encoder output as keys and values in the decoder’s attention mechanism, with masked feature embeddings as queries. This design enables the model to learn richer conditional relationships and reduces learning bias.
- Dynamic Masking: During training, the split between masked and conditioning features is randomized per sample, allowing the model to generalize to arbitrary imputation and generation tasks. The masking mechanism is further extended to handle missing values natively, obviating the need for preprocessing.
(Figure 1)
Figure 1: Comparison between distribution of real and synthetic data. The two top rows present four examples of numerical columns from various datasets in our benchmark, while the two bottom rows contain examples of categorical features.
(Figure 2)
Figure 2: L2 distance between correlation matrices computed on real and synthetic data. More intense green color means higher difference between the real and synthetic correlation values.
Experimental Evaluation
Datasets and Baselines
The evaluation spans ten public tabular datasets, covering binary/multiclass classification and regression tasks, with varying numbers of numerical and categorical features. Baselines include TabDDPM, Tabsyn, CoDi, TVAE, CTGAN for generation, and missForest, GAIN, HyperImpute, Miracle, TabCSDI for imputation.
Metrics
Three axes of evaluation are used:
- ML Efficiency: Performance of discriminative models (XGBoost, CatBoost, LightGBM, MLP) trained on synthetic data and tested on real data.
- Statistical Similarity: Wasserstein and Jensen-Shannon distances for feature distributions, and L2 distance between correlation matrices.
- Privacy Risk: Distance to Closest Record (DCR) between synthetic and real samples.
Results
- Synthetic Data Generation: MTabGen consistently outperforms all baselines in ML efficiency, especially on high-dimensional datasets. The transformer-based architecture and conditioning attention mechanism yield substantial gains over TabDDPM and Tabsyn.
- Missing Data Imputation: MTabGen achieves superior imputation accuracy across all missingness levels (10%, 25%, 40%), with performance advantages increasing as the proportion of missing data grows.
- Statistical Similarity: MTabGen’s synthetic data exhibits lower Wasserstein and Jensen-Shannon distances to real data, and better preservation of feature correlations, as evidenced by lighter heatmaps in L2 correlation distance plots.
(Figure 3)
Figure 3: Distance to Closest Record (DCR) for Tabsyn and MTabGen
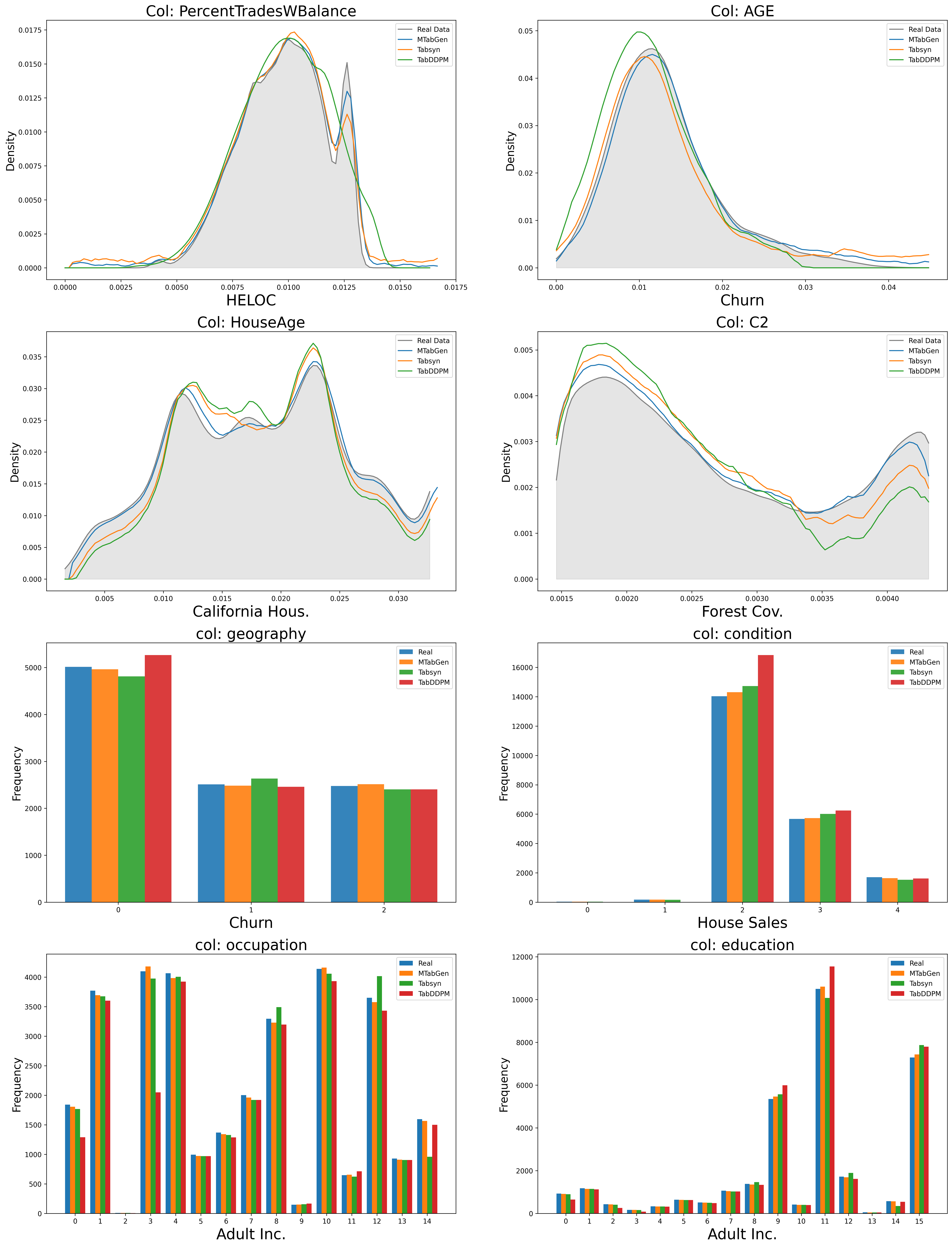
Figure 4: Distance to Closest Record (DCR) for TabDDPM and MTabGen
- Privacy Risk: When ML efficiency improvements are marginal (<5%), DCR values are similar across models, indicating no increased privacy risk. For datasets where MTabGen achieves much higher ML efficiency, DCR is lower, reflecting closer statistical fidelity to real data. The framework supports integration of differential privacy mechanisms to further mitigate privacy concerns.
Ablation and Architectural Analysis
Ablation studies demonstrate that replacing TabDDPM’s MLP denoising network with a transformer encoder improves performance, but the full encoder-decoder with conditioning attention yields the best results. Dynamic conditioning enables multi-tasking (generation, imputation, prompted generation) without loss of performance, enhancing model usability in practical deployments.
Implementation Considerations
- Computational Requirements: Transformer-based denoising networks incur higher computational cost and memory usage compared to MLPs, especially for large tabular datasets. Efficient batching and mixed-precision training are recommended.
- Scalability: The architecture scales well to high-dimensional data, outperforming baselines in such regimes. However, for extremely wide tables, attention mechanisms may require optimization (e.g., sparse attention).
- Deployment: The unified framework for imputation and generation simplifies deployment in production systems, supporting both privacy-preserving synthetic data sharing and robust handling of missing data.
Implications and Future Directions
MTabGen advances the state-of-the-art in tabular data modeling by bridging the gap between generative modeling and practical data management needs. Its unified approach to imputation and generation, combined with strong statistical fidelity and privacy controls, makes it suitable for regulated domains such as healthcare and finance. Future work may explore:
Conclusion
MTabGen introduces a robust, flexible, and high-performing framework for tabular data imputation and synthetic data generation. Its transformer-based encoder-decoder architecture with conditioning attention and dynamic masking sets a new benchmark for generative modeling in tabular domains, achieving superior ML efficiency, statistical similarity, and privacy risk mitigation across diverse datasets. The model’s versatility and extensibility position it as a foundational tool for privacy-preserving data science and AI applications in real-world settings.