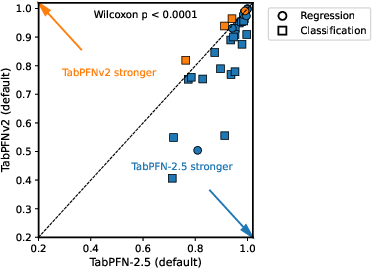
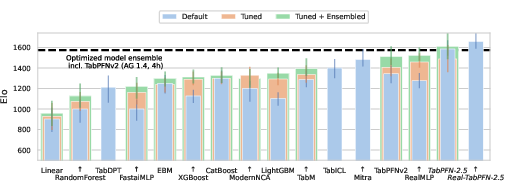
- The paper introduces TabPFN-2.5, demonstrating significant scalability and accuracy improvements for tabular data with up to 50,000 samples and 2,000 features.
- It leverages advanced architectural updates, including deeper network layers and a distillation engine, to boost training speed and inference efficiency.
- Performance evaluations on the TabArena-lite benchmark show that TabPFN-2.5 consistently outperforms models like AutoGluon and XGBoost while reducing the need for hyperparameter tuning.
TabPFN-2.5: Advancing Tabular Foundation Models
Introduction
The paper "TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models" (2511.08667) introduces TabPFN-2.5, the next iteration in the series of Tabular Foundation Models (TFMs) with a significant leap in capability. Established on the footing of the previous models, TabPFN and TabPFNv2, TabPFN-2.5 extends the model's ability to handle datasets of up to 50,000 samples and 2,000 features, with a focus on outperforming established models such as AutoGluon and XGBoost.
TabPFN-2.5 underscores considerable uptakes in scalability, speed, and accuracy, further promoting TFMs as viable competitors to classical models in various tabular data applications, including large-scale machine learning tasks. This model eliminates the extensive hyperparameter tuning requirement typical of models like gradient-boosted trees, thanks to a pre-training phase on synthetically generated data, which engenders robust, out-of-the-box performance.
Technological Advancements
TabPFN-2.5 capitalizes on several architectural and methodological advancements:
TabPFN-2.5 is subjected to a rigorous evaluation on the TabArena-lite benchmark, which encompasses challenging datasets with up to 100,000 samples. The new model demonstrates a substantial edge not only over previous iterations but also over contemporaries like AutoGluon and XGBoost:
Practical Implications
TabPFN-2.5's practical import indicates its readiness for integration into high-stakes, data-intensive environments. With its ability to deliver fast, accurate predictions on substantial datasets without dependence on exhaustive tuning, it stands poised to redefine baseline expectations for tabular data processing. The model's implications reach across domains—ranging from healthcare for diagnostic support, to financial services for risk assessment, manifesting strong multi-domain adaptability.
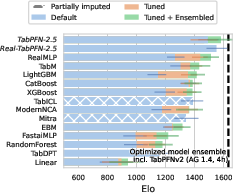
Figure 3: TabArena-Lite results on diverse datasets demonstrating the model's robust performance across various scales.
Future Directions
The advancements in TabPFN-2.5 illuminate potential avenues for exploration. Enhancing dataset capacity towards models that can handle millions of rows remains a critical milestone. Furthermore, integrating domain-specific adaptabilities, such as time-series analysis and more refined multimodal data processing, previews a promising trajectory in the evolution of TFMs.
Conclusion
TabPFN-2.5 capably advances the state of tabular foundation models, providing sophisticated solutions to prevalent challenges in tabular machine learning. Its release not only boosts performance in existing deployments but also sets a course for future iterations to further stretch the limits of scale and application versatility. The developments encapsulated in TabPFN-2.5 underscore a decisive step toward next-generation AI tools that adeptly bridge research with real-world demands.