- The paper introduces the GTA metric to quantify alignment between an agent's chain-of-thought and its executed actions.
- It presents a four-quadrant diagnostic framework combining GTA and Exact Match metrics for detailed error analysis across varied datasets.
- Results indicate that while scaling improves performance, significant reasoning-execution gaps persist, particularly in out-of-distribution scenarios.
Diagnosing Reasoning-Execution Gaps in VLM-Powered Mobile-Use Agents
Introduction
The paper "Say One Thing, Do Another? Diagnosing Reasoning-Execution Gaps in VLM-Powered Mobile-Use Agents" (2510.02204) presents a systematic framework for evaluating the alignment between reasoning and execution in mobile-use agents powered by vision-LLMs (VLMs). While prior work has focused primarily on execution accuracy, this study introduces the Ground-Truth Alignment (GTA) metric to assess whether the chain-of-thought (CoT) reasoning produced by an agent actually supports the correct action. By combining GTA with the standard Exact Match (EM) metric, the authors reveal and quantify reasoning-execution gaps, providing a more nuanced understanding of agent reliability and faithfulness.
Evaluation Framework and Metrics
The core contribution is the GTA metric, which measures whether the action implied by the agent's CoT matches the ground-truth action. This is formalized as:
GTAn=1{f(cn)=an∗}
where cn is the CoT at step n, f(cn) is the action inferred from the CoT, and an∗ is the ground-truth action. EM is defined analogously for execution accuracy:
EMn=1{an=an∗}
The joint use of GTA and EM enables a four-quadrant diagnostic framework:
- Ideal: Both reasoning and execution are correct.
- Execution Gap (EG): Reasoning is correct, but execution fails.
- Reasoning Gap (RG): Execution is correct, but reasoning is inconsistent.
- Both Wrong: Both reasoning and execution are incorrect.
This framework allows for fine-grained error analysis and exposes failure modes that are invisible to execution-only metrics.
Dataset Sampling and Annotation Reliability
To ensure robust evaluation, the authors employ stratified sampling across three benchmarks (AITZ, CAGUI, AndroidControl), preserving action type distributions and minority cases.
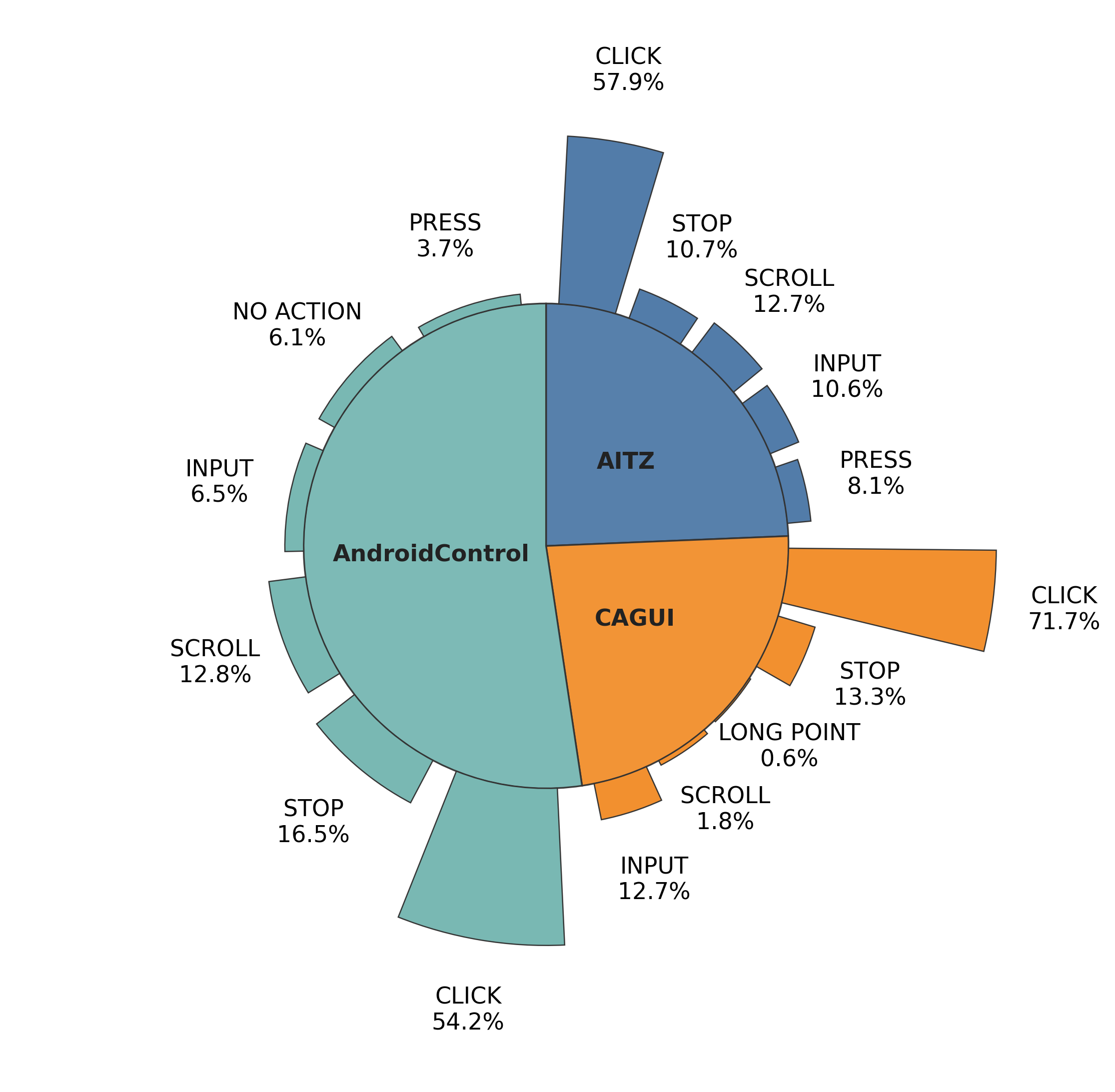
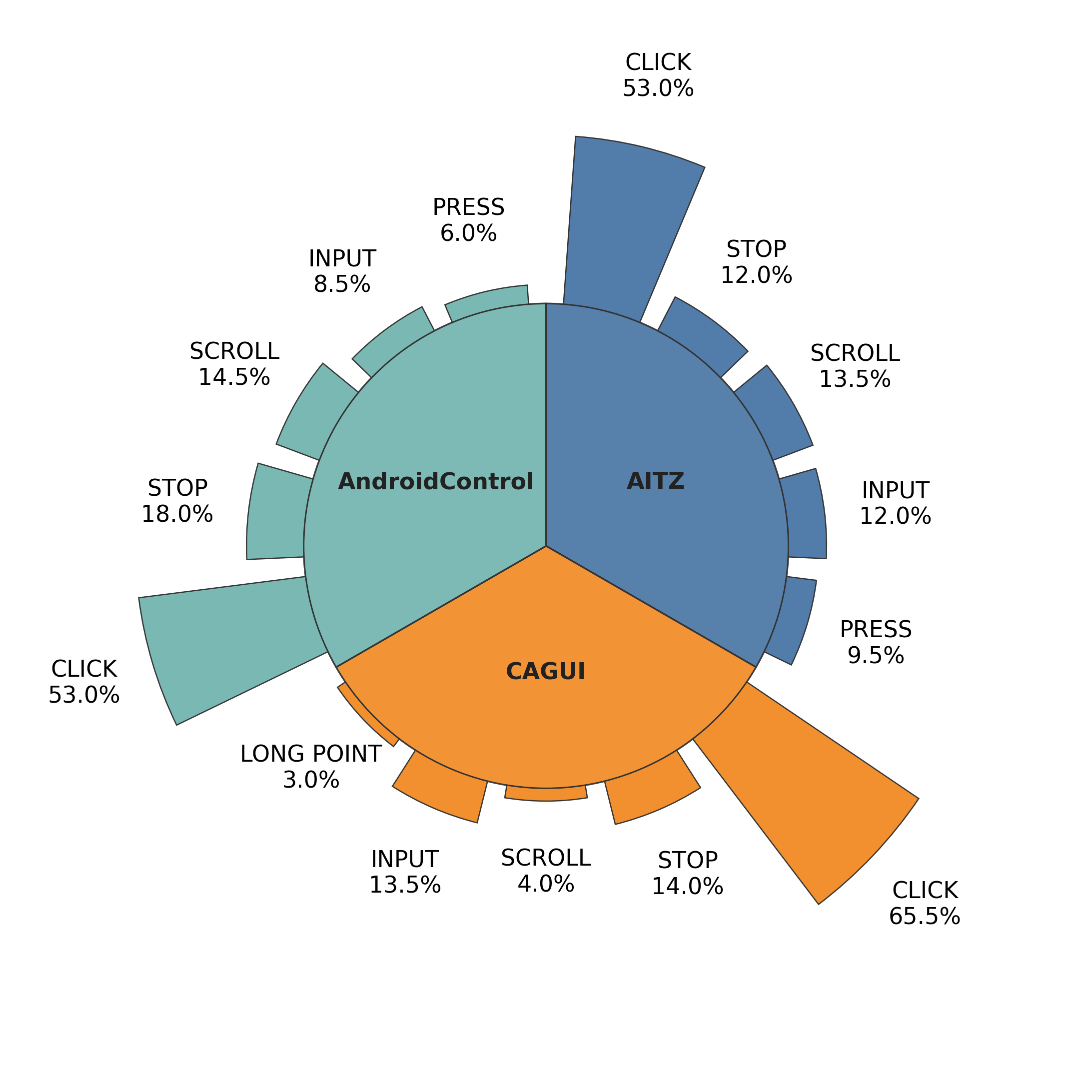
Figure 1: Action distributions of the original datasets and the stratified sampled subset, demonstrating preservation of overall action diversity for reliable annotation.
A subset of 1,800 instances is manually annotated to validate the reliability of the automatic GTA evaluator. The evaluator, based on AgentCPM-GUI-8B, achieves high agreement with human labels, with accuracy peaking on AndroidControl and slightly lower on CAGUI and AITZ.

Figure 2: Radar plots showing consistently high GTA evaluator accuracy across models and datasets, with minor dataset-specific variation.
The study evaluates six state-of-the-art mobile-use agents, including AgentCPM-GUI, UI-TARS, and GUI-Owl, across the three benchmarks. Both EM and GTA scores are reported, and their divergence is analyzed.
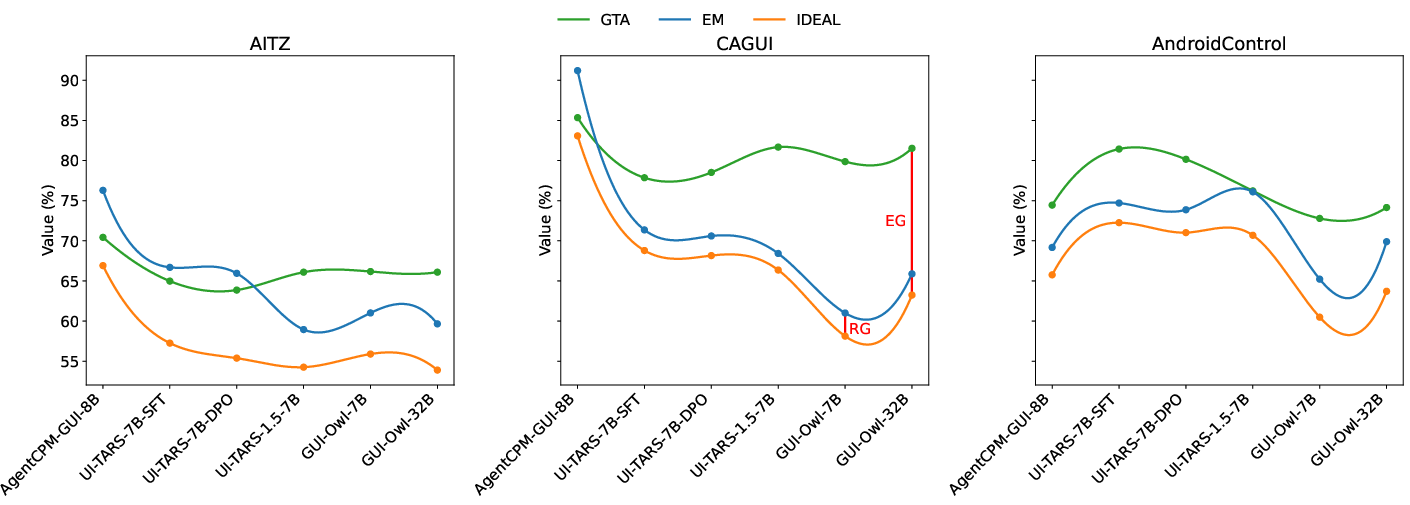
Figure 3: Spline plots of GTA, EM, and IDEAL, illustrating the relationship between reasoning and execution accuracy and the prevalence of execution gaps.
Key findings include:
- Execution gaps (EG) are more prevalent than reasoning gaps (RG) in most scenarios, indicating that agents often reason correctly but fail to translate reasoning into precise actions.
- Causal CoT models may exhibit RG > EG when overfitting to action shortcuts during supervised fine-tuning, especially on datasets with inconsistent CoTs.
- Out-of-distribution (OOD) data accentuate grounding challenges, with untrained models showing high GTA but large EG, highlighting difficulties in mapping reasoning to unfamiliar GUIs.
Parameter Scaling Effects
The impact of model scaling is systematically studied using UI-TARS models of varying sizes (2B, 7B, 72B) and training paradigms (SFT, DPO) on AndroidControl.
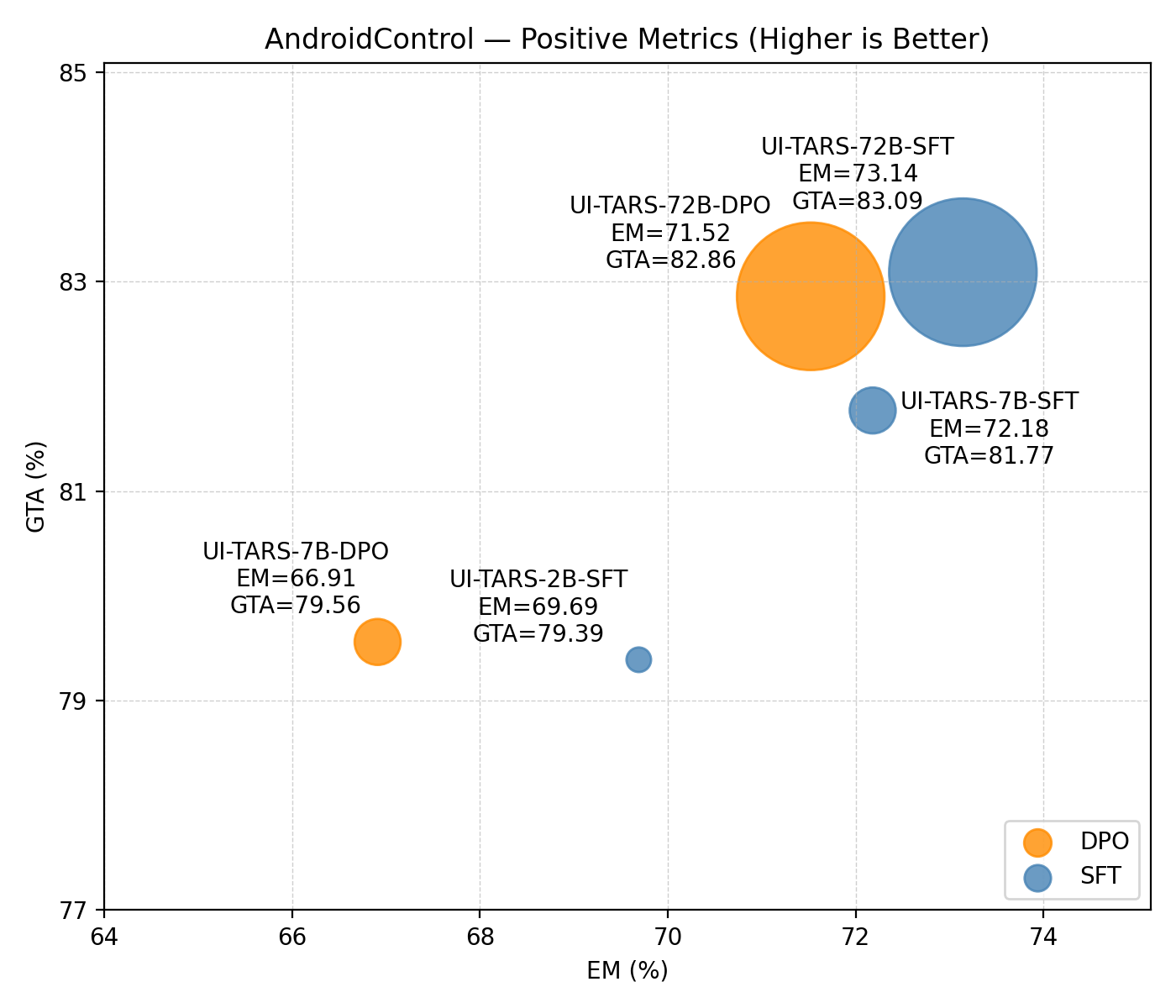
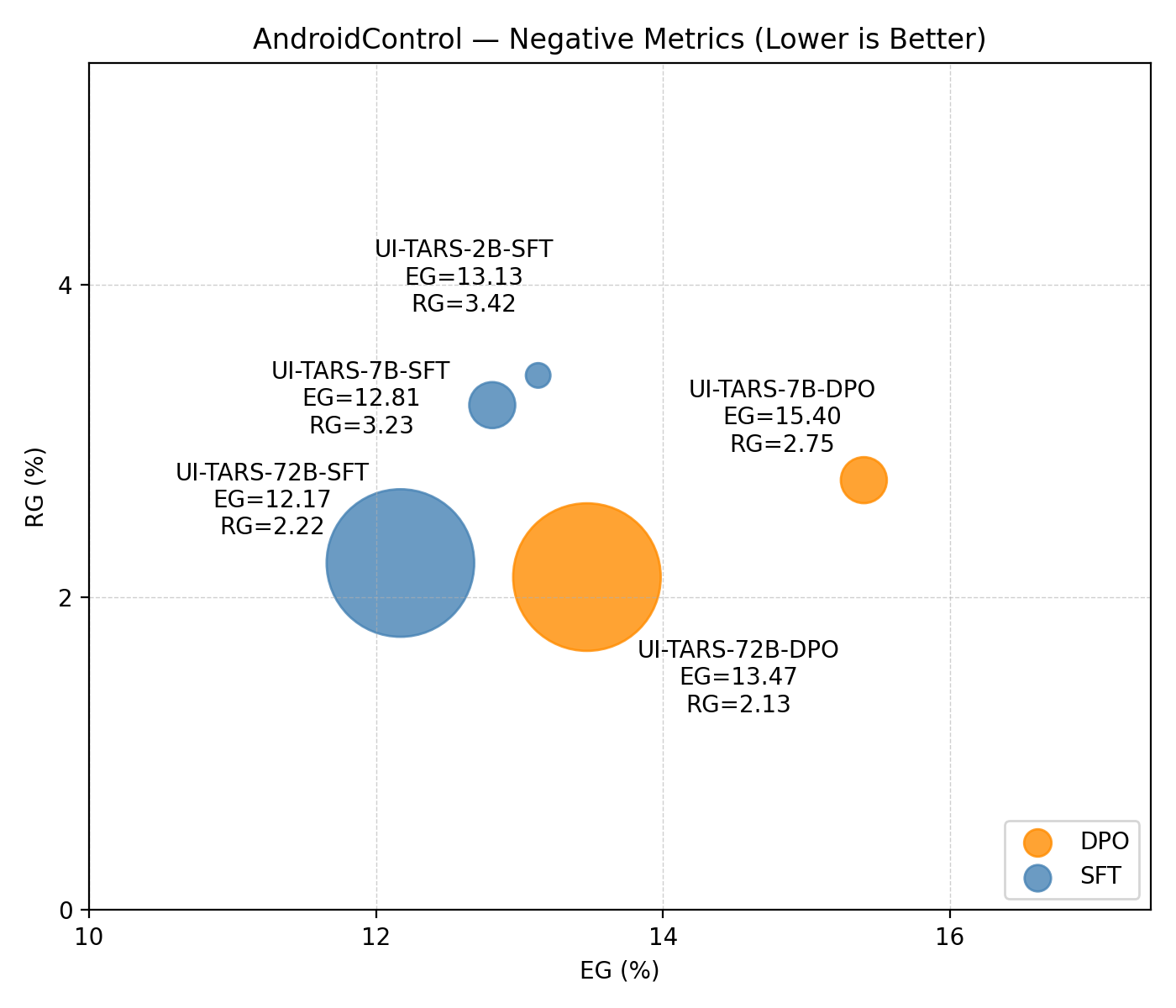
Figure 4: Positive metrics (EM, GTA) and negative metrics (EG, RG) as a function of model scale, showing that scaling improves alignment but does not eliminate execution gaps.
Scaling consistently improves both reasoning and execution accuracy while reducing EG and RG. However, even the largest models retain execution gaps above 10%, indicating that scaling alone is insufficient for full alignment.
Qualitative Case Studies
Representative examples illustrate all four quadrants of the diagnostic framework:
Figure 5: Case study of a Both Right (Ideal) example, where reasoning and execution are both correct.
Figure 6: Case study of a Both Wrong example, with both reasoning and execution failing.

Figure 7: Case study of an Execution Gap example, where reasoning is correct but execution fails.

Figure 8: Case study of a Reasoning Gap example, with correct execution but inconsistent reasoning.
These cases highlight the practical implications of reasoning-execution gaps, including risks of over-trust and challenges in debugging agent behavior.
Implications and Future Directions
The introduction of GTA and the four-quadrant diagnostic framework provides a principled approach to evaluating agent faithfulness and reliability. The findings demonstrate that reasoning-execution gaps are widespread and persist even in large, state-of-the-art models. This has significant implications for the deployment of mobile-use agents in safety-critical and user-facing applications, where over-trust in plausible but misaligned reasoning can lead to harmful outcomes.
Future research should focus on:
- Architectural innovations and training strategies that directly target reasoning-action consistency, beyond mere scaling.
- Robust grounding mechanisms to improve reasoning-to-execution mapping, especially in OOD scenarios.
- Automated and scalable evaluation protocols for reasoning-faithfulness, leveraging reliable evaluators like GTA.
Conclusion
This work advances the evaluation of VLM-powered mobile-use agents by disentangling reasoning and execution accuracy. The GTA metric and four-quadrant framework reveal prevalent reasoning-execution gaps, with execution gaps dominating even in strong models. While scaling reduces misalignment, persistent gaps indicate the need for targeted solutions. The framework sets a new standard for transparent and trustworthy assessment of agent reliability, with broad implications for the development and deployment of mobile-use agents.