- The paper demonstrates that EdgeLoRA streamlines multi-tenant LLM serving on edge devices by integrating adaptive adapter selection, heterogeneous memory management, and batch LoRA inference.
- It achieves up to 4× throughput improvements and reduced latency, validating its efficacy in resource-constrained scenarios.
- Its design supports thousands of adapters simultaneously while optimizing energy consumption for scalable edge deployments.
EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices
The paper "EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices" proposes a system designed to address the challenges of deploying LLMs with Low-Rank Adaptation (LoRA) on resource-constrained edge devices. By integrating three main innovations — adaptive adapter selection, heterogeneous memory management, and batch LoRA inference — the proposed system significantly boosts performance, achieving substantial improvements in latency, throughput, and scalability.
Introduction
EdgeLoRA\ is designed to efficiently serve LLMs with multiple LoRA adapters in multi-tenant edge environments, a setting where computational resources are limited. The paper identifies critical challenges such as the complexity of selecting appropriate adapters for various tasks, excessive memory overhead due to frequent adapter swaps, and underutilization of computational resources due to sequential request processing.
The system combines several innovations:
- Adaptive Adapter Selection: Automatically identifies and deploys optimal adapters based on request-specific requirements.
- Heterogeneous Memory Management: Utilizes intelligent caching and pooling techniques to reduce memory operation overhead.
- Batch LoRA Inference: Enables efficient batch processing to significantly reduce computational latency and improve resource utilization.
Overall, EdgeLoRA\ addresses the distinct needs of serving LLMs on edge devices by effectively managing adapters and optimizing inference processes.
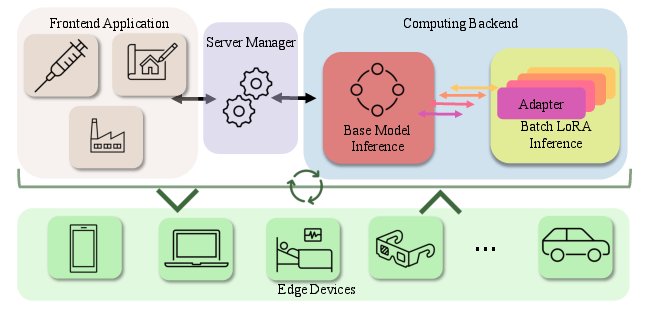
Figure 1: Multi-tenant LLM Serving on Edge Devices.
System Design
Adaptive Adapter Selection
The adaptive adapter selection component is crucial for optimizing the process of choosing the most suitable LoRA adapter for incoming requests. This mechanism analyzes incoming prompts and selects adapters based on the availability and suitability, leveraging a profiling-based method to train an adapter router. The router scores each adapter's performance, automatically selecting high-performing adapters already present in memory, thereby minimizing latency and manual intervention.
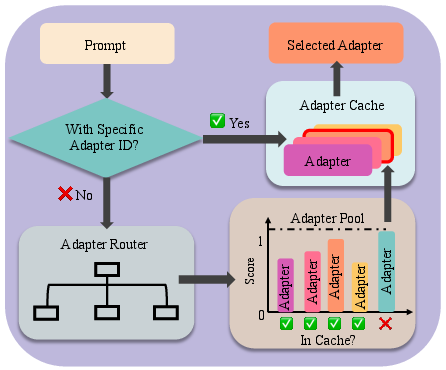
Figure 2: The workflow of adaptive adapter selection.
Heterogeneous Memory Management
Heterogeneous memory management combines both memory caching techniques and pre-allocated memory pools to maximize efficiency and minimize runtime memory allocation overhead. By employing an LRU policy within the memory cache, frequently accessed adapters are kept in memory, optimizing resource utilization under dynamic workloads.
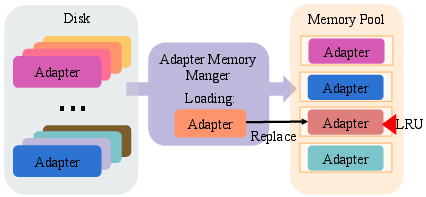
Figure 3: The adapter memory manager evicts the least frequently used adapter and loads the newly required one into a free memory block in the pool.
Batch LoRA Inference
Batch LoRA inference is designed to improve computational efficiency in multi-tenant environments by processing multiple requests in a single batch. This approach fully utilizes the parallelism of modern GPU hardware, reducing per-request latency and enhancing throughput. Different requests with diverse adapters are batched together, allowing for simultaneous computation of the pre-trained weights and LoRA-specific weights.
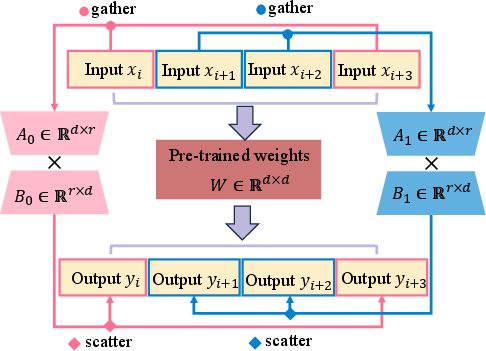
Figure 4: Batch LoRA inference.
Implementation and Evaluation
EdgeLoRA\ was implemented with extensive modifications to the llama.cpp framework, comprising intricate C++ code for efficient handling of multi-adapter workloads. Evaluation was conducted across diverse edge devices, establishing EdgeLoRA's superiority in throughput, latency, and energy efficiency compared to existing solutions.
EdgeLoRA\ demonstrated remarkable scalability, supporting thousands of adapters simultaneously while achieving throughput improvements of up to 4× over conventional methods. These results underscore the system's efficacy in adapting to large-scale edge deployments.
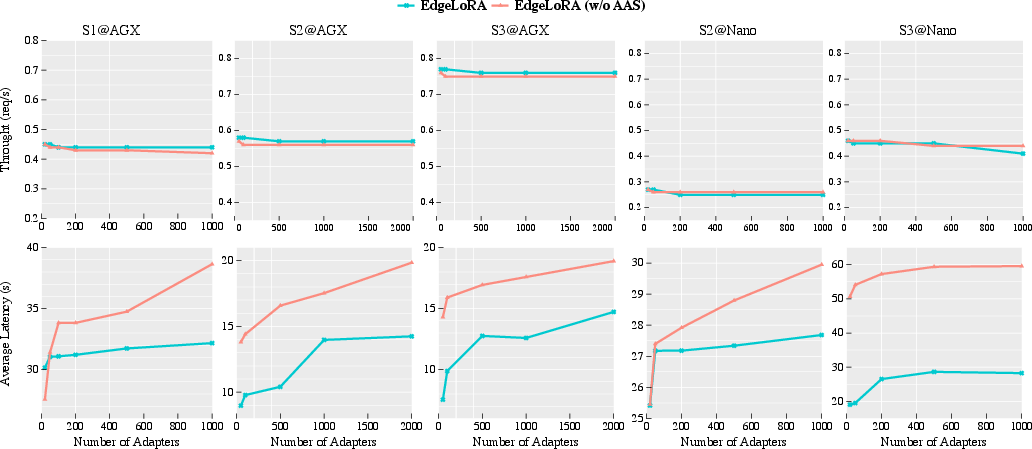
Figure 5: Throughput and average request latency of EdgeLoRA\ and EdgeLoRA\ (w/o AAS) under varying numbers of adapters. Both demonstrate scalability to a large number of adapters with similar throughput.
Conclusion
EdgeLoRA\ offers a robust solution for efficiently serving LoRA-adapted LLMs on edge devices, addressing challenges of adapter selection, memory management, and inference efficiency. The system achieves significant enhancements in throughput and energy consumption, poised to transform LLM deployment in resource-constrained settings. Future developments may focus on extending EdgeLoRA\ capabilities to further enhance adaptability and efficiency in broader edge computing scenarios.