Less is More: Lean yet Powerful Vision-Language Model for Autonomous Driving
Abstract: In this work, we reconceptualize autonomous driving as a generalized language and formulate the trajectory planning task as next waypoint prediction. We introduce Max-V1, a novel framework for one-stage end-to-end autonomous driving. Our framework presents a single-pass generation paradigm that aligns with the inherent sequentiality of driving. This approach leverages the generative capacity of the VLM (Vision-LLM) to enable end-to-end trajectory prediction directly from front-view camera input. The efficacy of this method is underpinned by a principled supervision strategy derived from statistical modeling. This provides a well-defined learning objective, which makes the framework highly amenable to master complex driving policies through imitation learning from large-scale expert demonstrations. Empirically, our method achieves the state-of-the-art performance on the nuScenes dataset, delivers an overall improvement of over 30% compared to prior baselines. Furthermore, it exhibits superior generalization performance on cross-domain datasets acquired from diverse vehicles, demonstrating notable potential for cross-vehicle robustness and adaptability. Due to these empirical strengths, this work introduces a model enabling fundamental driving behaviors, laying the foundation for the development of more capable self-driving agents. Code will be available upon publication.






























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
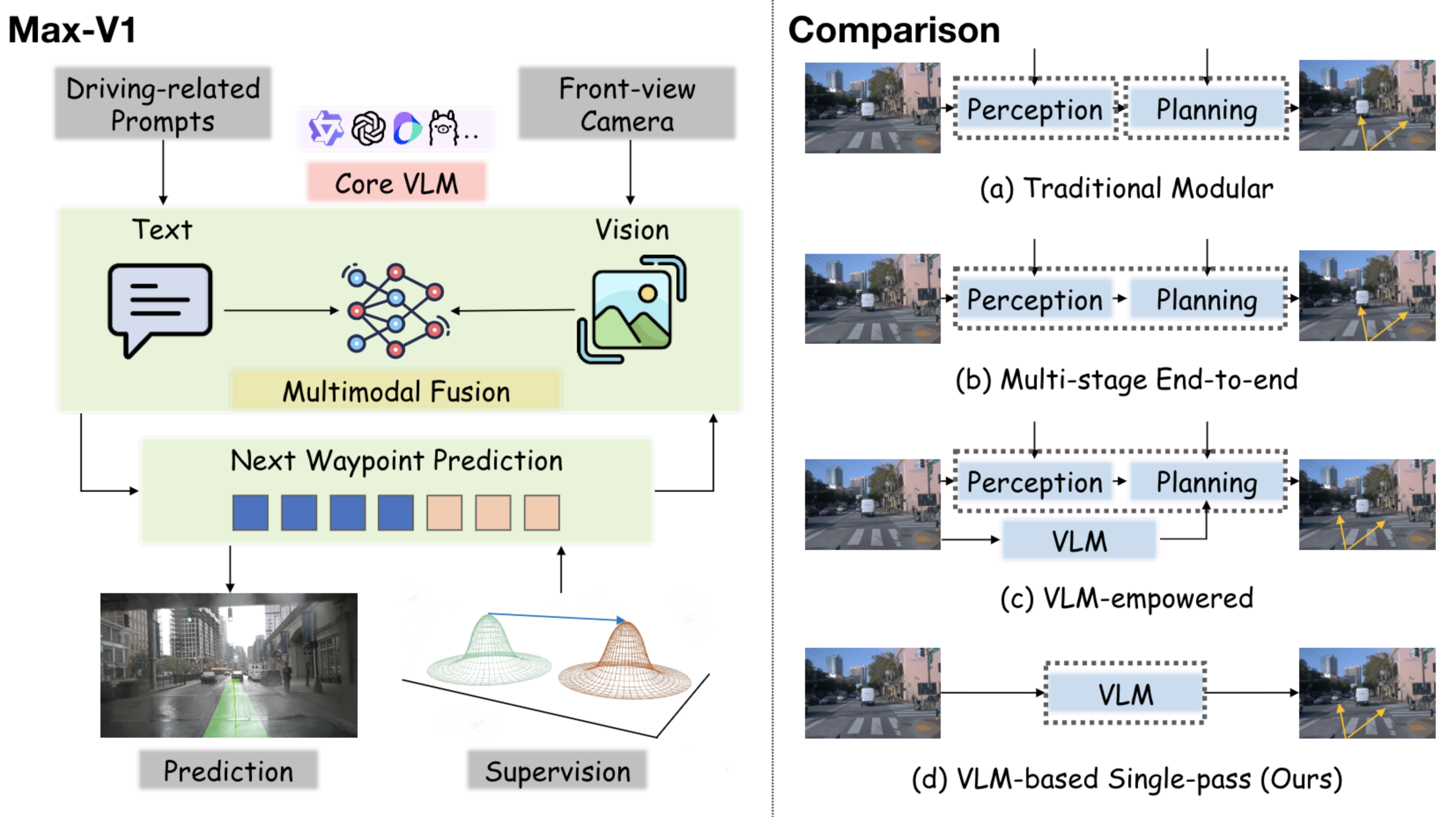
This paper introduces a new way to teach an AI to drive a car by treating driving like writing a sentence. Instead of choosing the “next word,” the AI chooses the “next point” the car should move toward. The authors build a lean, simple system called Max‑V1 that looks at a front camera image and directly “writes” a sequence of small steps (called waypoints) that form the car’s future path. They show this approach beats other methods on a popular driving dataset and works well across different cars and places.
Objectives
The paper aims to answer these questions in plain terms:
- Can a vision‑LLM (an AI that understands images and text) be fine‑tuned to plan a car’s path directly, without complicated extra steps?
- Is it better to predict the car’s next positions as precise numbers (coordinates), rather than as text?
- Will this simpler, “one pass” method still be accurate and generalize (work well) on different vehicles and in different locations?
Methods and Approach
The core idea is to treat driving like a step‑by‑step story:
- Autoregressive prediction: The model predicts the next waypoint based on what it has already predicted, much like writing the next word based on the previous words.
- Waypoints as numbers, not words: Each waypoint is a pair of numbers (x, y) telling how far ahead and to the side the car should go in a local map around the car (first‑person view). Think of it like dropping GPS “breadcrumbs” the car will follow.
- A distance‑based learning signal: When the model predicts a waypoint, the training score is how far it is from the correct point (physical distance). This is like grading the model by how many centimeters off it was, rather than whether it guessed the “right label.”
- Single‑pass generation: The model writes the whole path in one go, not through multiple back‑and‑forth steps or long “reasoning” text.
- Lightweight input: During testing, the model only uses a single image from the front camera—no extra car status information (like speed) and no complicated bird’s‑eye‑view maps.
Key terms explained:
- Vision‑LLM (VLM): An AI that can look at images and understand or generate text. Here, it’s repurposed to generate numbers (waypoints) instead of words.
- Waypoint: A small target position the car should aim for next. Stringing many waypoints together creates a smooth path.
- Loss function: The “scoring system” used during training. The authors use a distance‑based score (how far the predicted point is from the real one), which better matches the geometry of driving.
- Autoregressive: Predicting one step at a time, where each new step depends on the previous ones, like writing a sentence word by word.
They also use a practice technique called scheduled sampling: over time, the model learns to trust and correct its own predictions during training—like learning to balance without training wheels.
Main Findings and Why They Matter
- Strong accuracy: On the nuScenes dataset (a popular benchmark for self‑driving), Max‑V1 achieves state‑of‑the‑art results and improves overall performance by over 30% compared to earlier baselines. In simple terms, its predicted paths are closer to the real, expert paths.
- Numbers beat text: When the model outputs waypoints as text (like “(3.2, 1.5)”), it often makes formatting mistakes (missing points, wrong shapes, or non‑numeric symbols) that break the trajectory. Outputting clean numeric vectors fixes this and greatly improves accuracy and safety.
- Simpler is better: The single‑pass design (no extra reasoning steps or special intermediate maps) still performs very well. Removing bird’s‑eye‑view (BEV) processing avoids information loss and reduces complexity.
- Cross‑vehicle and cross‑domain generalization: The model shows promising zero‑shot behavior—working reasonably well on data from different vehicles and locations (like the UK or the Netherlands) without extra training. This hints at real‑world robustness.
- Sensor fusion trade‑off: Adding LiDAR (a depth sensor) can improve very short‑term accuracy (around 1 second) but may hurt longer‑term stability (2–3 seconds) because LiDAR points are dense nearby and sparse far away. This suggests fusion methods should balance near‑field precision with far‑field stability.
Why it matters:
- Safer planning: Distance‑based learning matches real driving needs (smooth, continuous motion).
- Practicality: Fewer inputs, fewer steps, and a simpler architecture make it easier to deploy and maintain.
- Foundation for smarter driving: Good “imitation” accuracy can be a base to add more intelligent decision‑making later (like learning from trial and error).
Implications and Potential Impact
- A unified, lean pipeline: Max‑V1 shows that a general VLM can be adapted to plan driving trajectories directly, replacing many complex modules with one well‑trained model. This can reduce engineering overhead and error stacking.
- Better generalization: Strong cross‑vehicle and cross‑location performance suggests the approach could adapt more easily to different fleets and cities.
- Path to true autonomy: Today’s results focus on imitating expert paths (open‑loop evaluation). The next step is to combine this with reinforcement learning (letting the model learn by interacting with a simulator or the real world) to make smarter, safer decisions in unusual situations.
- Known challenges: Large models can be slow (latency), and end‑to‑end systems are hard to explain. The authors point to faster inference (distillation, quantization), hardware improvements, and adding explainability tools as future work.
In short, this paper takes a fresh, simpler route to self‑driving: treat driving like a sequence you write, predict precise next positions instead of words, and use a distance‑based score to train. The result is a lean yet powerful system that performs very well and lays the groundwork for more capable, robust self‑driving in the future.
Collections
Sign up for free to add this paper to one or more collections.