- The paper introduces CarLLaVA, a framework that leverages vision-language pretraining to enable efficient camera-only closed-loop autonomous driving.
- The model’s semi-disentangled architecture combines time-conditioned waypoint and space-conditioned path predictions to enhance steering and collision avoidance.
- Experimental results show a 32.6% performance improvement and first-place ranking in the CARLA challenge, validating its scalable design.
Vision-LLMs for Autonomous Driving: An Examination of CarLLaVA
Introduction
The exploration of Vision-LLMs (VLMs) in autonomous driving has led to innovative advancements characterized by sophisticated integration of visual and linguistic data streams. The paper "CarLLaVA: Vision LLMs for Camera-Only Closed-Loop Driving" (2406.10165) introduces CarLLaVA, a novel framework developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA capitalizes on vision-language pre-training to optimize performance in an end-to-end camera-driven autonomous driving setting without the reliance on costly sensor inputs or labeled data.
Model Architecture
CarLLaVA leverages the LLaVA VLM's vision encoder and integrates the LLaMA architecture for enhanced driving performance. The core architecture involves a semi-disentangled output representation that facilitates both path and waypoint predictions, optimizing lateral and longitudinal vehicle control, respectively. This model utilizes a vision encoder pre-trained on extensive internet-scale datasets to infer essential features from camera inputs, eschewing traditional ResNet-styled ImageNet pre-trained configurations.
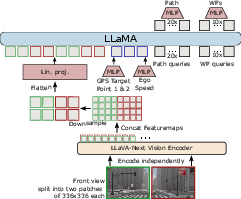
Figure 1: CarLLaVA base model architecture. (C1T1) The images are split in two, and each split is independently encoded and then concatenated, downsampled and projected into a pre-trained LLM. The output utilises a semi-disentangled representation with both time-conditioned waypoints and space-conditioned path waypoints for improved lateral control.
Training Methodology
An efficient training regime is employed, focusing on reducing computational redundancy by emphasizing challenging scenarios over trivial driving data. CarLLaVA discards broad-scale labels, allowing the model to depend solely on camera images and easily obtainable driving trajectory data. The employed training method strategically leverages diverse buckets of interesting data samples, thereby optimizing the effectiveness of the learning process and reducing unnecessary computational costs.
Experimental Results
Highlighted by its first-place rank in the CARLA driving challenge's sensor track, CarLLaVA surpasses the preceding state-of-the-art by a significant margin, validating its design. To compare, the model showed a 32.6% improvement over concurrent submissions, demonstrating unparalleled efficiency and adaptability in closed-loop scenarios.
Moreover, the transition from waypoint prediction to path prediction within the semi-disentangled framework markedly enhanced collision mitigation capabilities, underscoring advanced steering behavior across simulated environments.

Figure 2: Qualitative examples of generated language. Red: predicted path, Green: predicted waypoints, Blue: Target Points.
Discussion
The framework explores preliminary applications of language commentary generation, which is indicative of a future trajectory toward more robust multi-modal capabilities in autonomous vehicles. CarLLaVA’s design, which omits extensive label requirements while leveraging vision-language pre-training, renders it a practical candidate for scalable, real-world deployment in resource-constrained settings.
Conclusion
CarLLaVA represents a sophisticated approach to integrating vision and language in autonomous driving. By effectively circumventing the need for expensive sensors and extensive labeled datasets, CarLLaVA offers an efficient, high-performance paradigm for end-to-end driving systems. Moving forward, further exploration of multi-camera and temporal data integration will be crucial for addressing outstanding challenges in high-speed maneuvers and rear-end collision avoidance in complex driving scenarios.