- The paper introduces a two-stage RL framework that first improves geometric perception and then reinforces reasoning, resulting in significant performance gains.
- Perception training alone boosts GeoPQA accuracy by 21.6%, while reasoning-only RL can harm perceptual accuracy by 15.1%, highlighting the need for sequential optimization.
- Empirical evaluations on benchmarks like MathVista reveal improvements up to 9.7% in geometric reasoning and 9.1% in problem solving.
GeoPQA: Bridging the Visual Perception Gap in MLLMs for Geometric Reasoning
Motivation and Problem Statement
Multimodal LLMs (MLLMs) have demonstrated notable progress in integrating visual and textual modalities, yet their performance on vision-intensive reasoning tasks, particularly geometric problem solving, remains suboptimal. The paper identifies a critical bottleneck: the perceptual limitations of MLLMs in accurately interpreting geometric structures and spatial relationships. Empirical evidence shows that these perceptual errors propagate into flawed reasoning, severely constraining the effectiveness of reinforcement learning (RL) approaches that have otherwise succeeded in unimodal LLMs.

Figure 1: Perceptual errors in Qwen-2.5-3B-Instruct cascade into incorrect geometric reasoning, such as misidentifying rotation angles and misinterpreting angle composition.
GeoPQA Benchmark and Perceptual Bottleneck Quantification
To systematically assess and quantify the perceptual gap, the authors introduce the Geo-Perception Question-Answering (GeoPQA) benchmark. This benchmark targets fundamental geometric concepts (e.g., shape identification, angle classification, length comparison) and spatial relationships (e.g., intersection, parallelism, tangency) using both real-world and synthetic diagrams. The evaluation protocol restricts answers to verifiable formats (yes/no, numbers, or simple strings), enabling automated and reliable assessment.
Empirical results reveal that state-of-the-art MLLMs, including Qwen2.5-VL-3B-Instruct and GPT-4o, exhibit significant deficiencies in basic geometric perception, with accuracy rates far below human performance. Notably, reasoning-oriented RL training can further degrade perceptual accuracy, underscoring the necessity of explicitly addressing perception before reasoning.
Two-Stage RL Framework: Perception then Reasoning
To overcome the perceptual bottleneck, the paper proposes a two-stage RL training framework:
- Stage 1: Perception-Oriented Training The model is first trained to answer multiple perception QAs per image, focusing exclusively on geometric elements and relationships. The training data is curated from both real and synthetic sources, with rigorous quality control via LLM-based filtering and human inspection. The reward function is strict: a positive reward is granted only if all sub-questions for an image are answered correctly, discouraging reward hacking and promoting robust perceptual learning.
- Stage 2: Reasoning-Oriented Training
Building on the improved perceptual foundation, the model is subsequently trained on geometric reasoning tasks using standard RL protocols (Group Relative Policy Optimization, GRPO). This stage leverages the enhanced visual understanding to facilitate multi-step logical deduction.
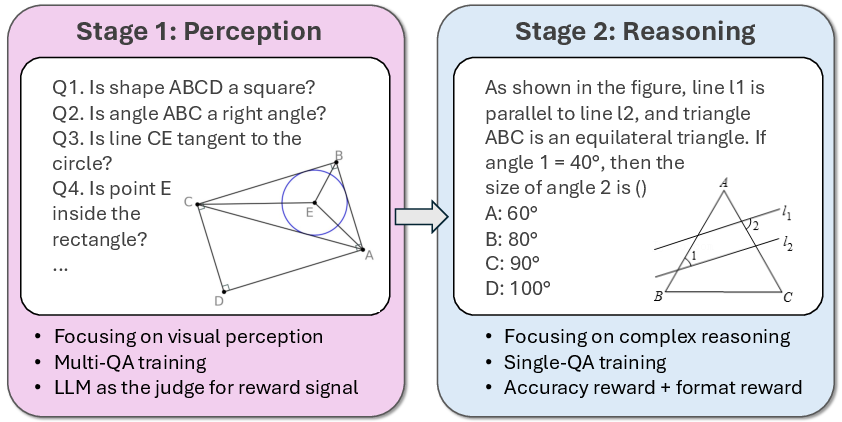
Figure 2: Overview of the two-stage RL framework, with sequential perception and reasoning training phases.
Implementation Details
The framework is instantiated on Qwen2.5-VL-3B-Instruct and Qwen2.5-VL-7B-Instruct backbones. Training samples concatenate multiple perception QAs per image, which is shown to be superior for downstream reasoning compared to single-QA samples. Hyperparameters are standardized across experiments to ensure comparability. Evaluation is conducted on MathVista and MathVerse benchmarks, with additional analysis on other vision-intensive tasks.
Experimental Results
Main Results
- The two-stage approach yields a 9.7% improvement in geometric reasoning (GR) and 9.1% in geometric problem solving (GPS) over reasoning-only RL on MathVista.
- Reasoning-only RL can degrade both perception and reasoning performance, sometimes scoring lower than the baseline.
- Mixing perception and reasoning data improves performance, but the sequential two-stage approach is consistently superior, especially for vision-only tasks.
Perceptual Enhancement
- Perception training alone improves GeoPQA accuracy by 21.6%.
- Reasoning training alone degrades GeoPQA accuracy by 15.1%.
- The two-stage approach maintains high perception accuracy (83.2%), balancing perceptual and reasoning gains.
Vision Intensity Analysis
- The two-stage framework excels in vision-only and vision-dominant scenarios, where textual cues are absent and perceptual grounding is essential.
- For text-dominant tasks, perception training is less critical, but does not harm performance.
Ablation: Multiple QAs per Image
- Training with multiple QAs per image improves downstream reasoning by 9.6% (GR) and 10.6% (GPS) compared to single-QA training, despite slightly lower perception task accuracy due to stricter reward criteria.
Scaling to Larger Models
- On Qwen2.5-VL-7B-Instruct, the two-stage approach yields 2.6% (GR) and 4.8% (GPS) improvements, surpassing all open-source and proprietary baselines except GPT-4o, and narrowing the gap to within 2%.
Generalization
- The perception-first paradigm generalizes to other visually grounded tasks (figure QA, textbook QA, scientific reasoning), with gains up to 2.6%.
- For text-reliant or non-geometric visual tasks, the impact is neutral or slightly negative, indicating the specificity of perceptual enhancement.
Theoretical and Practical Implications
The findings establish that RL-based reasoning improvements in MLLMs are fundamentally upper-bounded by the model's visual perception capabilities. Direct reasoning training without perceptual grounding can be ineffective or detrimental. The two-stage framework provides a principled approach to disentangle and sequentially optimize perception and reasoning, yielding state-of-the-art results with modest model sizes.
Practically, this paradigm is applicable to any vision-intensive domain where perceptual errors can cascade into flawed reasoning, such as chart understanding, scientific diagram interpretation, and medical imaging. The strict reward and multi-QA training strategies are critical for robust perceptual learning.
Future Directions
Potential avenues for future research include:
- Extending the perception-first framework to "thinking-with-images" approaches and other multimodal reasoning paradigms.
- Generalizing to domains beyond geometry, such as chart and graph understanding, where perceptual bottlenecks are prevalent.
- Investigating curriculum learning strategies that dynamically balance perception and reasoning based on task requirements.
- Reducing reliance on LLM-based judges for reward computation to lower cost and latency.
Conclusion
GeoPQA demonstrates that perceptual limitations are a critical bottleneck in MLLM geometric reasoning. By explicitly quantifying and addressing this gap through a two-stage RL framework, substantial improvements are achieved in both perception and reasoning. The results highlight the necessity of strong perceptual foundations for effective multimodal reasoning and provide a scalable blueprint for future MLLM development in vision-intensive domains.

