- The paper introduces Perception-R1, incorporating visual perception rewards into RLVR to significantly boost multimodal reasoning accuracy.
- The methodology leverages curated visual annotations and a judging LLM to ensure consistency between visual content and generated responses.
- Experiments on multiple benchmarks demonstrate state-of-the-art performance with less training data, underscoring improved data efficiency.
Advancing Multimodal Reasoning Capabilities of MLLMs via Visual Perception Reward
Introduction
The paper presents a novel approach called "Perception-R1" to enhance the multimodal reasoning capabilities of Multimodal LLMs (MLLMs) by incorporating visual perception rewards during Reinforcement Learning with Verifiable Rewards (RLVR) training. The study identifies a significant limitation in existing RLVR methods, which fail to improve the multimodal perception capabilities of MLLMs, a prerequisite for advanced multimodal reasoning. Through extensive experiments, the paper demonstrates that Perception-R1 achieves state-of-the-art performance on multiple benchmarks using a considerably smaller dataset than prior methods.

Figure 1: A comparison of three MLLMs on a geometry problem. Both Qwen2.5-VL-7B-IT and its RLVR-trained variant make severe perception errors but manage to guess the answer, whereas our {Perception-R1} accurately describes the image and solves the problem correctly.
Methods
Accuracy-only RLVR Limitations
The paper highlights that accuracy-only RLVR focuses on reasoning optimization based solely on ground-truth answer accuracy, overlooking the importance of multimodal perception. This approach results in sparse reward signals for perception tasks, which limits the ability of MLLMs to correct multimodal perception errors, as illustrated by the failure cases leading to flawed reasoning paths despite correct answers.
Perception-R1 Framework
Perception-R1 addresses the reward sparsity by introducing a visual perception reward into RLVR. This reward provides an additional signal to promote accurate visual content perception. The methodology involves:
- Curation of Visual Annotations: Collecting CoT trajectories with accurate answers and extracting critical visual information using a proprietary multimodal reasoning model.
- Visual Perception Reward Assignment: Employing a judging LLM to evaluate the consistency between visual annotations and model-generated responses, thereby guiding rollouts in RLVR.
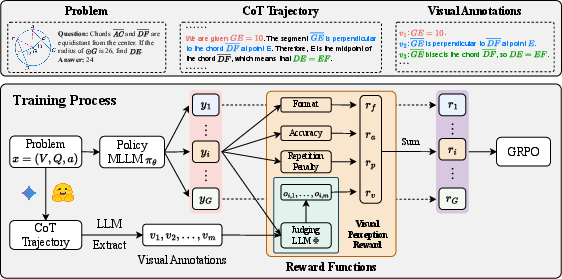
Figure 2: Overview of training pipeline of the proposed {Perception-R1}, integrating the visual perception reward.
Experiments
Datasets and Benchmarks
The paper utilizes the Geometry3K dataset for training, supplemented by visual annotations extracted from Gemini-2.5-Pro generated CoT trajectories. Evaluation covers MathVista, MathVerse, MathVision, and WeMath benchmarks to ensure comprehensive performance analysis.
Results
Perception-R1 achieves new state-of-the-art results across most benchmarks, significantly enhancing the multimodal perception capabilities of MLLMs. Notably, it outperforms prior SOTA methods using substantially less training data, evidencing its data efficiency and effectiveness.
Statistical Significance
The improvements in perception capabilities are statistically significant, demonstrated through McNemar’s test on the perception-related discordant cases. The test confirms that Perception-R1 significantly advances the multimodal perception capabilities in comparison to original MLLMs.
Ablation Studies and Further Analysis
The ablation studies explore the impact of various components (e.g., repetition penalty, different judging LLMs) and alternative approaches (e.g., using MLLMs as reward models). Results firmly support the benefits of the visual perception reward in improving multimodal reasoning and perception.
Impact of Judging LLMs
Experiments reveal that using lower-capacity judging LLMs introduces reward hacking, misguiding the learning process, thus underscoring the importance of selecting a robust judging LLM for accurate reward assignment.
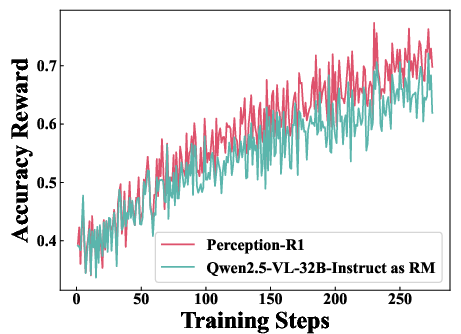
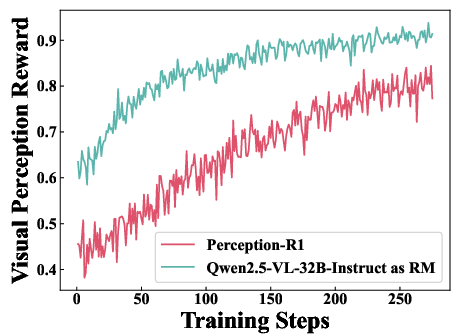
Figure 3: Dynamics of Accuracy Reward, illustrating the influence of different judging LLMs on learning efficiency.
Conclusion
Perception-R1 introduces a pivotal enhancement to MLLMs through the integration of visual perception rewards, addressing critical limitations in their reasoning development by reinforcing perceptual foundations. These findings suggest promising directions for future multimodal reasoning advancements by focusing on richer reward signal integration. The methodology positions itself with significant implications on how perception tasks can enhance reasoning capabilities in AI systems.
Learnings from this approach could potentially inform the development of AGI systems, emphasizing the necessity of multimodal perception frameworks in intricate reasoning processes. Future research could explore expanding the concept to wider domains, leveraging enhanced perception capabilities to tackle complex environmental interactions in AI applications.