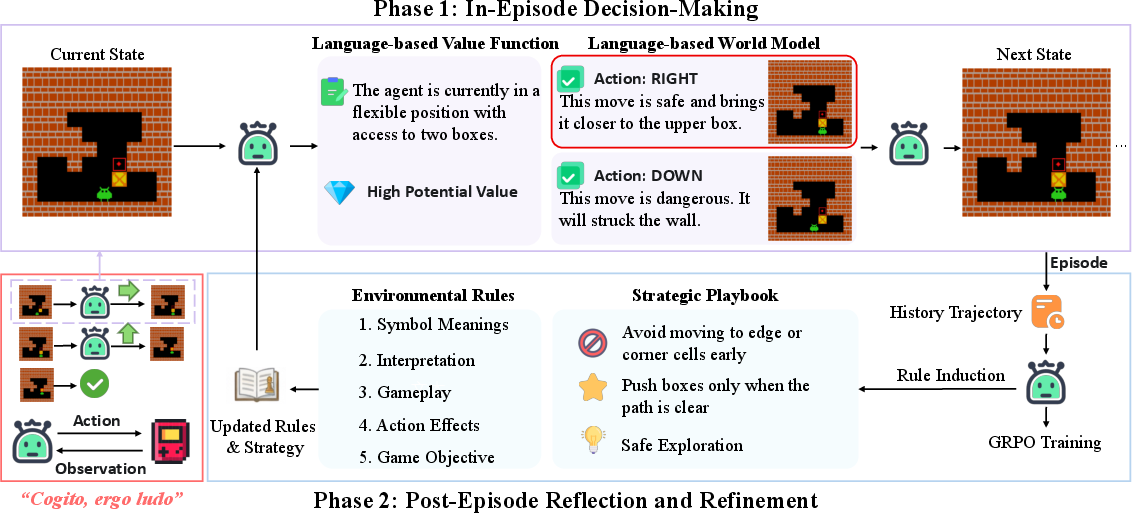
- The paper demonstrates that explicit LLM-based planning enables agents to autonomously learn game rules and strategies through in-episode decision-making and post-episode reflection.
- Methodology includes a two-phase cycle with a Language-based World Model and Value Function, achieving near-perfect performance on Frozen Lake and significant gains in other games.
- Results support that iterative rule induction enhances generalization and transfer across games, ensuring both interpretability and robust learning.
Cogito, Ergo Ludo: Explicit Reasoning and Planning for Autonomous Game-Playing Agents
Introduction and Motivation
The paper "Cogito, Ergo Ludo: An Agent that Learns to Play by Reasoning and Planning" (2509.25052) introduces the Cogito, ergo ludo (CEL) agent, a novel architecture for interactive environments that departs from conventional deep RL paradigms. Instead of relying on implicit knowledge encoded in neural network weights, CEL leverages a LLM to construct and iteratively refine an explicit, human-readable world model and strategic playbook. The agent starts from a tabula rasa state, possessing only the action set, and learns solely through interaction and reflection, without access to ground-truth rules or privileged information.

Figure 1: A comparison of agent paradigms: conventional RL (implicit policy), zero-shot LLM reasoning (static), and CEL (explicit, persistent knowledge base with RL training).
This approach is motivated by the limitations of deep RL agents, which are sample-inefficient and opaque, and by the inadequacy of zero-shot LLM agents, which lack mechanisms for continuous adaptation. CEL aims to bridge this gap by enabling agents to reason, plan, and learn explicit models of their environment, thereby achieving both interpretability and generalization.
Architecture and Operational Cycle
CEL's architecture is structured around a two-phase operational cycle:
- In-Episode Decision-Making: At each timestep, the agent uses its Language-based Value Function (LVF) to assess the current state's desirability and its Language-based World Model (LWM) to predict the outcomes of all possible actions. The agent selects the action with the highest predicted value, simulating a one-step lookahead search entirely in natural language.
- Post-Episode Reflection: After each episode, the agent performs two concurrent learning processes:
All information—states, actions, rewards, rules, and strategies—is represented as natural language strings, and the LLM's reasoning is made explicit via chain-of-thought traces. The agent's knowledge base is persistent and human-interpretable, enabling transparent decision-making and rapid adaptation.
Core Cognitive Components
Language-based World Model (LWM)
The LWM predicts the next state and reward given the current state, action, and rulebook. Unlike latent world models (e.g., MuZero, Dreamer), LWM's predictions are explicit and grounded in language, facilitating interpretability and direct reasoning about environmental dynamics.
Rule Induction
After each episode, the agent updates its rulebook by analyzing the trajectory and prior rules. This process enables the agent to autonomously discover the mechanics of the environment, starting from no prior knowledge.

Figure 3: Excerpt from the agent's learned rulebook for Minesweeper, demonstrating comprehensive rule induction from raw interaction.
Strategy and Playbook Summarization
The agent synthesizes tactical methods and high-level principles from its experience, constructing a strategic playbook that informs future decision-making.
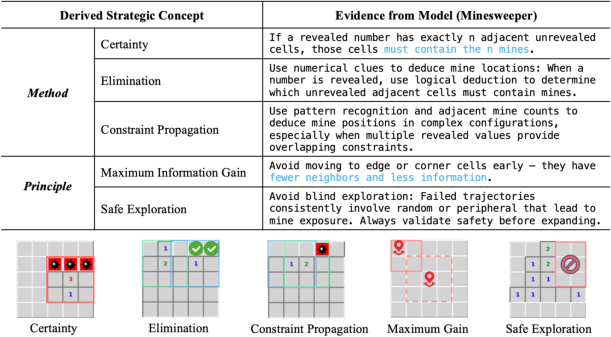
Figure 4: Strategic playbook for Minesweeper, containing both tactical methods and abstract principles distilled from gameplay.
Language-based Value Function (LVF)
The LVF provides qualitative assessments of state value, conditioned on the current rulebook and playbook. This enables the agent to make strategically sophisticated decisions, even in sparse-reward settings.
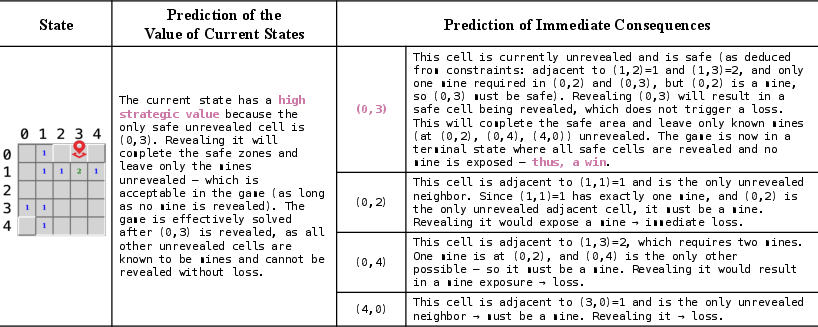
Figure 5: In-episode decision-making: LVF assesses state value, LWM predicts action outcomes, and the agent selects the optimal action.
Experimental Evaluation
CEL was evaluated on three grid-world environments: Minesweeper, Frozen Lake, and Sokoban, each configured with sparse rewards and no explicit rules. The agent demonstrated consistent improvement across all tasks, autonomously discovering rules and developing effective strategies.
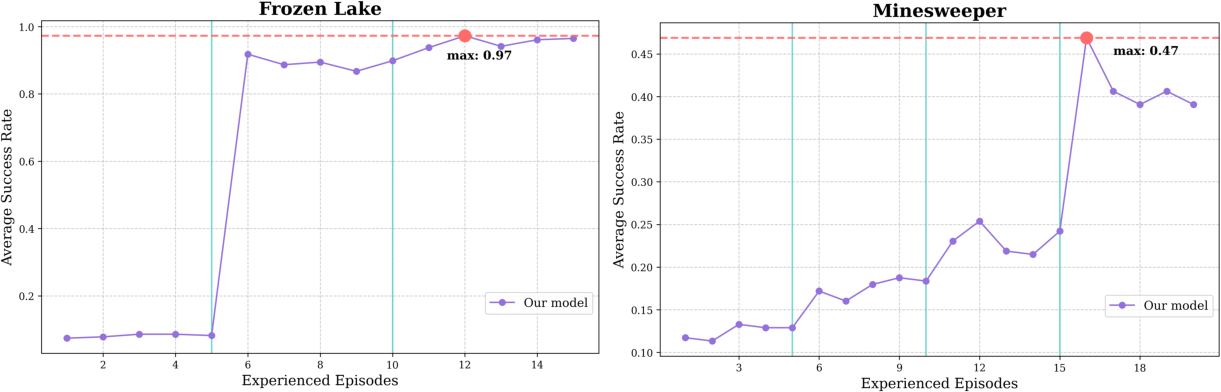
- Minesweeper: CEL achieved a peak success rate of 54%, surpassing the 26% baseline that had access to ground-truth rules.
- Sokoban: The agent exhibited a breakthrough learning pattern, reaching 84% success after initial exploration.
- Frozen Lake: CEL rapidly achieved near-perfect performance (97%) within 10 episodes.
Ablation studies confirmed that iterative rule induction is essential; agents with static or no rule updates stagnated at low performance.
Generalization and Transfer
CEL's explicit reasoning enables strong generalization:
This demonstrates that CEL transfers the meta-ability to learn by reasoning and planning, rather than memorizing environment-specific patterns.
Scalability and Optimization
Experiments with expanded training sets (128 unique Minesweeper seeds) showed further improvement, with peak success rates rising to 62%. The agent was implemented using rLLM and Qwen3-4B-Instruct, with GRPO for post-training and a maximum response length of 8,192 tokens to encourage deep reasoning.
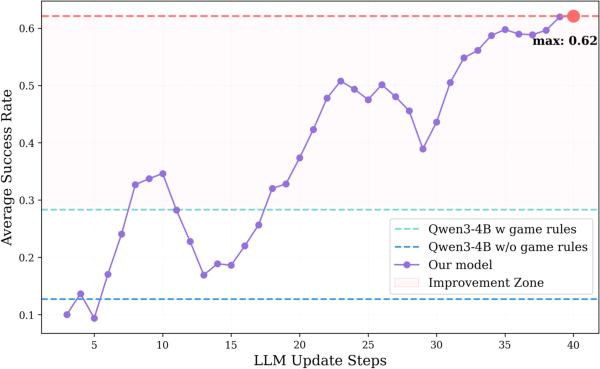
Figure 7: Learning curve for CEL on Minesweeper with 128 seeds, showing improved peak performance.
Ablation of chain-of-thought reasoning and cognitive components resulted in training failure, highlighting the necessity of nuanced reasoning traces for effective optimization.
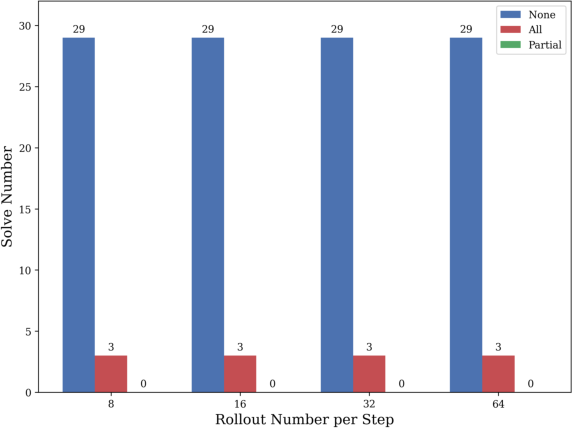
Figure 8: Rollout outcome distribution for the Action-only model, showing binary results and lack of partial rollouts required for GRPO learning.
Interpretability and Knowledge Base
CEL produces a transparent, auditable knowledge base, including explicit environmental rules and strategic guidelines for each environment.
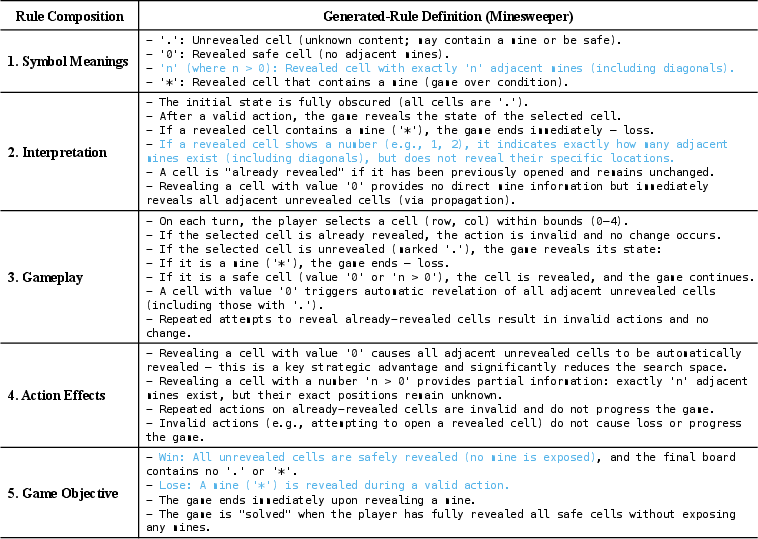
Figure 9: Example of a learned environmental rule for Minesweeper.
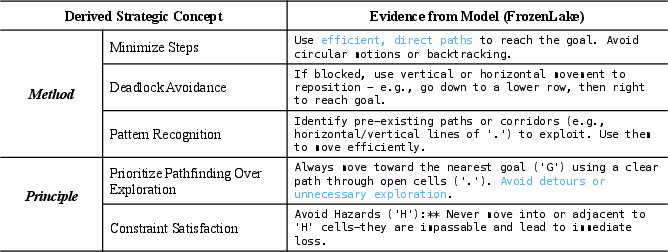
Figure 10: Example of a learned strategic guideline for Frozen Lake.
This interpretability facilitates debugging, transfer, and human-in-the-loop collaboration, addressing a major limitation of conventional RL agents.
Implications and Future Directions
CEL demonstrates that explicit, language-based reasoning and planning can yield agents that are both effective and interpretable, even in sparse-reward, unknown-rule environments. The architecture's modularity and transparency suggest promising directions for hybrid systems that combine CEL's explicit knowledge with the efficiency of traditional RL. Potential future developments include scaling to more complex domains, integrating multimodal reasoning, and leveraging CEL's knowledge base for explainable AI and safe deployment.
Conclusion
Cogito, ergo ludo (CEL) represents a significant advancement in agent architectures, enabling autonomous mastery of complex environments through explicit reasoning and planning. By constructing and refining a human-readable world model and strategic playbook, CEL achieves robust performance, strong generalization, and interpretability. The results validate language-based reasoning as a powerful foundation for general, trustworthy agents and open new avenues for research in hybrid cognitive architectures and explainable reinforcement learning.