- The paper introduces the TiG framework, bridging declarative and procedural knowledge by recasting reinforcement learning as a language modeling task for game strategy.
- It employs Group Relative Policy Optimization (GRPO) to stabilize training, achieving up to 90.91% accuracy in macro-level action prediction with efficient resource use.
- Evaluation shows that TiG-trained models maintain general reasoning abilities while providing transparent, step-by-step natural language guidance in dynamic game environments.
Think in Games: Learning to Reason in Games via Reinforcement Learning with LLMs
Introduction and Motivation
The paper addresses a fundamental gap in AI: the distinction between declarative knowledge (knowing about something) and procedural knowledge (knowing how to do something). While LLMs excel at complex reasoning tasks, they struggle with interactive, procedural tasks that require dynamic decision-making, such as those found in digital games. Conversely, RL agents can acquire procedural knowledge through interaction but lack transparency and require extensive data. The proposed Think-In-Games (TiG) framework aims to bridge this gap by enabling LLMs to develop procedural understanding through direct interaction with game environments, specifically focusing on macro-level strategic reasoning in MOBA games.
TiG reformulates RL-based decision-making as a language modeling task. The game state is represented as a structured JSON object, capturing all relevant information from the player's perspective (Figure 1).

Figure 1: Demonstration of JSON object for each game state.
The macro-level action space is discretized into 40 interpretable actions, each corresponding to a strategic objective (e.g., "Push Top Lane", "Secure Dragon"). The policy model is an LLM trained to map game states to macro-level actions and provide step-by-step natural language reasoning. The task is formalized as learning a mapping f:(st,it)↦(at,ct), where st is the game state, it is context, at is the action, and ct is the reasoning chain.
Reinforcement Learning with GRPO
TiG employs Group Relative Policy Optimization (GRPO) for RL, which optimizes the policy model using feedback from game state-action pairs. GRPO normalizes rewards within a batch of completions, stabilizing training and encouraging competitive, context-aware responses (Figure 2).
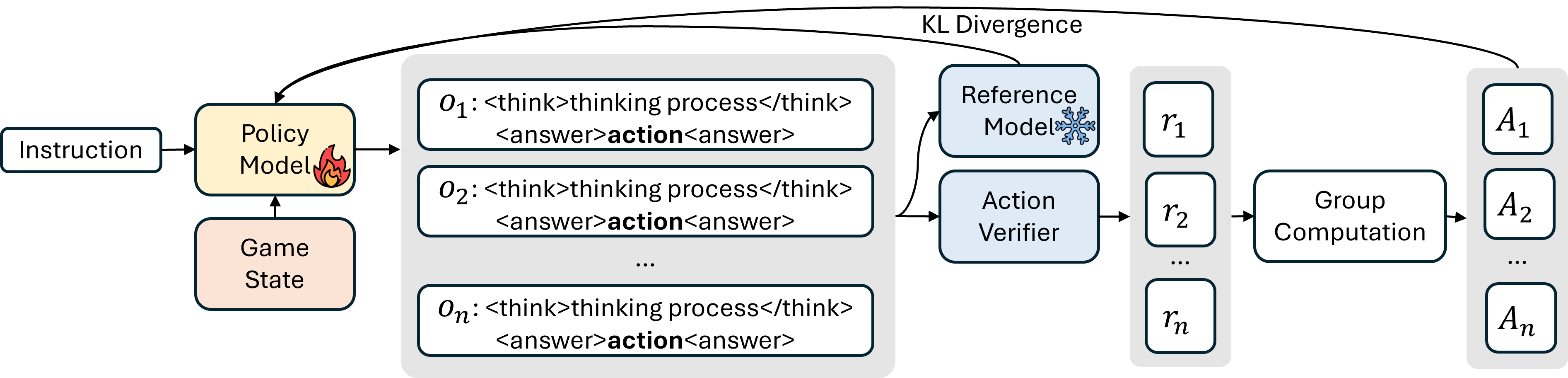
Figure 2: Demonstration of GRPO training with Game State.
The reward function is rule-based and binary, assigning a reward of 1 if the predicted action matches the ground truth and 0 otherwise. This design avoids the complexity of neural reward models and ensures alignment with strategic objectives. The GRPO objective incorporates token-level KL regularization to constrain policy drift, enabling efficient and stable learning.
Experimental Results
TiG demonstrates strong performance in the action prediction task, with multi-stage training (SFT + GRPO) yielding substantial improvements across model sizes. Notably, Qwen-3-14B with SFT and extended GRPO training achieves 90.91% accuracy, surpassing Deepseek-R1 (86.67%), which is significantly larger in parameter count (Figure 3).
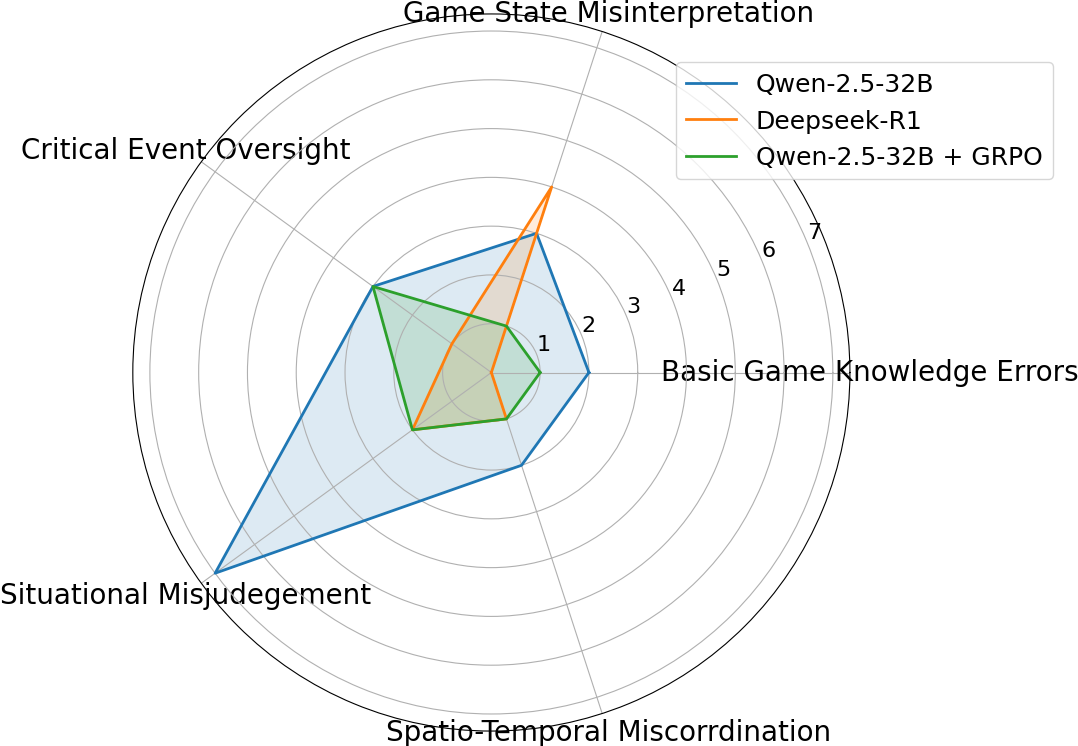
Figure 3: Action Prediction Task.
This result highlights the efficiency and scalability of TiG, enabling smaller models to rival or outperform much larger ones. The introduction of GRPO consistently yields significant accuracy gains, confirming its effectiveness for boosting reasoning capabilities in LLMs.
Generalization and Benchmark Evaluation
TiG-trained models maintain or slightly improve general language and reasoning abilities on standard benchmarks (Ape210K, MMLU, CEval, BBH, IfEval, CharacterEval), indicating that domain-specific improvements do not compromise general capabilities.
Training Dynamics
Analysis of the RL training process shows that response length and reward trends vary by model architecture, with larger models benefiting from longer, more detailed reasoning chains (Figure 4).
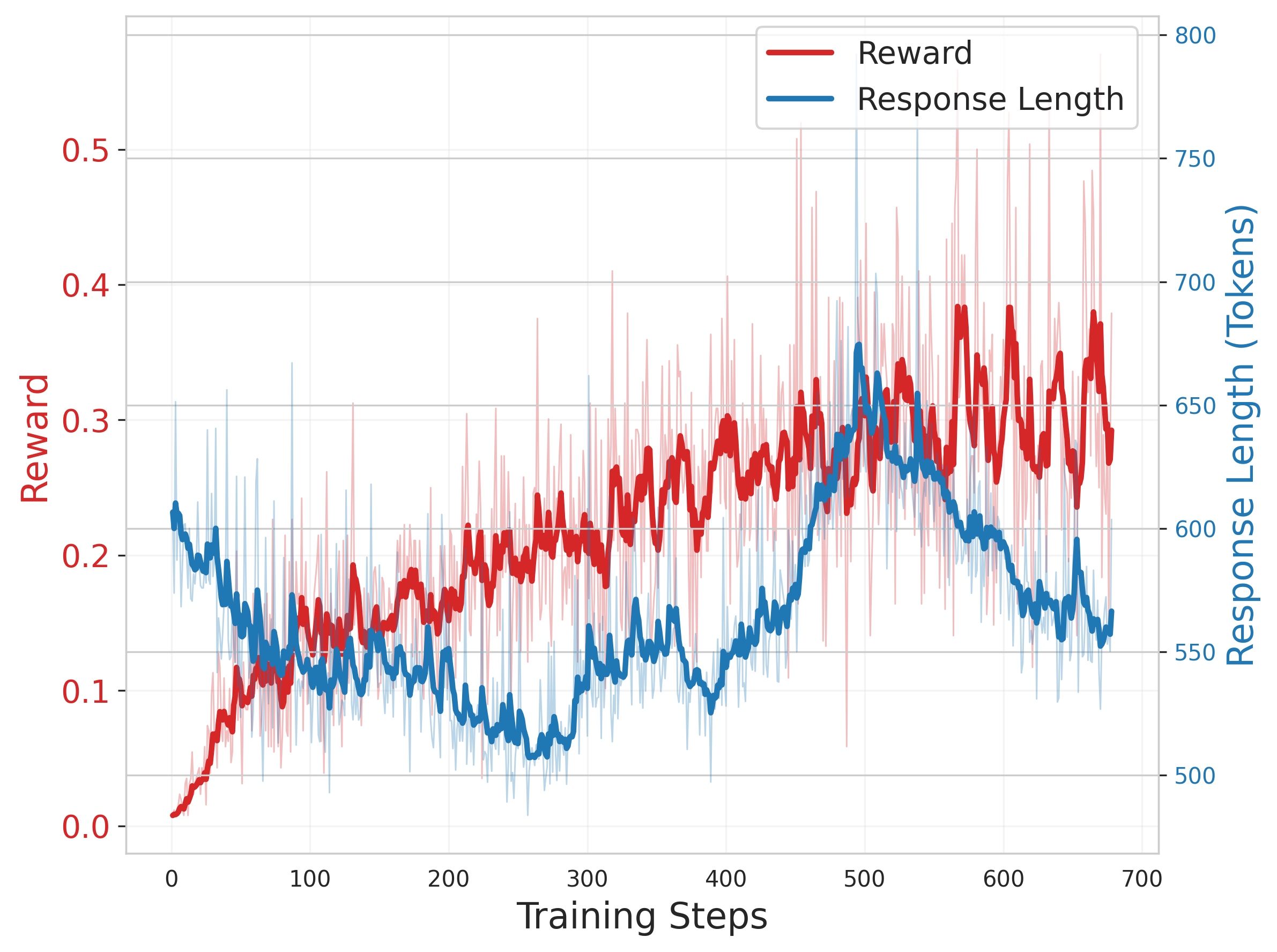
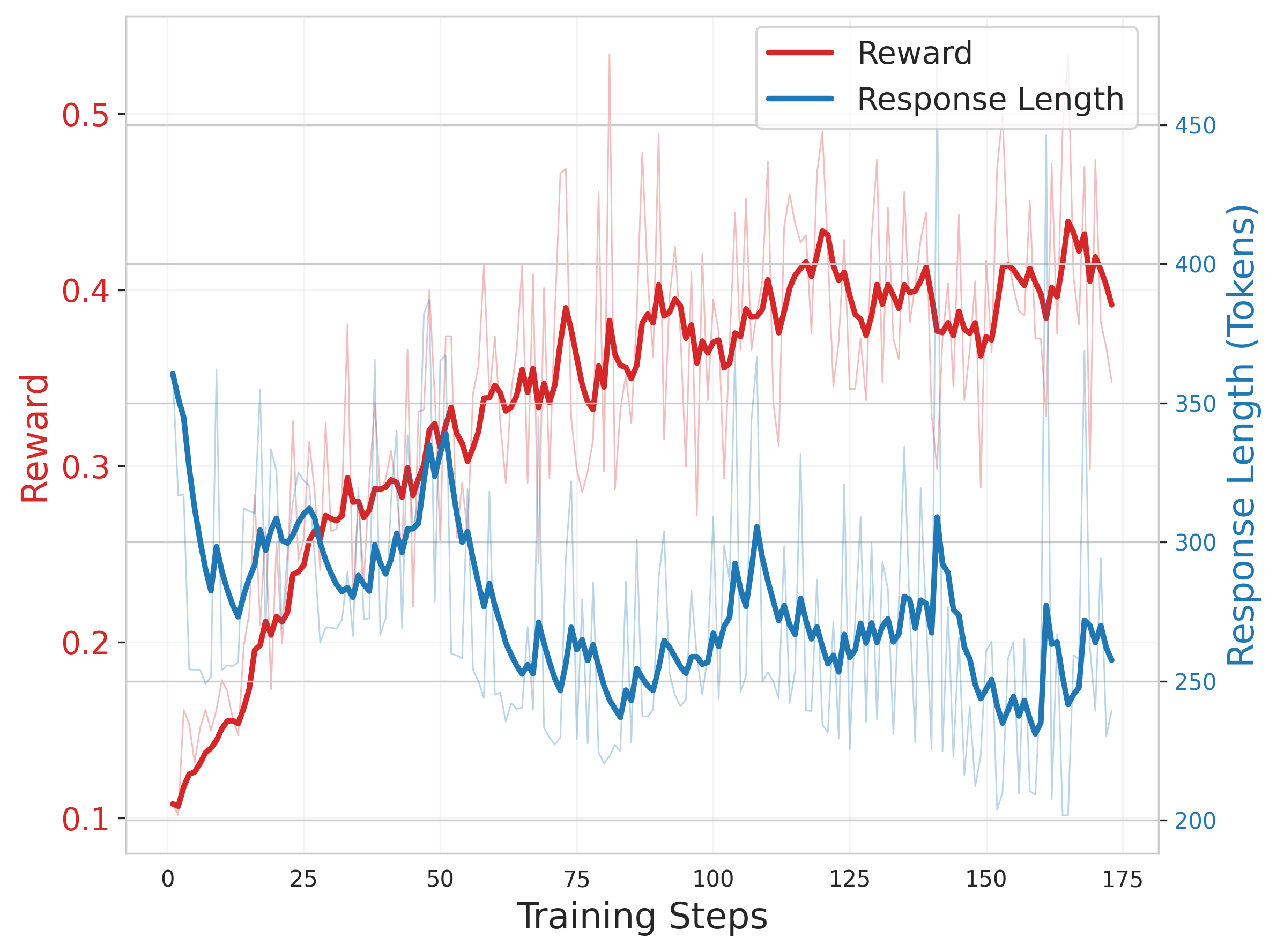
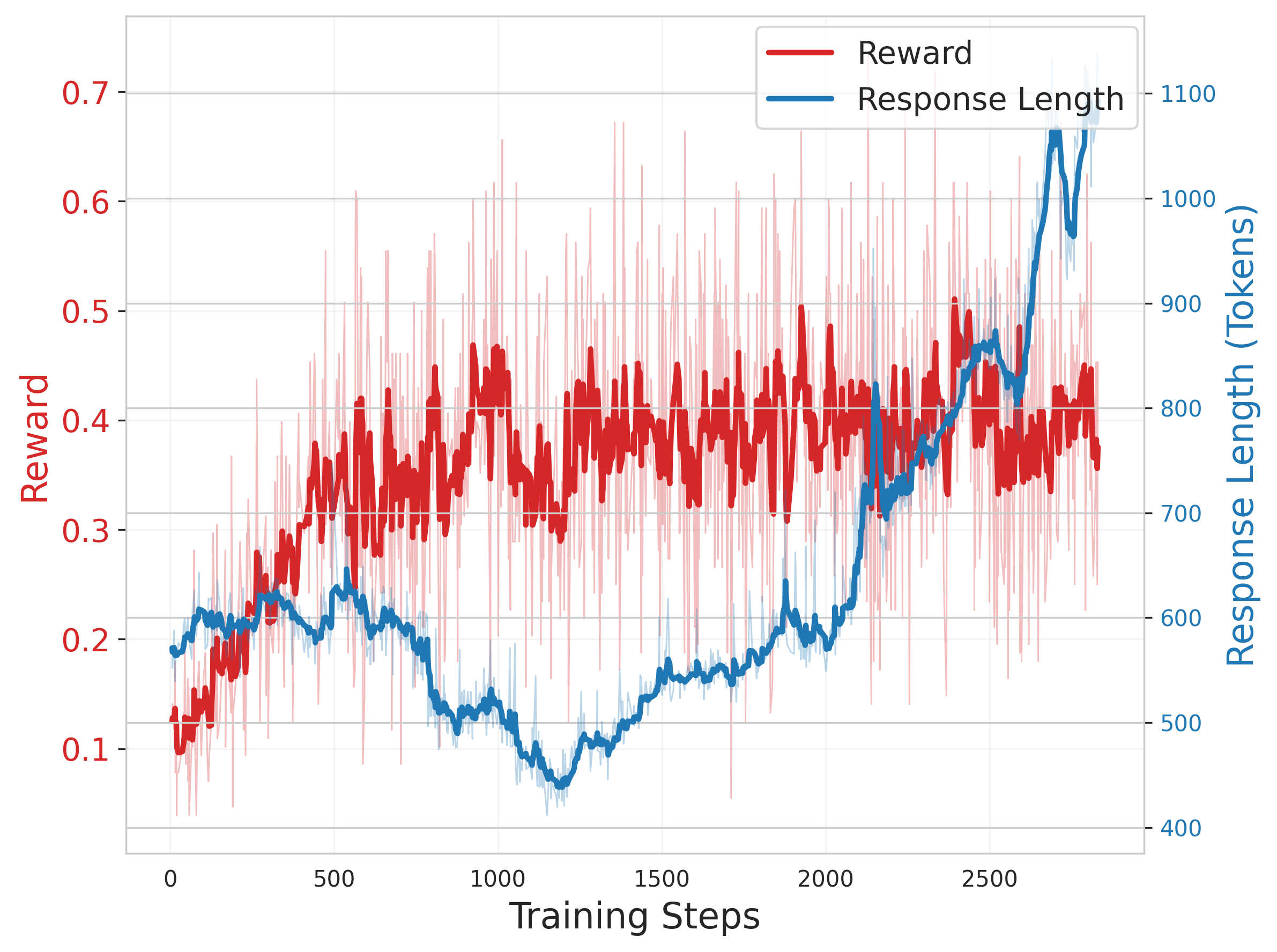
Figure 4: Qwen2.5-14B training dynamics.
Error Analysis
Error cases are categorized into basic game knowledge errors, game state misinterpretation, critical event oversight, situational misjudgment, and spatio-temporal miscoordination. TiG reduces the frequency of these errors compared to baseline models, achieving results comparable to much larger models.
Case Studies
Qualitative case studies illustrate TiG's capacity for deep, context-aware reasoning and actionable guidance. The model analyzes complex game states, prioritizes objectives, formulates strategies, and integrates hero-specific playstyles, providing clear and executable instructions (Figures 4–13).
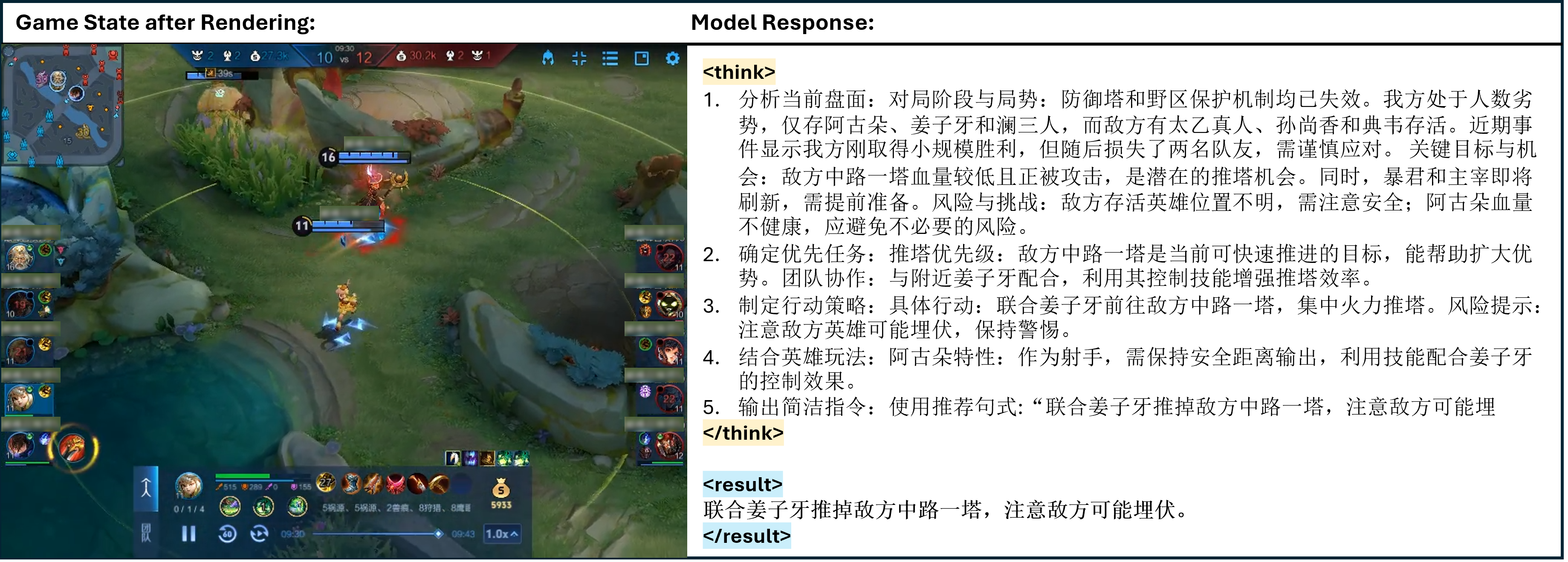
Figure 5: One of the cases of TiG. > </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
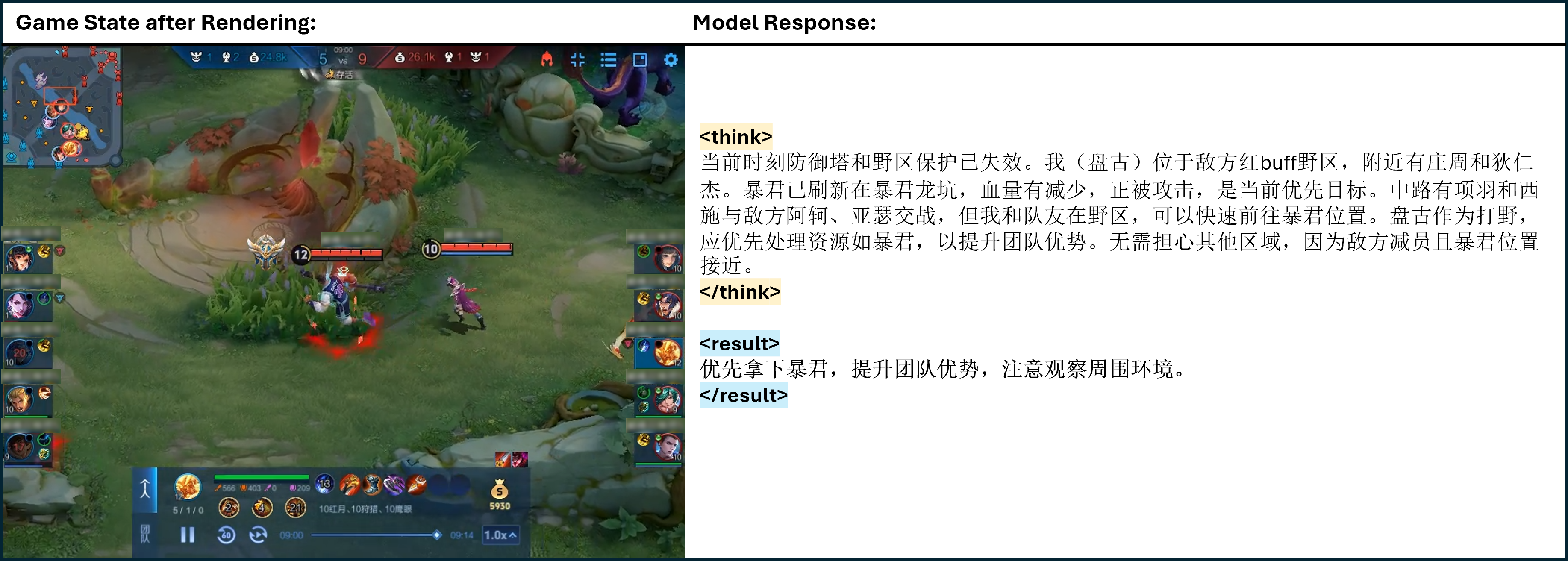
Figure 6: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
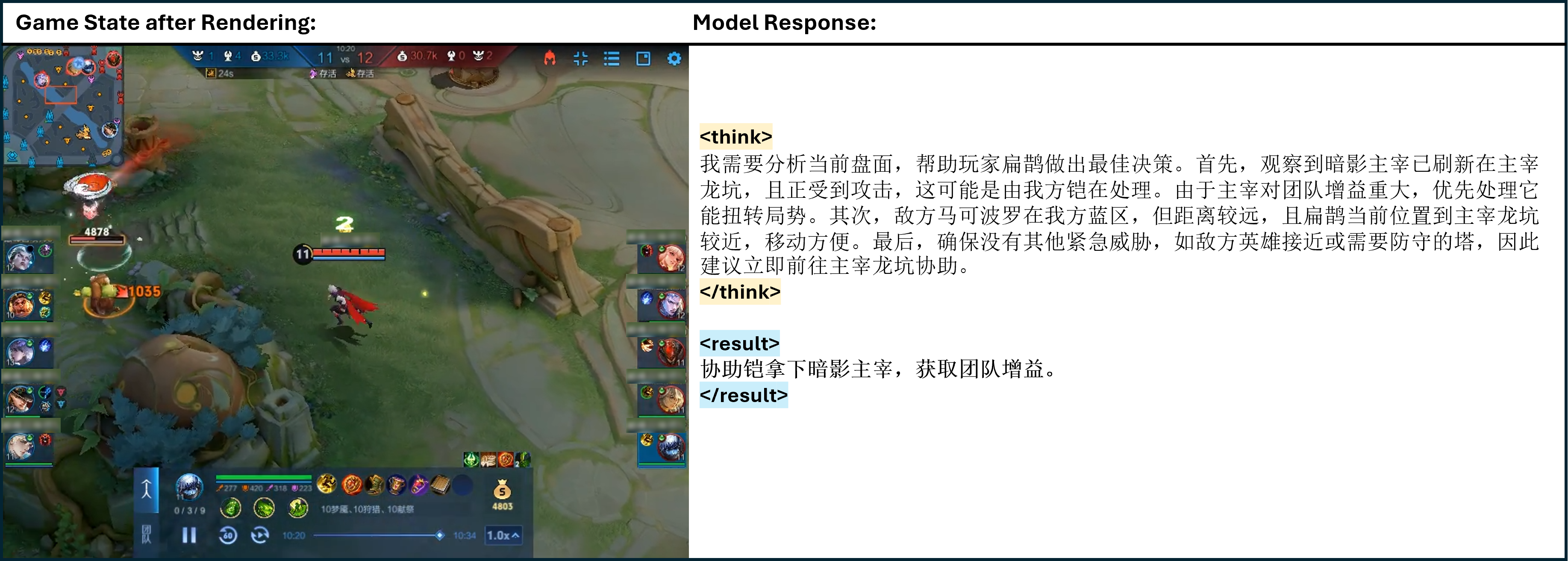
Figure 7: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
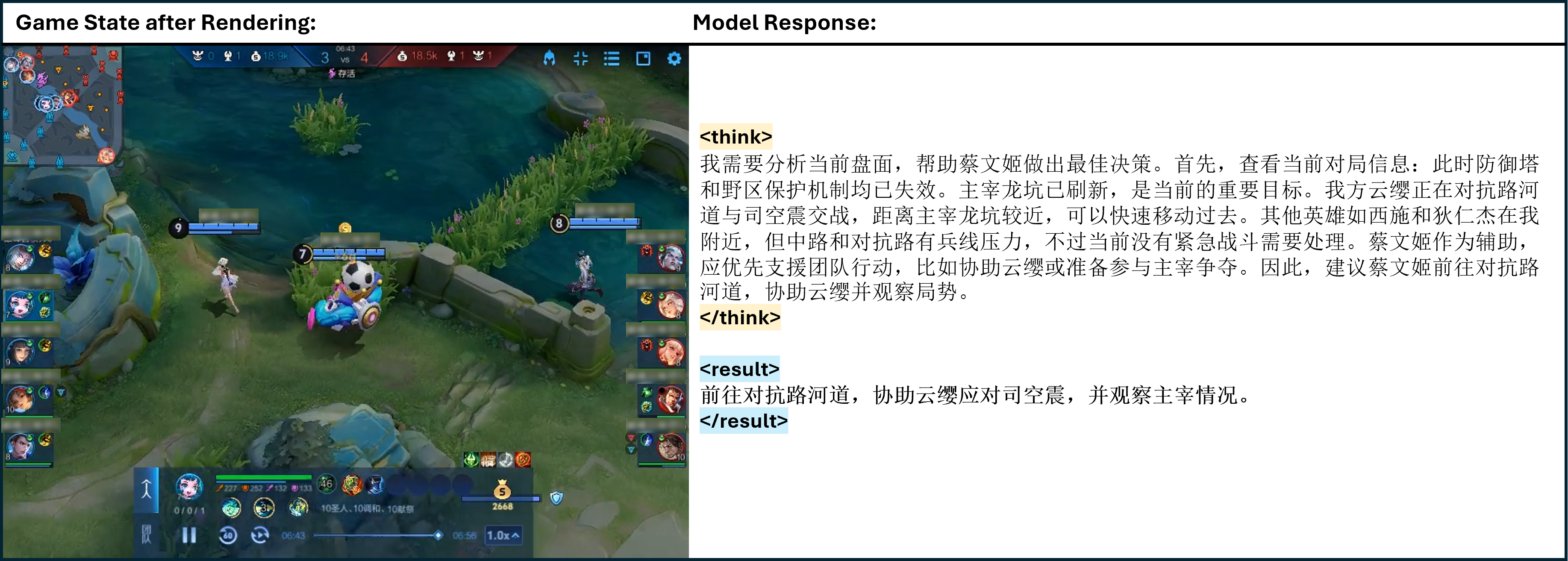
Figure 8: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
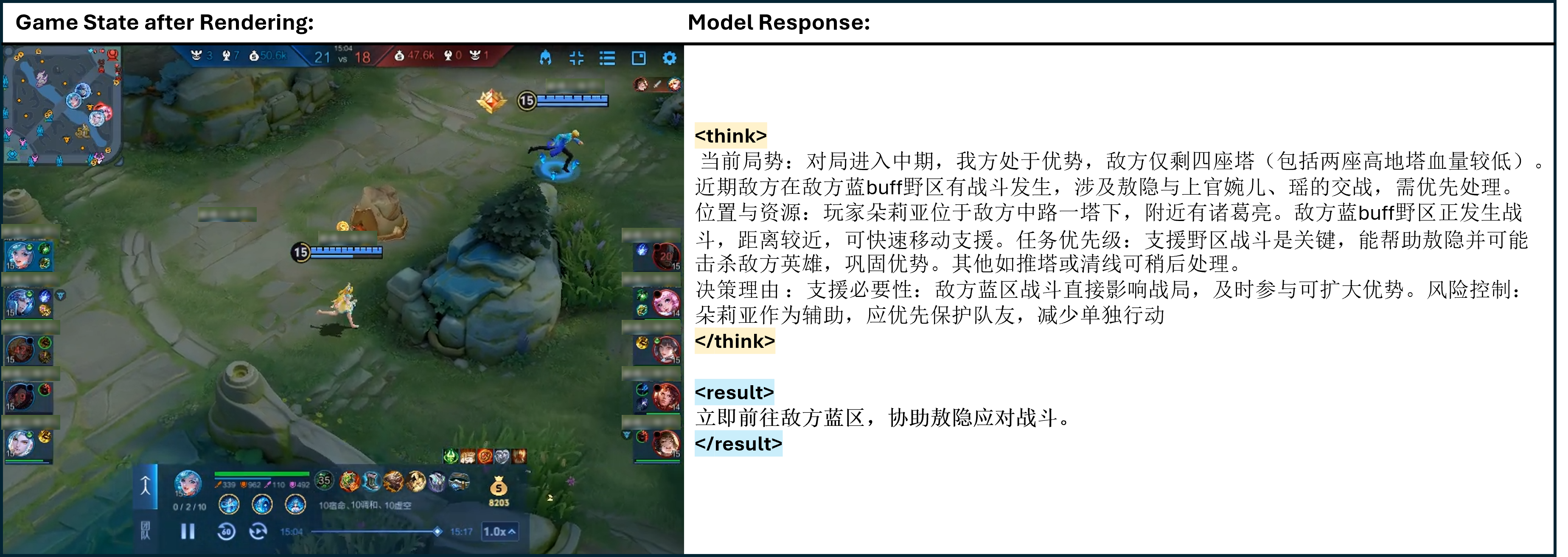
Figure 9: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
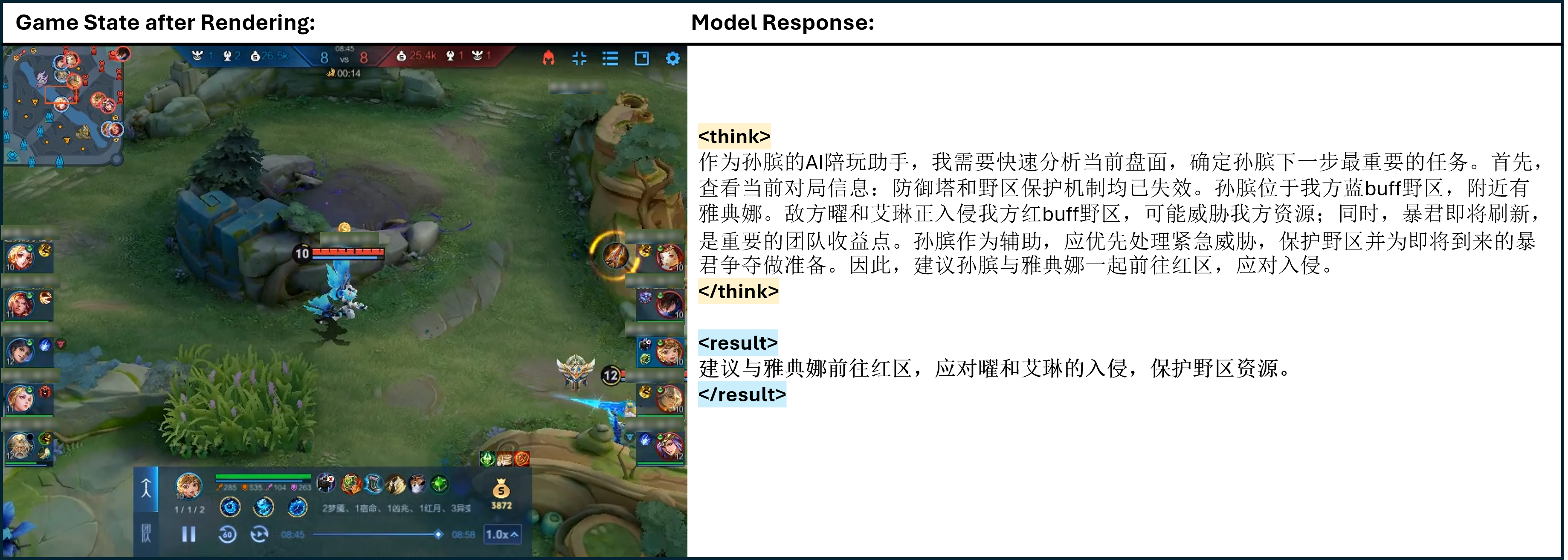
Figure 10: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
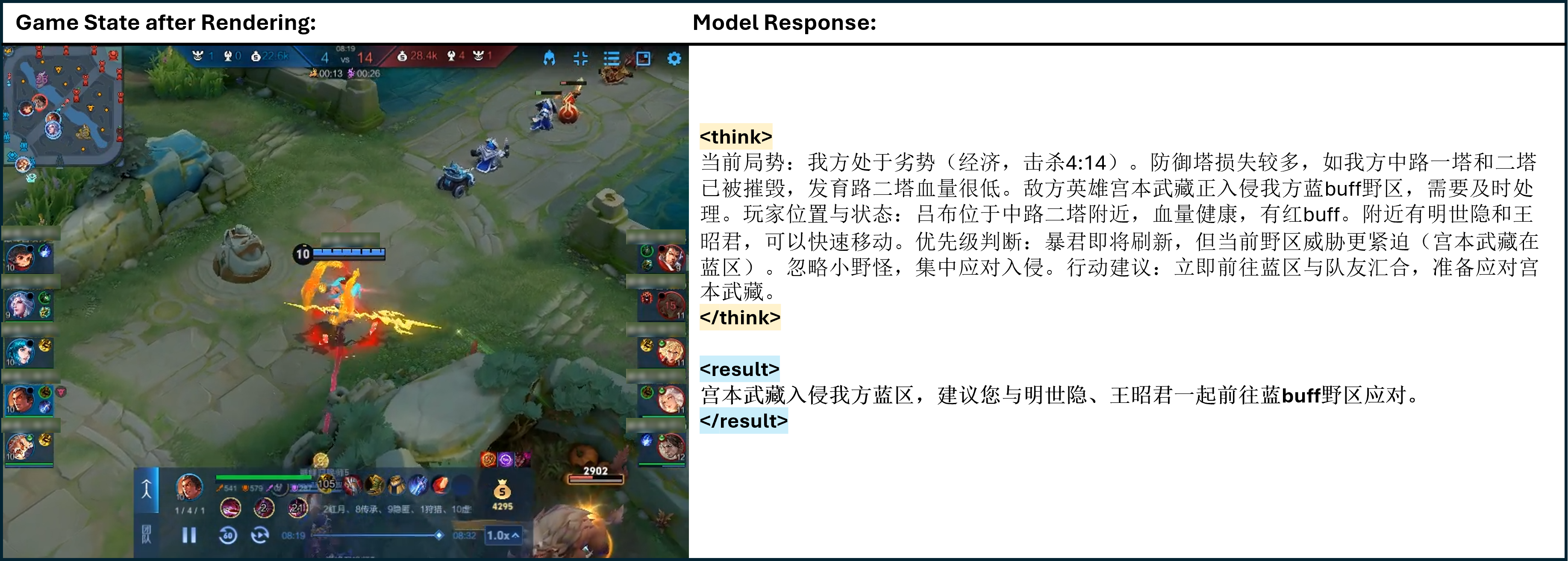
Figure 11: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
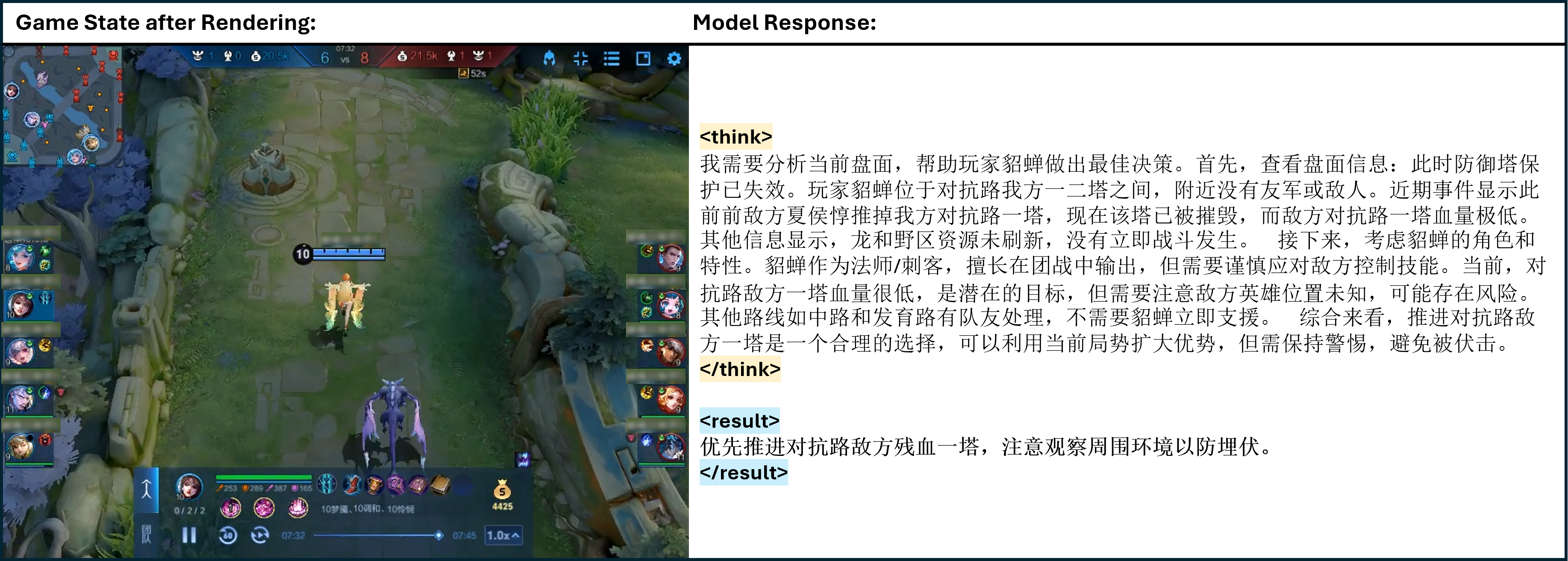
Figure 12: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
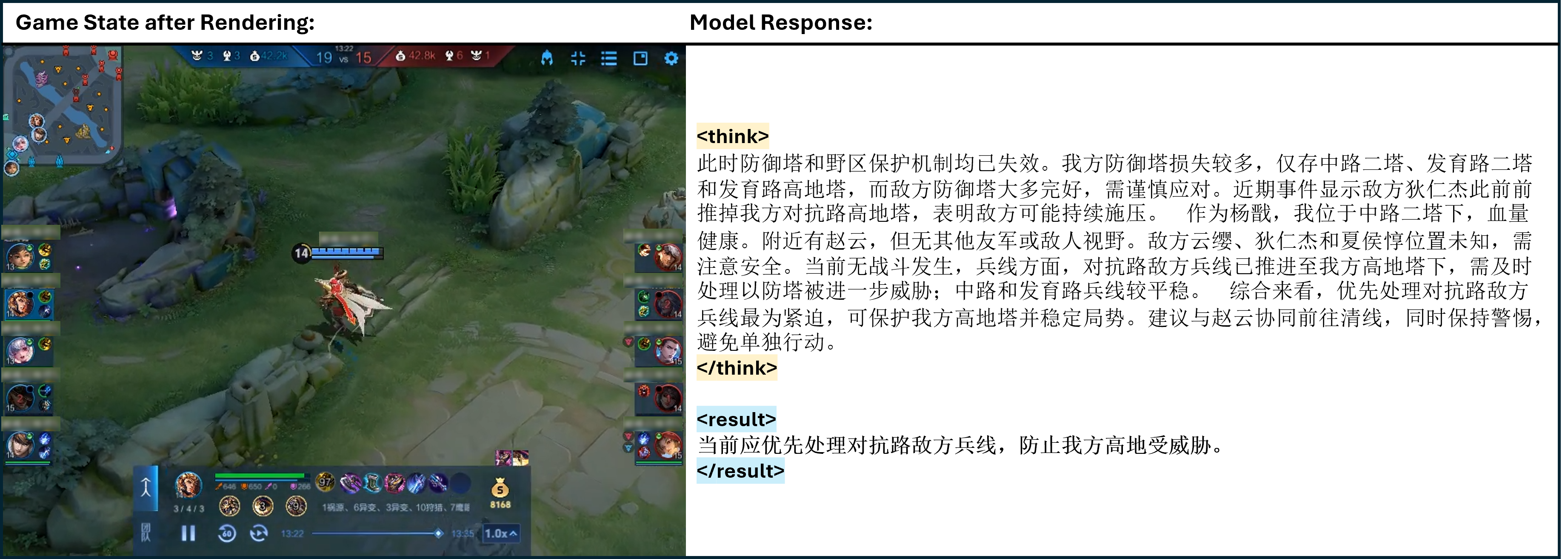
Figure 13: One of the cases of TiG. <think> </think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
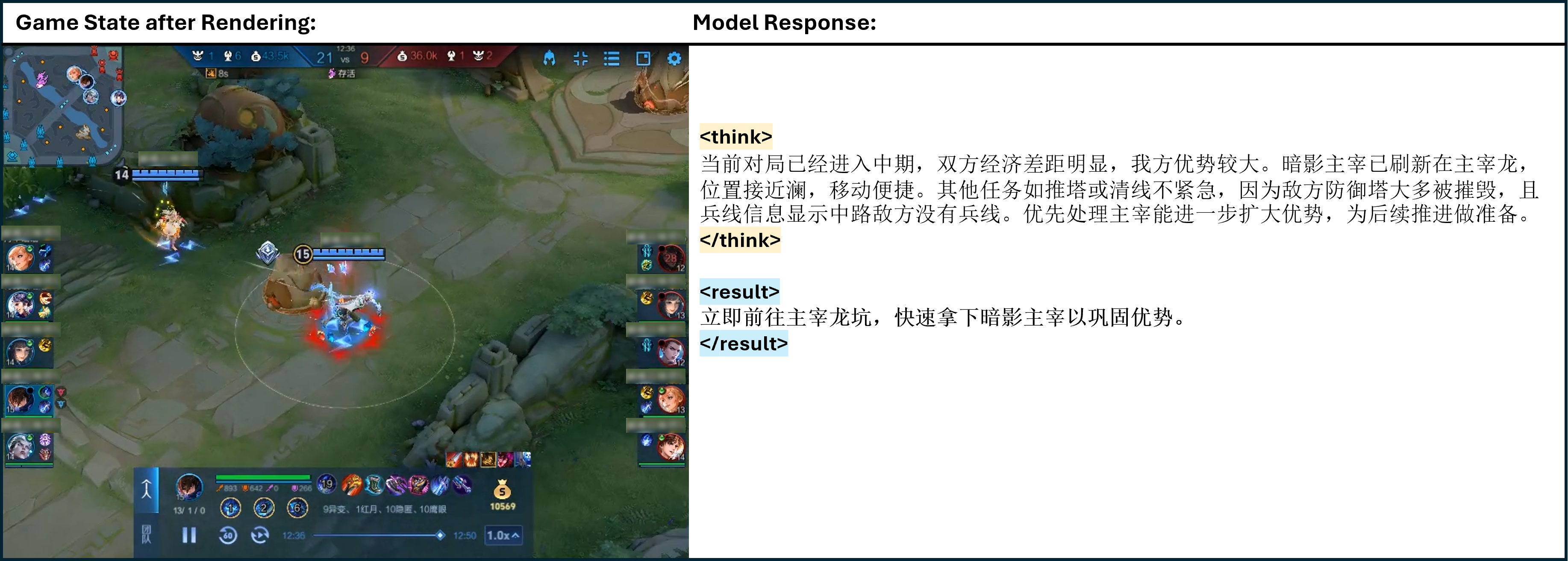
Figure 14: One of the cases of TiG. <think> refers to the thinking process of model output, and <result> </result> refers to the model guidance to the main player in natural language.
Implications and Future Directions
TiG demonstrates that LLMs can acquire procedural knowledge and strategic reasoning through RL-based interaction with game environments, while retaining transparency and interpretability. The framework achieves competitive performance with reduced data and computational requirements, and produces step-by-step natural language explanations for its decisions.
Implications:
- TiG enables the development of AI agents that can both act effectively and explain their reasoning in dynamic environments.
- The approach is scalable and efficient, making it suitable for deployment in real-time applications.
- The language-guided policy paradigm enhances interpretability and trust in AI decision-making.
Future Directions:
- Extending TiG to other interactive domains (e.g., robotics, real-world tasks) to assess generalizability.
- Incorporating multimodal feedback (visual, auditory) for richer procedural learning.
- Investigating long-term reasoning and memory mechanisms for tasks requiring extended temporal abstraction.
Conclusion
The Think-In-Games framework provides a principled approach for bridging the gap between declarative and procedural knowledge in LLMs. By reformulating RL as a language modeling task and leveraging GRPO, TiG enables LLMs to develop strategic reasoning capabilities through direct interaction with game environments. The framework achieves strong empirical results, preserves general language abilities, and enhances interpretability, representing a significant step toward more capable and transparent AI agents in complex, interactive domains.

