- The paper introduces Wan-Alpha, a framework that jointly learns RGB and alpha channels to synthesize high-quality, transparent videos.
- It utilizes a VAE with causal 3D convolutions and a diffusion transformer trained with multiple loss functions for precise edge and perceptual detail.
- Experimental results show improved visual fidelity and a 15-fold efficiency gain compared to TransPixeler, despite some remaining artifacts.
Wan-Alpha: High-Quality Text-to-Video Generation with Alpha Channel
Introduction
The research presented in "Wan-Alpha: High-Quality Text-to-Video Generation with Alpha Channel" (2509.24979) focuses on RGBA video generation—a specialized modality incorporating an alpha channel for transparency—that is increasingly pertinent for applications like video editing and game development. Despite its utility, RGBA video generation has suffered from limited visual quality and dataset scarcity. The paper proposes the novel Wan-Alpha framework, which jointly learns RGB and alpha channels to create high-quality transparent videos, surpassing current state-of-the-art models in realism and transparency rendering.

Figure 1: Qualitative results of video generation using Wan-Alpha. Our model successfully generates various scenes with accurate and clearly rendered transparency. Notably, it can synthesize diverse semi-transparent objects, glowing effects, and fine-grained details such as hair.
Methodology
Variational Autoencoder (VAE)
A VAE forms the backbone of Wan-Alpha's approach, encoding both RGB and alpha channels into a unified latent space. The architecture employs a causal 3D convolution within a novel feature merge block to integrate RGB and alpha features efficiently. This block facilitates computational cost reduction while maintaining temporal consistency across video frames (Figure 2).
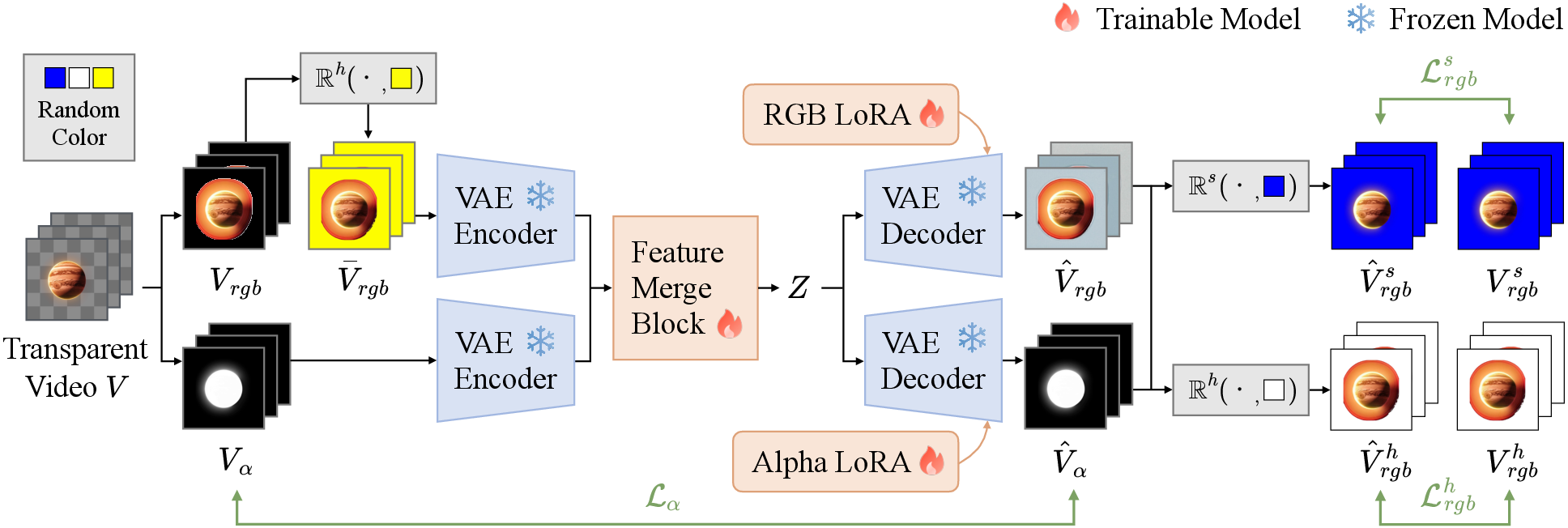
Figure 3: The overall architecture of VAE. The transparent video V is split into the RGB video Vrgb and the alpha video Vα.

Figure 2: The detailed architecture for the feature merge block. RGB and alpha features are concatenated and fused by a causal 3D convolution. Then, we use several causal residual blocks and attention layers.
The VAE utilizes multiple loss functions, including perceptual and edge losses alongside the L1-norm, to ensure the generation of videos with precise alpha channel details.
Text-to-Video Training Framework
Following VAE encoding, the model employs a diffusion transformer trained with the DoRA module, which enhances semantic alignment and video generation quality (Figure 4). The training framework leverages a comprehensive RGBA matting dataset to improve video diversity and resolution, integrating high-resolution footage with diverse objects and motion to support qualitative output.
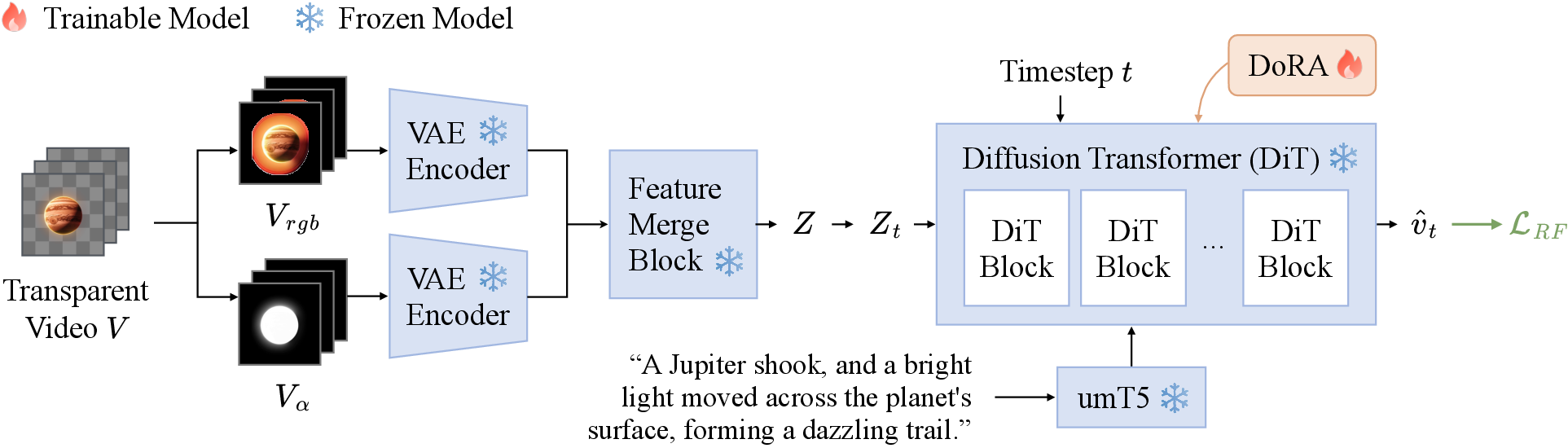
Figure 4: Our text-to-video generation training framework. Transparent videos are first encoded into latents using our VAE, and then a diffusion transformer is trained on these latents using DoRA.
Dataset
The dataset underpinning Wan-Alpha's training is curated from multiple matting datasets and internet sources, prioritizing smooth motion and high-resolution videos. The carefully annotated captions ensure semantic consistency, while labels detail attributes such as motion speed and artistic style, providing comprehensive context for training.

Figure 5: A video from our RGBA text-to-video generation training dataset. In the zoomed-in areas, we can see that this transparent video has complex edges, such as the hair, and each frame has accurate alpha channel.
Experimental Results
Compared against TransPixeler, Wan-Alpha demonstrates superior visual quality, sharp alpha edges, and generates realistic transparent effects across varied contexts (Figures 10-16). Notably, it achieves high fidelity video generation with significantly reduced computation time compared to open-source and proprietary TransPixeler versions, demonstrating an approximate 15-fold increase in efficiency for generating similar output on identical hardware.




Figure 6: The video generated by TransPixeler (open), TransPixeler (close), and Wan-Alpha. At the bottom of the figure, we provide the visualization of one frame from each of the three videos, respectively.
Limitations and Future Work
While Wan-Alpha advances the field of RGBA video generation notably, it still encounters issues such as unintended background artifacts and inaccurate alpha channel rendering in some scenarios (Figures 19 and 20). Work is underway to refine these aspects, with future versions expected to enhance robustness and visual consistency.
Conclusion
Wan-Alpha provides a robust framework for high-quality RGBA video generation, improving upon previous models by integrating transparency directly into the RGB latent space. By releasing a pre-trained model, the authors aim to empower the AIGC community, facilitating new applications across industries that demand high visual fidelity and transparency.
The implications of Wan-Alpha are vast, suggesting enhanced capabilities in video-based applications such as augmented reality and visual effects, with its efficient text-to-video generation serving as a valuable asset in digital content production.