- The paper introduces an efficient diffusion-based video generation framework that uses block linear attention and constant-memory caching to reduce complexity and computational cost.
- It employs rotary position embeddings and a temporal convolution in Mix-FFN for stable training and effective temporal feature aggregation.
- The model achieves minute-long, high-resolution video synthesis with 8x lower latency and significantly reduced training cost compared to state-of-the-art methods.
Introduction and Motivation
SANA-Video presents a diffusion-based video generation framework that addresses the computational bottlenecks inherent in high-resolution, long-duration video synthesis. The model is designed to operate efficiently on both cloud and edge devices, leveraging linear attention mechanisms and a constant-memory key-value (KV) cache to enable minute-length video generation at 720×1280 resolution. The approach is motivated by the prohibitive resource requirements of contemporary video diffusion models, which often scale quadratically with sequence length and resolution, resulting in slow inference and high training costs. SANA-Video achieves competitive quality and semantic alignment with state-of-the-art models while being significantly faster and more resource-efficient.
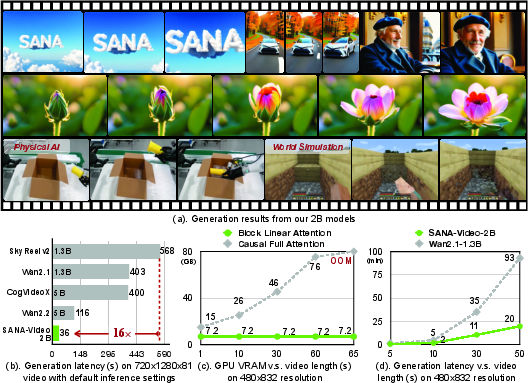
Figure 1: SANA-Video generates high-resolution videos with fixed memory and low latency, outperforming quadratic attention models in efficiency.
Architecture and Core Innovations
SANA-Video extends the SANA linear DiT architecture to the video domain, replacing all self-attention modules with ReLU-based linear attention, reducing complexity from O(N2) to O(N). This is critical for handling the large token counts in video generation. The model incorporates two key enhancements:
- Rotary Position Embeddings (RoPE): RoPE is applied post-ReLU activation to preserve positional information and stabilize training. The denominator in the linear attention computation omits RoPE to maintain non-negativity and prevent numerical instability.
- Temporal 1D Convolution in Mix-FFN: A shortcut-connected temporal convolution is added to the Mix-FFN, enabling effective temporal feature aggregation and facilitating adaptation from pre-trained image models to video generation.
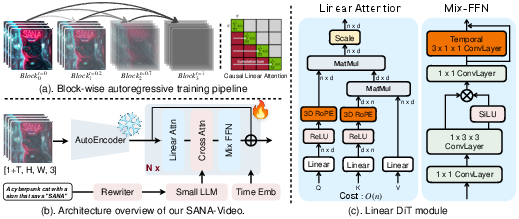
Figure 2: SANA-Video pipeline: block-wise autoregressive training with block causal KV cache, autoencoder, re-writer, linear DiT, and text encoder.
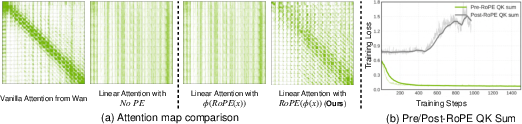
Figure 3: Linear attention with RoPE yields sparser, localized attention maps and stable training loss compared to vanilla softmax attention.
Block Linear Attention and Constant-Memory KV Cache
The block linear attention module is central to SANA-Video's ability to generate long videos efficiently. By reformulating causal linear attention, the model maintains a global context with a fixed-size KV cache, storing cumulative sums of attention states and keys. This enables constant memory and compute per token, independent of sequence length, in contrast to vanilla attention which scales linearly or quadratically.
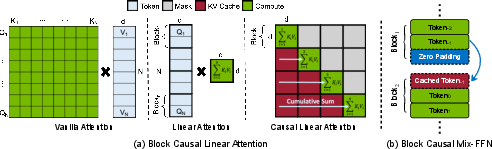
Figure 4: Comparison of attention mechanisms and illustration of block causal Mix-FFN for adjacent block processing.
The block-wise autoregressive training paradigm utilizes a monotonically increasing SNR sampler for timestep selection, improving convergence and consistency across blocks. An improved self-forcing strategy further mitigates exposure bias by aligning training and inference conditions, leveraging the global KV cache to support long-context rollouts.
Training Strategy and Data Pipeline
SANA-Video employs a three-stage training strategy:
- VAE Adaptation: Efficiently adapts pre-trained T2I models to new video VAEs, using Wan-VAE for 480P and DCAE-V for 720P, the latter providing higher compression for efficient high-resolution generation.
- Continued Pre-Training: Initializes from a pre-trained T2I model, adding temporal modules with identity initialization and training in a coarse-to-fine manner (low-res/short videos to high-res/long videos).
- Autoregressive Block Training: Trains the autoregressive module with the block linear attention, using the monotonically increasing SNR sampler and improved self-forcing.
The data pipeline incorporates multi-stage filtering for motion (Unimatch, VMAF), aesthetics (DOVER), and saturation (OpenCV), with LLM-based caption rewriting (Qwen2.5-VL) to ensure prompt-clip alignment. Human-preferred SFT data is used for final fine-tuning.
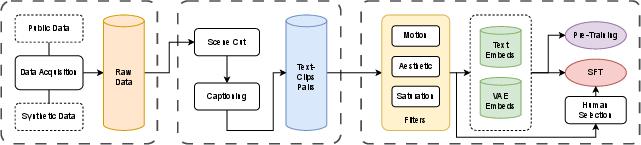
Figure 5: Multi-stage data filtering pipeline for SANA-Video training.
SANA-Video demonstrates strong efficiency and quality metrics:
- Latency: Generates a 5s 720p video in 36s on H100, and 29s on RTX 5090 with NVFP4 quantization (2.4× speedup over BF16).
- Training Cost: 12 days on 64 H100 GPUs, only 1% of MovieGen's cost.
- Benchmark Scores: Achieves 83.71 (T2V) and 88.02 (I2V) total scores on VBench, outperforming or matching larger models (Wan2.1-14B, Open-Sora-2.0) with 8× lower latency.
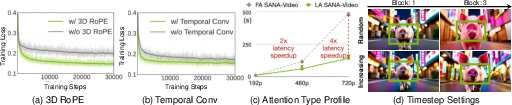
Figure 6: Ablation studies: 3D RoPE and temporal convolution improve training loss; linear attention yields lower latency; monotonically increasing SNR sampler enhances block consistency.
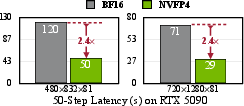
Figure 7: Latency comparison of SANA-Video on BF16 and NVFP4 precision.
Qualitative comparisons show SANA-Video matches or exceeds state-of-the-art models in motion control and semantic alignment for both T2V and I2V tasks.

Figure 8: SANA-Video achieves comparable motion control and semantic alignment in T2V compared to SOTA small diffusion models.

Figure 9: SANA-Video demonstrates superior motion control and semantic alignment in I2V tasks.

Figure 10: SANA-Video maintains first-frame consistency while generating realistic motion in I2V.

Figure 11: Increasing motion score in prompts leads to larger motion in I2V generation.

Figure 12: SANA-Video generates semantically consistent, minute-long videos.
Applications and Deployment
SANA-Video's unified framework supports T2I, T2V, and I2V tasks with a single model. It is readily adaptable to world model applications, including embodied AI, autonomous driving, and game generation.

Figure 13: SANA-Video applied to world model generation tasks (embodied AI, driving, gaming).
The model is quantized to NVFP4 using SVDQuant, selectively applying 4-bit quantization to attention and feed-forward layers while preserving higher precision in normalization and temporal convolution layers. This enables efficient deployment on edge devices without perceptible quality loss.
Theoretical and Practical Implications
SANA-Video demonstrates that linear attention, when combined with block-wise autoregressive training and constant-memory KV caching, can scale video generation to high resolutions and long durations with minimal resource requirements. The approach challenges the necessity of quadratic attention for global context modeling in video synthesis, showing that linear mechanisms can achieve comparable quality and semantic alignment. The data pipeline and training strategies further reduce the cost and improve the robustness of the model.
The practical implications are substantial: SANA-Video enables real-time, high-quality video generation on commodity hardware, democratizing access to advanced generative models. Theoretically, the work suggests new directions for efficient sequence modeling, particularly in multimodal and long-context domains.
Future Directions
Potential future developments include:
- Extending block linear attention to other modalities (audio, multimodal fusion).
- Further compression and quantization for mobile deployment.
- Exploration of hybrid attention mechanisms combining linear and sparse global attention.
- Integration with reinforcement learning for interactive video generation and simulation.
Conclusion
SANA-Video introduces a resource-efficient, high-quality video generation framework leveraging linear attention and block-wise autoregressive training. The model achieves competitive performance with state-of-the-art diffusion models at a fraction of the computational cost and latency, supporting minute-long, high-resolution video synthesis on both cloud and edge devices. The innovations in attention mechanisms, training strategies, and data curation set a new standard for scalable video generation and open avenues for future research in efficient generative modeling.