- The paper introduces MagicVideo, leveraging a latent diffusion framework to reduce computational complexity by operating in a low-dimensional latent space.
- It employs a novel 3D U-Net architecture with a frame-wise adaptor and directed temporal attention to ensure high inter-frame consistency.
- Experimental results demonstrate superior quality with metrics like FVD and FID, paving the way for efficient text-to-video applications.
MagicVideo: Efficient Video Generation With Latent Diffusion Models
The paper "MagicVideo: Efficient Video Generation With Latent Diffusion Models" presents an innovative approach for generating video content from textual descriptions using latent diffusion models. This method offers significant computational efficiencies while maintaining high-quality outputs, distinguishing itself from other models operating directly in the RGB space.
Latent Diffusion Model for Video Generation
MagicVideo employs a latent diffusion model (LDM) framework for generating videos, which is a marked shift from traditional models that operate in the high-dimensional RGB space. By leveraging a pre-trained variational autoencoder (VAE), MagicVideo reduces video data to a low-dimensional latent space. This transformation allows the model to focus computational resources on learning the distributions of latent features rather than raw pixel data.
Key innovations in MagicVideo include a novel 3D U-Net architecture tailored for video data processing. This architecture features both a lightweight frame-wise adaptor to manage image-to-video distribution transitions and a directed temporal attention mechanism to capture frame-to-frame temporal dependencies. These components enable the model to efficiently utilize existing text-to-image synaptic weights, effectively accelerating both training and inference stages.
The efficiency gains are substantial. MagicVideo operates at 256x256 spatial resolution on a single GPU, requiring approximately 64x fewer floating point operations (FLOPs) compared to predecessor models like Video Diffusion Models (VDMs).
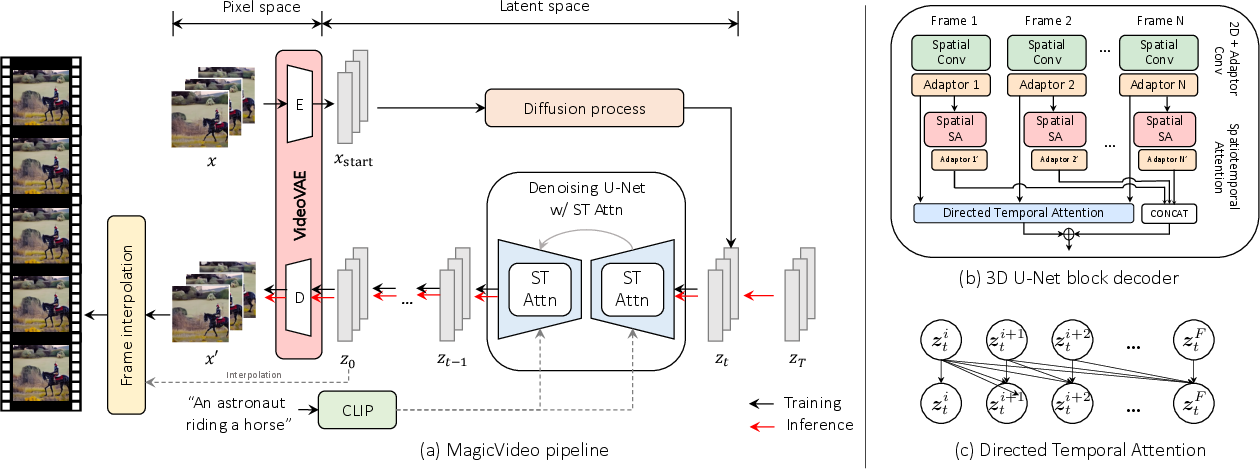
Figure 1: The overall framework of MagicVideo, showcasing its training and inference phases alongside the novel spatiotemporal attention modules.
Key Designs and Innovations
Video Distribution Adaptor
The paper introduces a video distribution adaptor, which substitutes spatial and temporal modeling layers with a more efficient solution. Traditional 3D convolutions are computationally intense; thus, MagicVideo employs a dual attention mechanism. This mechanism operates across both spatial and temporal dimensions without the overhead of 3D convolution layers. Additionally, the adaptor adjusts frame-wise feature distributions using minimal parameters, thus maintaining temporal coherence without a resource-heavy 1D convolution layer.
Directed Temporal Attention
The directed temporal attention module is introduced to better model temporal dynamics within video sequences. Unlike conventional self-attention, which is bi-directional, the directed attention module is designed to respect the chronological sequence of frames. Future frames are computed with the knowledge of preceding ones, ensuring temporal consistency while improving the synthesis of motion dynamics.


Figure 2: Illustration of effects of the attention mechanisms. Spatial attention helps generate diverse frame contents, and temporal attention tends to guarantee cross-frame consistency.
VideoVAE Auto-Encoder
MagicVideo proposes an improved VideoVAE, dedicated to eliminating pixel dithering artifacts that often degrade video quality when using conventional VAEs. By incorporating temporal knowledge during decoding, the VideoVAE allows for generating visually consistent frames across sequences, thereby producing videos with coherent high-frequency content.
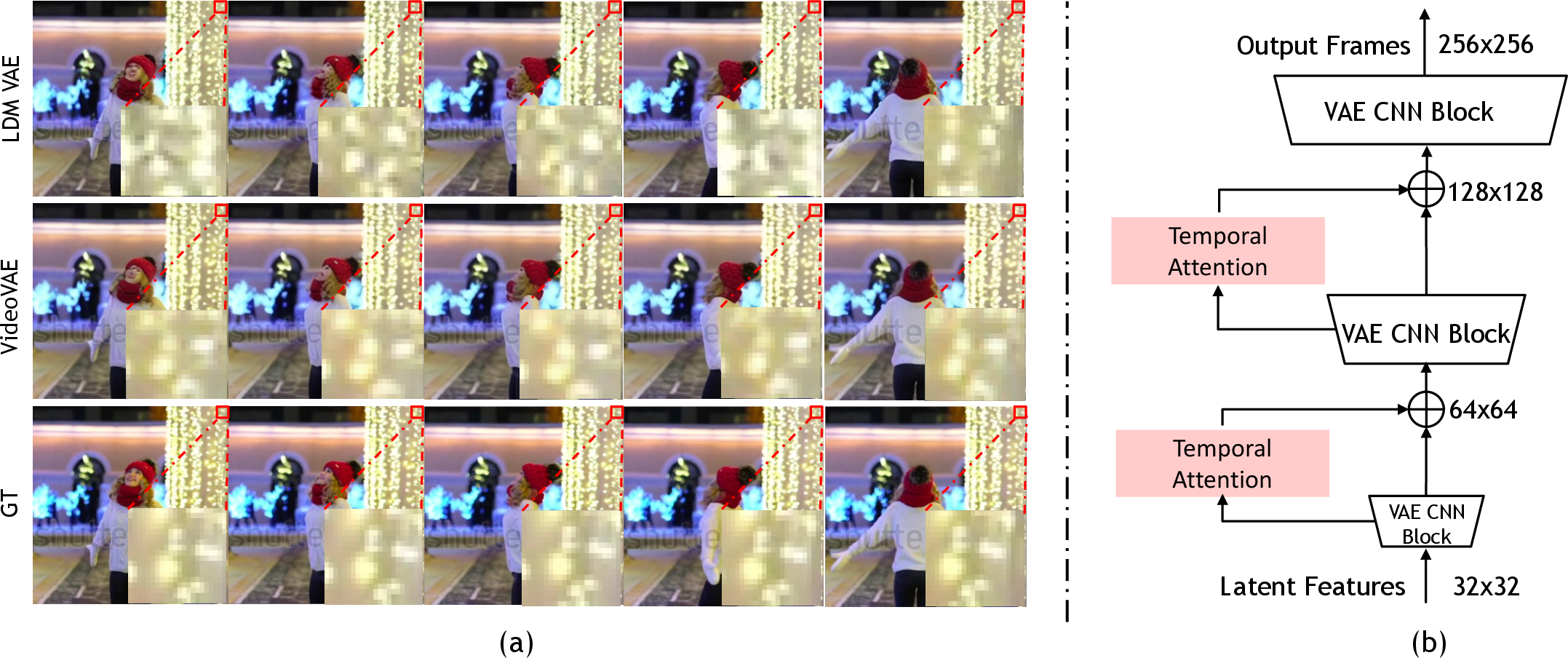
Figure 3: VideoVAE architecture effectively reduces pixel dithering artifacts in generated video frames.
Experiments and Results
Through comprehensive experiments and qualitative analyses, MagicVideo demonstrates superior video generation capabilities both in terms of quality and computational efficiency. The method outperforms existing state-of-the-art models on metrics such as Frechet Video Distance (FVD) and Frechet Inception Distance (FID).
Qualitative evaluations highlight MagicVideo's ability to generate both realistic and imaginative video content that aligns well with input text prompts. The generated videos maintain high inter-frame consistency, featuring smooth transitions and cohesive visual narratives.

Figure 4: Qualitative results comparison with recent strong methods: VDM, CogVideo, and Make-A-Video.
Applications and Future Work
MagicVideo's framework lends itself to several applications, including image-to-video production, video editing with text prompts, and generating video variants based on existing content. The model's foundational efficiency suggests potential for further expansion into real-time applications or more complex content generation tasks. Future improvements could involve scaling the model to support higher resolutions or integrating more intricate temporal dynamics modeling.

Figure 5: Applications based on MagicVideo demonstrate its versatility across various video generation scenarios.
Conclusion
MagicVideo introduces a novel framework for text-to-video generation, focusing on reducing computational costs while maintaining high video quality. By employing latent diffusion models and innovative architectural components, it achieves superior performance over existing methods. The paper’s contributions suggest promising directions for future research in efficient video synthesis from textual descriptions, potentially guiding advances in automated video content creation and media generation technologies.