- The paper demonstrates that modulating policy gradients with entropy-driven adjustments enhances LLM agents’ performance on long-horizon tasks.
- It introduces Self-Calibrating Gradient Scaling to tailor updates based on action uncertainty, promoting stability and efficient exploration.
- Experimental results on benchmarks like WebShop and Deep Search reveal improved sample efficiency and robust exploration compared to standard RL approaches.
Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
Introduction
The paper "Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents" investigates improving the learning process of LLMs when employed as autonomous agents performing long-horizon tasks. This involves tackling challenges such as sparse reward systems, where typical reinforcement learning (RL) agents struggle because credit assignment to intermediate actions is hampered without consistent feedback.
Recent approaches have attempted to resolve these issues by either densifying reward signals through processes like inverse reinforcement learning or Process Reward Models (PRMs), which provide more frequent feedback. However, these methods face significant limitations concerning scalability, reliance on human annotations, susceptibility to noise, and poor generalization to unseen tasks.
The proposed Entropy-Modulated Policy Gradients (EMPG) framework diverges from these methods by modifying the learning signal itself in response to intrinsic uncertainty within the agent's policy. This is done by re-calibrating the magnitude of policy gradients according to confidence levels, thereby providing a more stable and efficient learning process. EMPG amplifies updates for confident correct actions, penalizes confident errors, and reins in updates stemming from uncertain actions, thus stabilizing exploration. Alongside this, EMPG integrates a Future Clarity Bonus, which motivates agents to pursue paths leading to clearer and predictable outcomes.
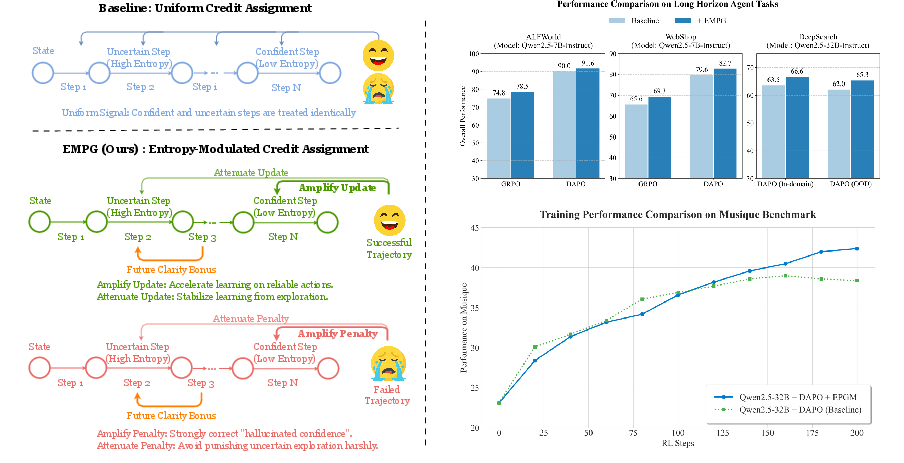
Figure 1: Overview of the EMPG mechanism and its algorithm performance. Left: Conceptual diagram contrasting the uniform credit assignment of baseline methods with EMPG's confidence-modulated signal. Right: Final performance comparison on key long-horizon benchmarks showing EMPG's superiority, along with the training dynamics on Musique that highlight its ability to achieve sustained improvement and avoid the baseline's performance plateau.
Theoretical Motivation
EMPG builds upon a key insight into the nature of policy gradients in RL. For a conventional softmax-based policy, the expected norm of its gradient is intrinsically linked to its entropy. High entropy implies large gradient updates typically required for exploratory actions, whereas low entropy dictates small updates for more certain actions. This coupling presents a dual challenge: confident actions that should be robustly reinforced receive minimal updates, limiting learning speed; whereas uncertain exploratory steps can introduce substantial, destabilizing gradients.
To address this, EMPG introduces Self-Calibrating Gradient Scaling, which dynamically adjusts gradient magnitudes based on the entropy of actions, ensuring efficient reinforcement of critical steps while mitigating instability from exploratory ones. Additionally, the Future Clarity Bonus redirects the agent's exploration towards actions that promise predictable paths, aligning with information theory principles like Empowerment, which elicits behaviors that maximize future certainty.
Framework Implementation
The implementation of EMPG involves quantifying step-wise uncertainty by measuring entropy averaged over token-level predictions for each "reason-then-act" step. These entropy values guide the modulation of conventional advantage functions used in RL settings. The novel modulated advantage consists of:
- Self-Calibrating Gradient Scaling (g(H)): Applies a scaling factor to trajectory advantages based on step-level confidence and uncertainty.
- Future Clarity Bonus (f(H)): Adds an intrinsic reward for selecting actions that lead to more predictable next states.
This process transforms trajectory-level learning signals into richer step-wise guidance, allowing precise feedback adjustment by rewarding or penalizing actions based on their potential clarity.
Experimental Results
EMPG was subjected to tests across various benchmarks, including WebShop, ALFWorld, and Deep Search. In these experiments, EMPG exhibited substantial performance enhancements over existing strong policy optimization baselines, demonstrating superior sample efficiency and generalization capabilities.
Numerical analysis revealed EMPG’s ability to surpass conventional performance plateaus encountered by standard RL frameworks, indicating that EMPG successfully refines agent learning trajectories beyond existing limitations. By leveraging intrinsic uncertainty, it compounds performance gains with enhanced training stability, notably improving robustness against erratic policy collapses often seen in extended training phases.
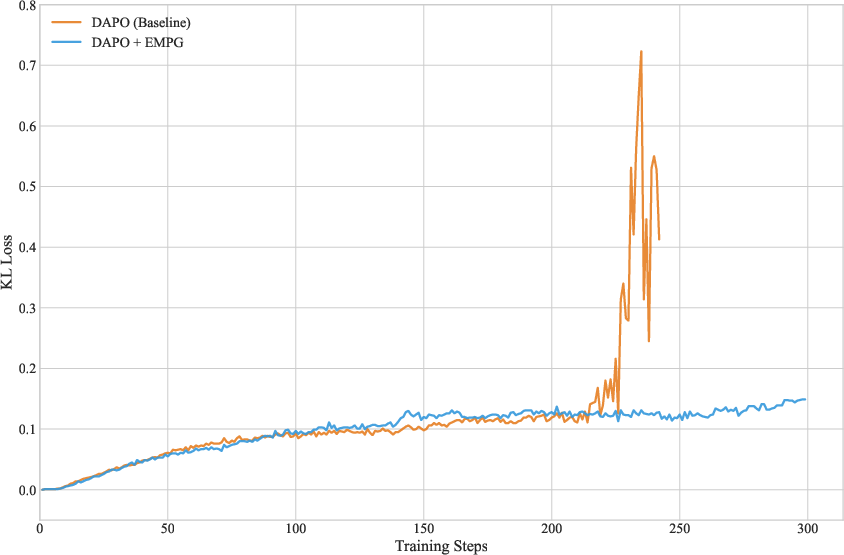
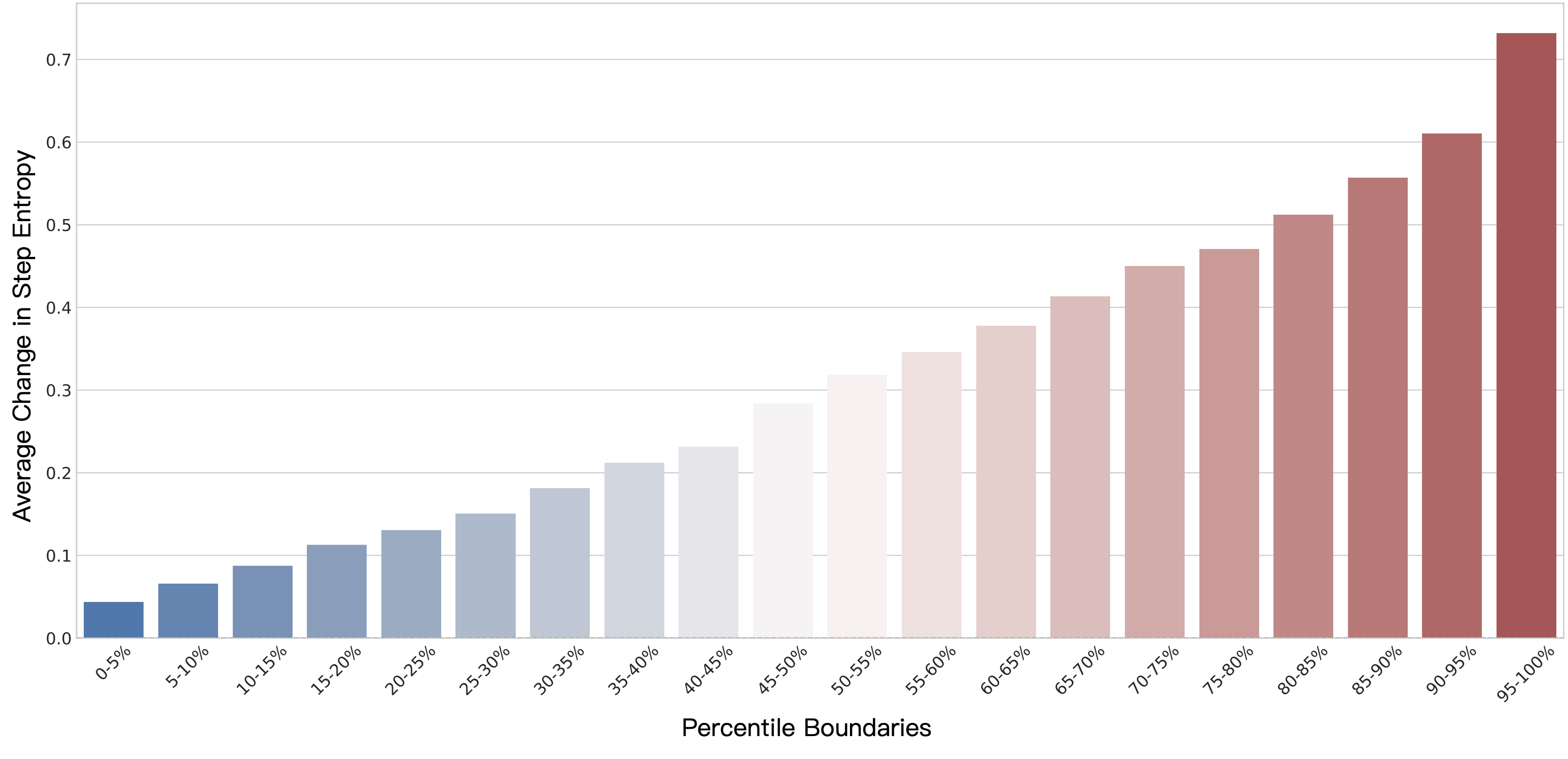
Figure 2: KL Loss dynamics during training for the Qwen2.5-32B-Instruct model. The DAPO baseline (orange) suffers from late-stage instability, evidenced by the sharp, erratic spike in KL Loss. The EMPG-enhanced model (blue) remains stable throughout, showcasing its robustness.
Conclusion
EMPG fundamentally redefines learning dynamics in long-horizon tasks by integrating intrinsic uncertainty into the policy gradient framework. It circumvents the limitations of sparse reward systems and cumbersome external feedback models by nurturing stability and encouraging exploration along predictable paths. The novelty lies not only in performance gains but in establishing a foundation for more resilient, self-guided exploratory agents.
Looking forward, the principles established by EMPG could extend to diverse applications, including embodied AI, autonomous navigation, and complex problem-solving environments where uncertainty-guided learning offers far-reaching benefits.

