- The paper proposes a unified diffusion framework that simultaneously models continuous trajectories and discrete events, enabling realistic and controllable multi-agent generation.
- It introduces a joint continuous-discrete diffusion process using a single neural network with dual heads for regression and classification, integrating both Gaussian and multinomial noise.
- Experiments on NBA, NFL, and soccer datasets demonstrate that JointDiff outperforms prior models in scene-level metrics and human perceptual evaluations.
JointDiff: Bridging Continuous and Discrete in Multi-Agent Trajectory Generation
Introduction and Motivation
JointDiff introduces a unified generative framework for multi-agent systems that simultaneously models continuous spatio-temporal trajectories and synchronous discrete events. The motivation stems from the observation that existing generative models in domains such as sports analytics, autonomous driving, and robotics typically treat continuous motion and discrete events (e.g., ball possession, passes) as independent processes. This separation leads to physically implausible generations and limits controllability. JointDiff leverages the expressive power of diffusion models to bridge this gap, enabling joint modeling and controllable generation via semantic guidance signals, including weak-possessor sequences and natural language text.
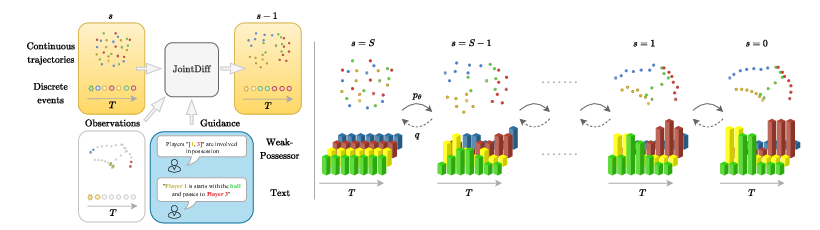
Figure 1: JointDiff jointly generates continuous trajectories and discrete events, with guidance provided through either weak-possessor information or natural language text.
Methodology
Joint Continuous-Discrete Diffusion Process
JointDiff factorizes the forward diffusion process into independent continuous and discrete components, each governed by a shared variance schedule. The continuous trajectories are corrupted via Gaussian noise, while discrete events (e.g., possession) are diffused toward a uniform categorical distribution using multinomial diffusion. The reverse process is parameterized by a single neural network with two heads: a regression head for continuous denoising and a classification head for discrete event prediction. The network is conditioned on the noisy state, partial observations, and optional guidance signals.
The training objective is a weighted combination of the simplified DDPM loss for continuous data and the exact variational bound for discrete data, with a balancing hyperparameter λ ensuring both modalities contribute comparably. During inference, JointDiff employs a hybrid sampling strategy: deterministic DDIM for continuous trajectories and stochastic multinomial sampling for discrete events, with a reduced number of discrete denoising steps to align both modalities.
Controllable Generation via CrossGuid
Controllability is achieved through the CrossGuid module, which injects external guidance signals into the denoising network. Two modalities are supported:
- Weak-Possessor-Guidance (WPG): Conditions generation on a sequence of intended ball possessors, encoded as one-hot vectors and mapped via agent embeddings. The guidance is injected into the ball's representation using multi-head attention.
- Text-Guidance: Conditions generation on natural language prompts, encoded using a frozen T5-Base encoder and projected to the model's dimension. The guidance is injected into all agents' representations via multi-head attention.
CrossGuid is integrated within each Social-Temporal Block, situated between the Temporal Mamba and Social Transformer modules.
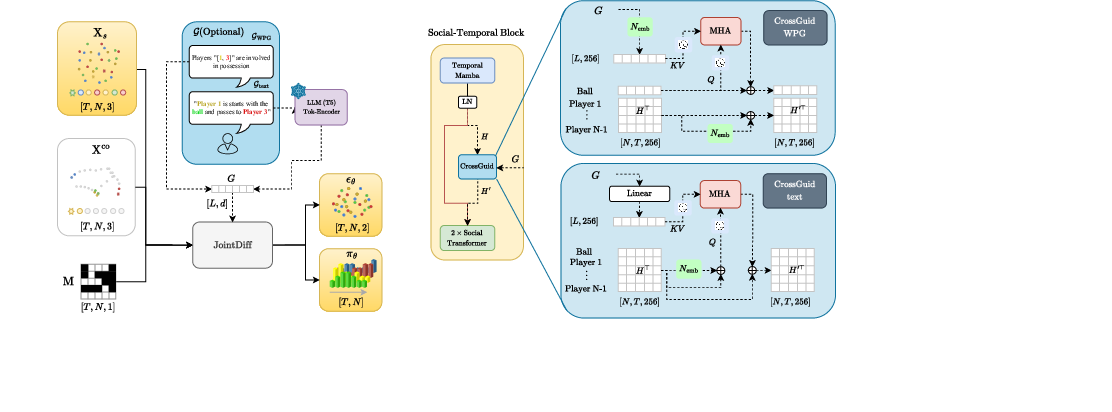
Figure 2: Model Architecture. The pipeline takes noisy states, observed states, mask, and optionally the encoded guidance signal, producing predicted Gaussian noise for trajectories and event probability distributions.
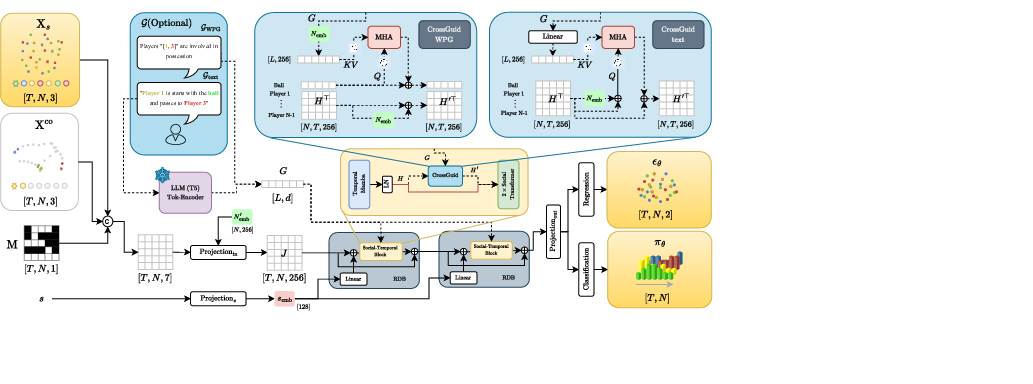
Figure 3: Model Architecture (extended version) detailing the flow of data and guidance signals through the network.
Experimental Evaluation
Datasets and Metrics
JointDiff is evaluated on three public sports datasets: NBA (basketball), NFL (American football), and BundesLiga (soccer), each comprising multi-agent trajectories and event annotations. Possessor events are extracted using a unified geometric heuristic (1.5 meters threshold), validated by analyzing ball direction changes.
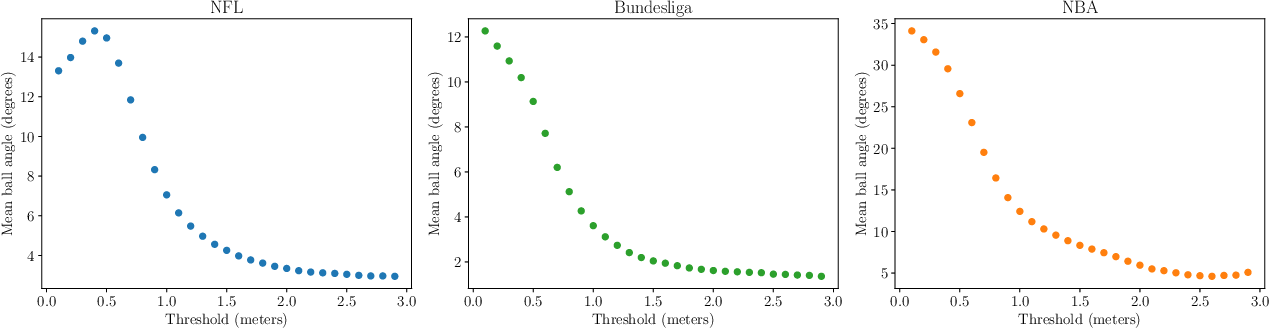
Figure 4: Possession threshold determination. The minimum at 1.5 meters indicates optimal threshold for unified possession detection.
Guidance signals for controllable generation are derived from possessor sequences and curated natural language descriptions, generated via a rule-based pipeline and refined with LLMs.
Completion Generation
JointDiff achieves state-of-the-art performance on both future generation and imputation tasks, outperforming baselines such as MoFlow, U2Diff, and CVAE-based models. The model excels in scene-level metrics (SADE/SFDE), which better capture multi-agent coherence than individual-level ADE/FDE.
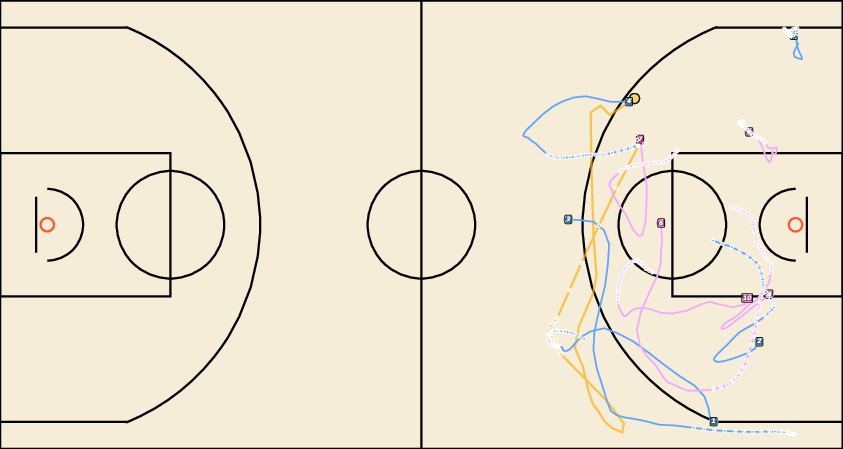
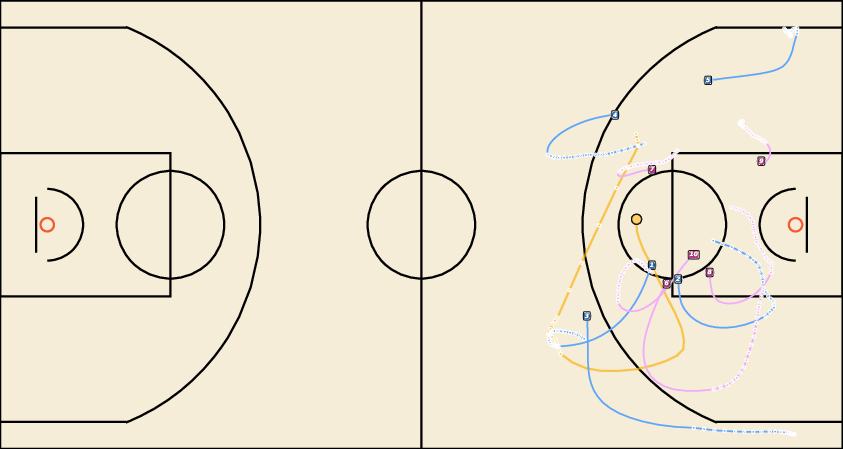
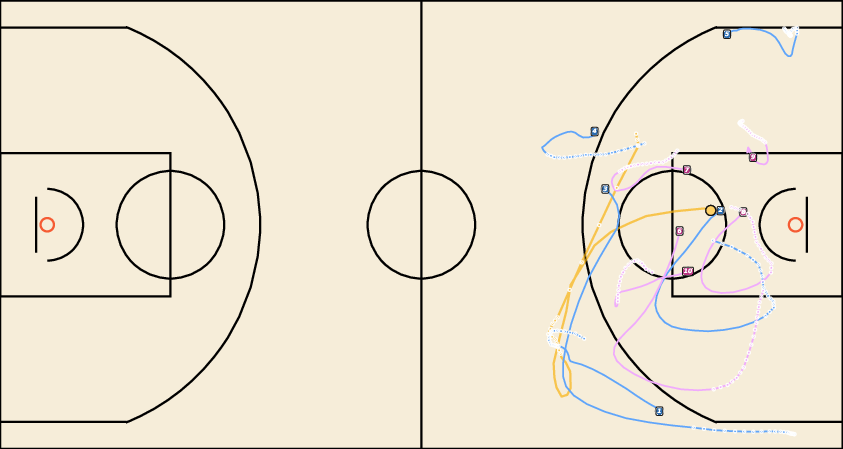
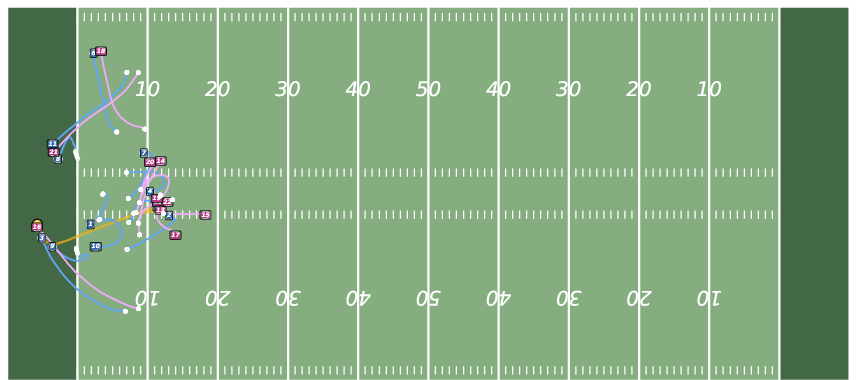
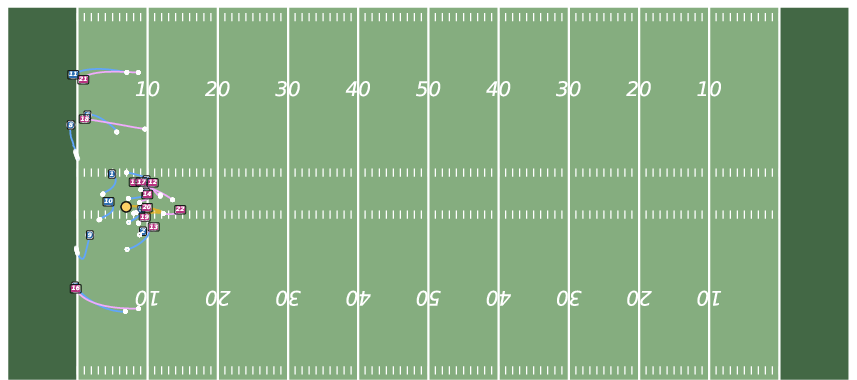
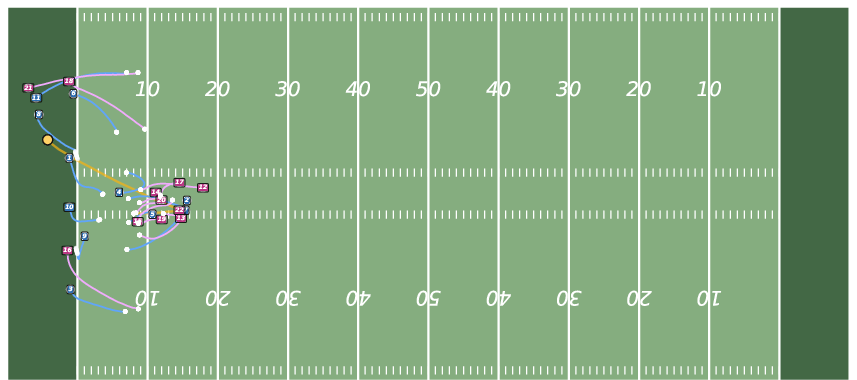
Figure 5: Future Generation on NFL. JointDiff produces more coherent and realistic multi-agent futures compared to MoFlow and U2Diff.
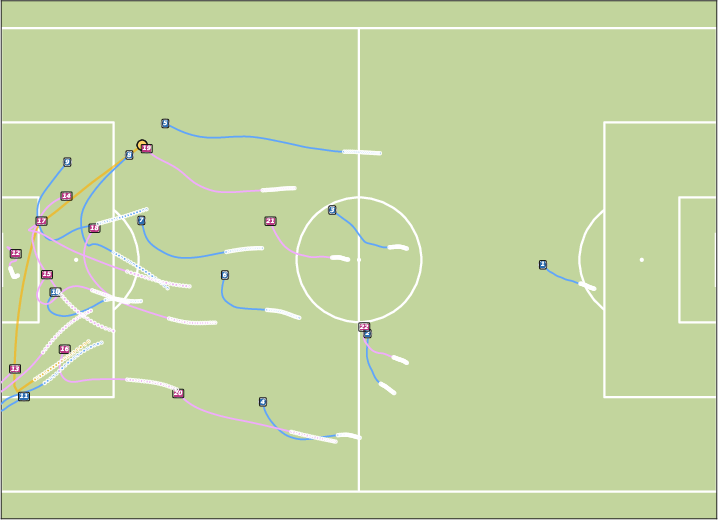
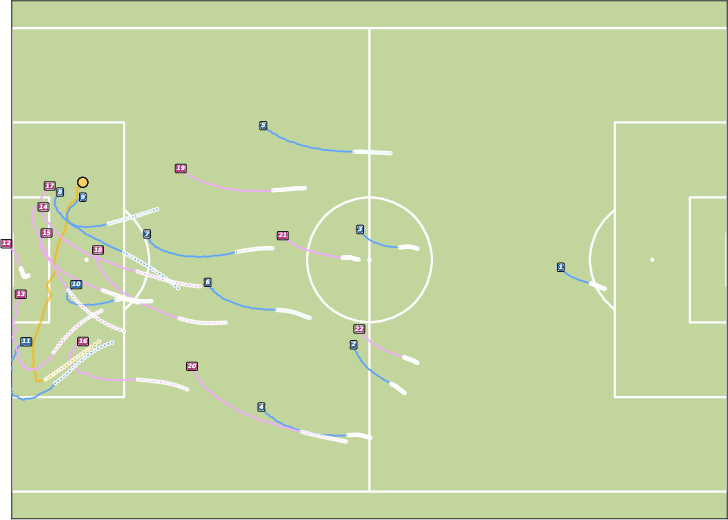
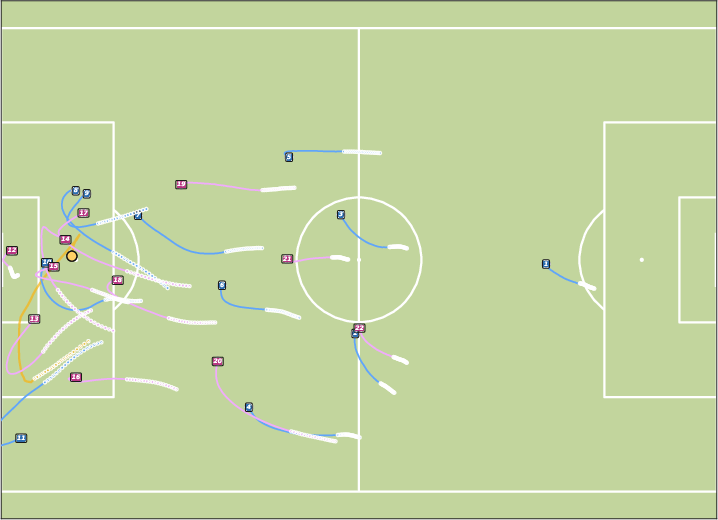
Figure 6: Future Generation on BundesLiga. JointDiff demonstrates superior scene-level consistency in soccer trajectory generation.
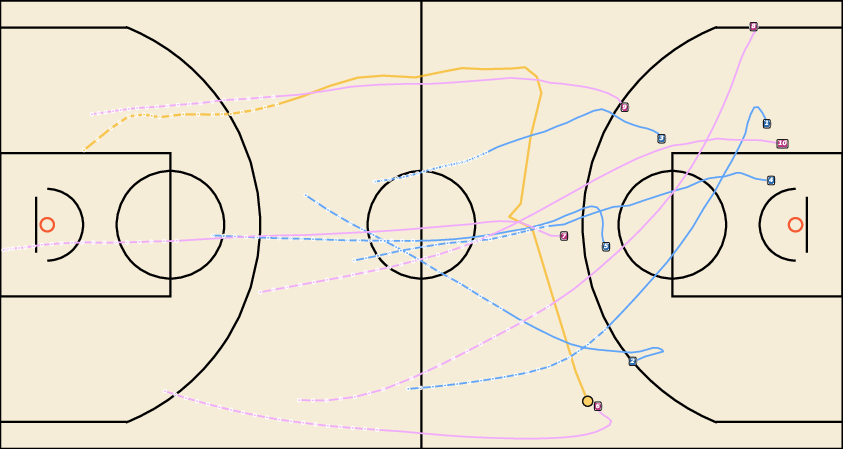
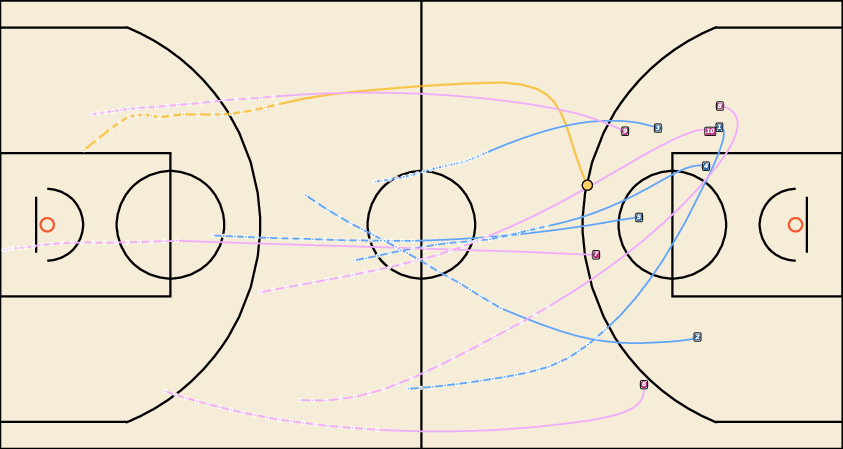
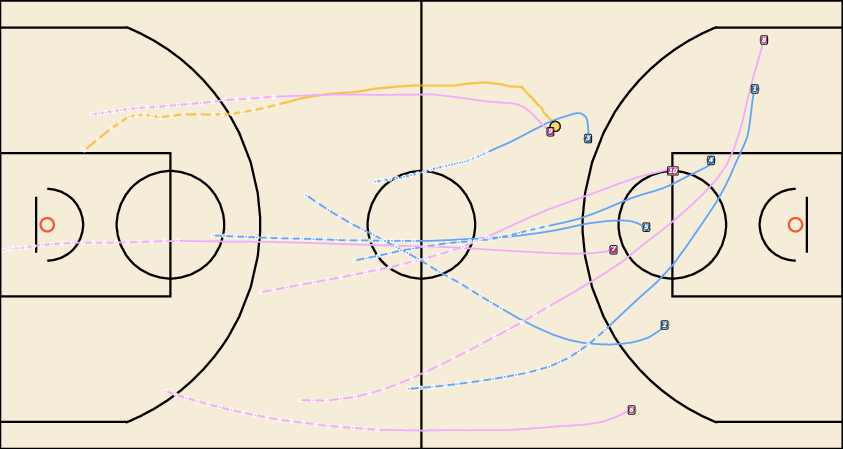
Figure 7: Future Generation on NBA. JointDiff generates plausible basketball plays with accurate agent interactions.
Controllable Generation
JointDiff enables semantic control over generated scenes via WPG and text-guidance. Conditioning on guidance signals improves both trajectory and event accuracy, with text-guidance providing finer control. Ablation studies confirm the advantage of joint modeling over trajectory-only variants.
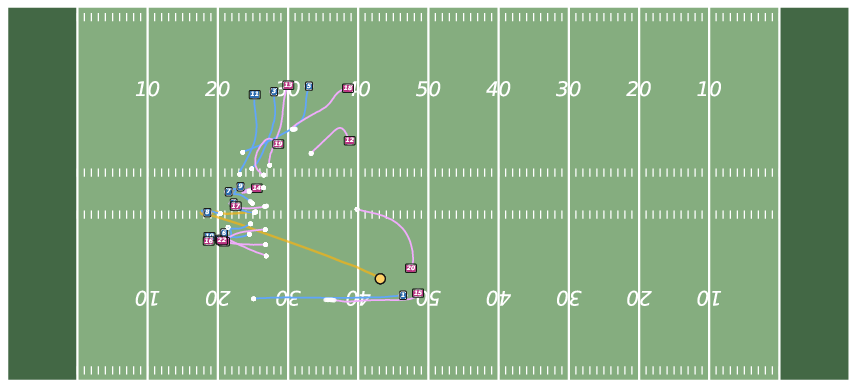
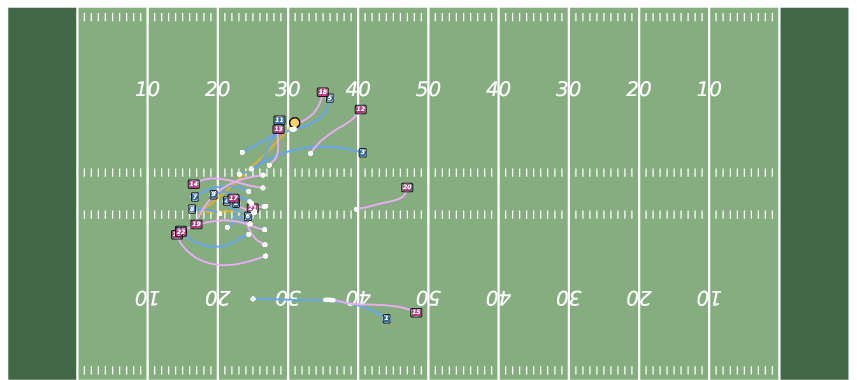
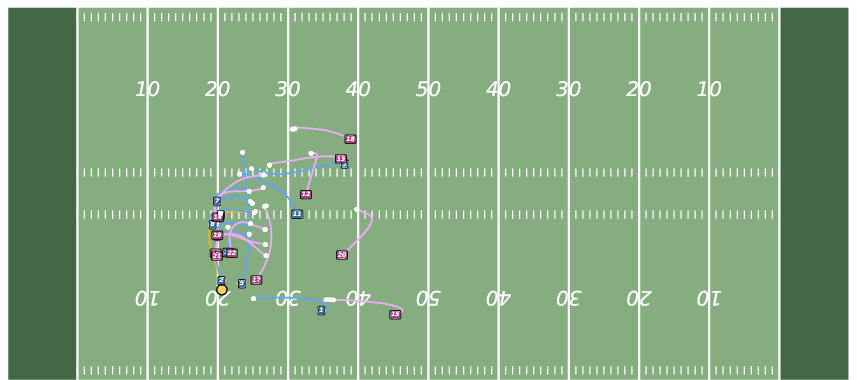
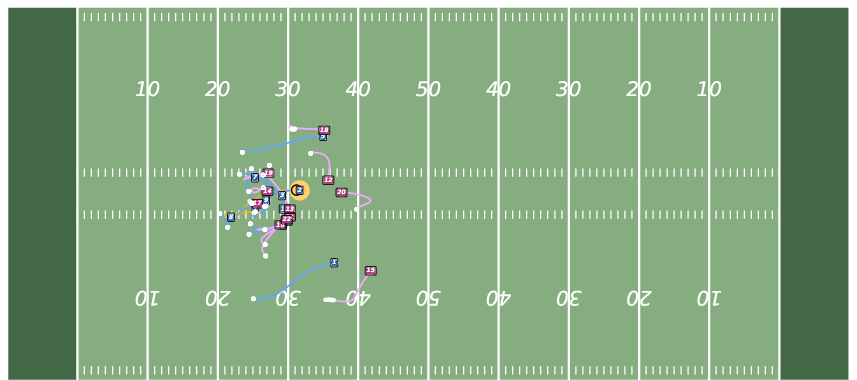
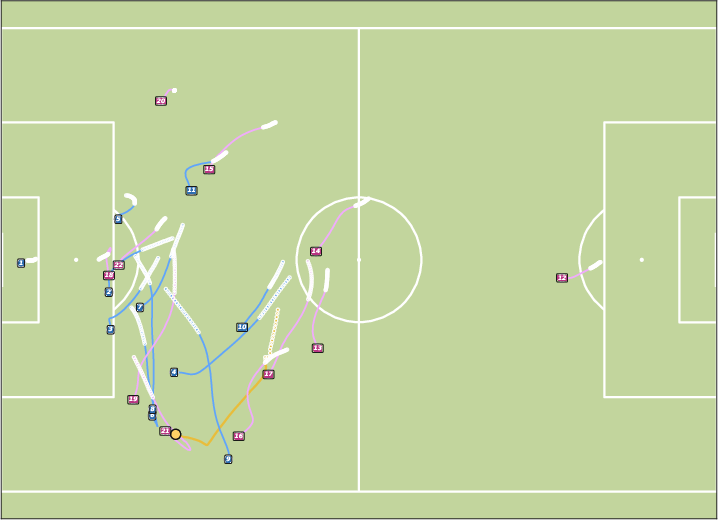

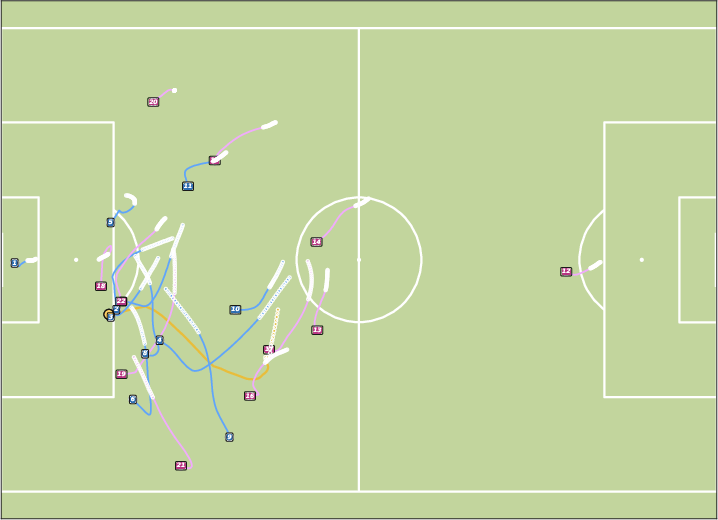
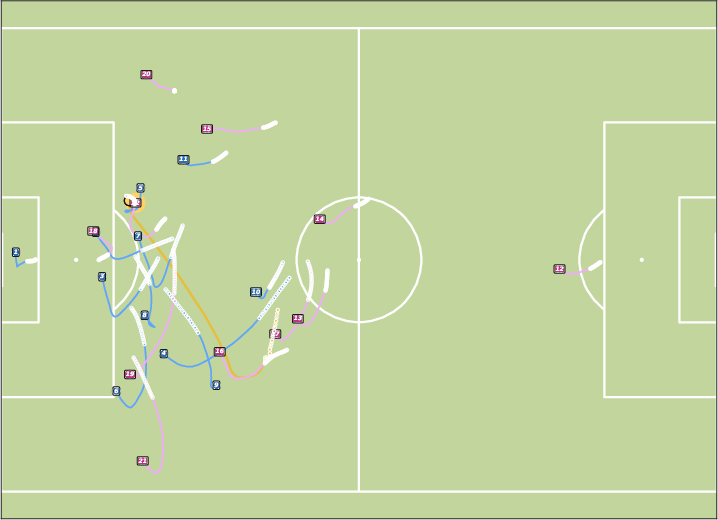
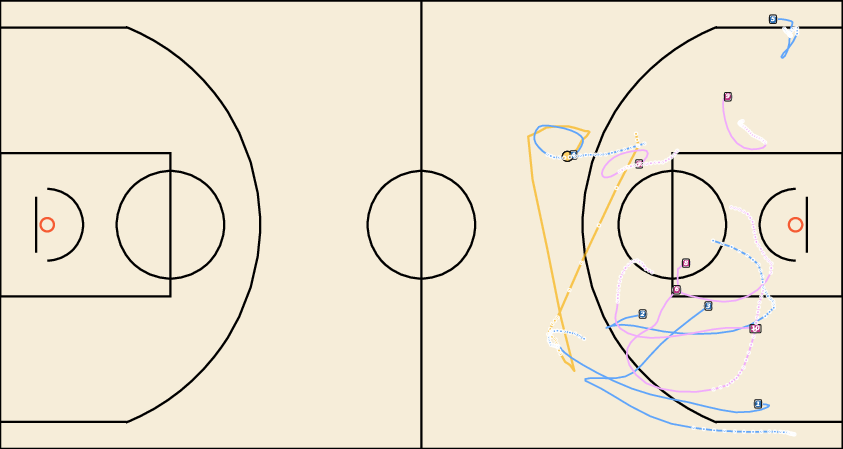
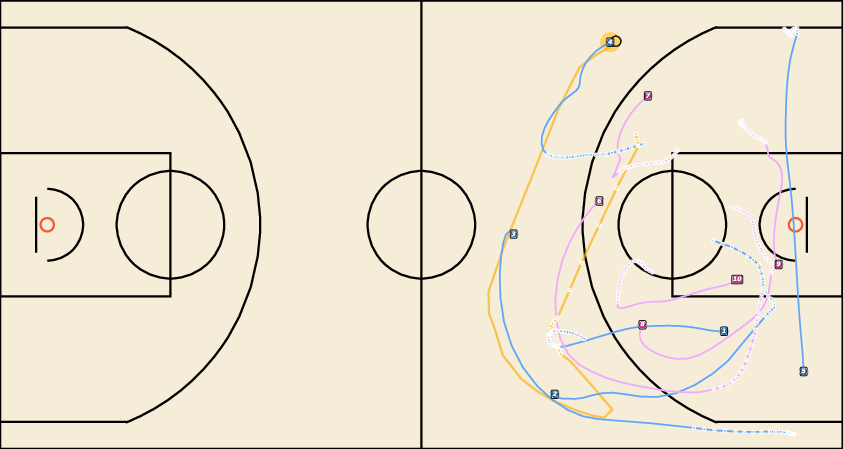
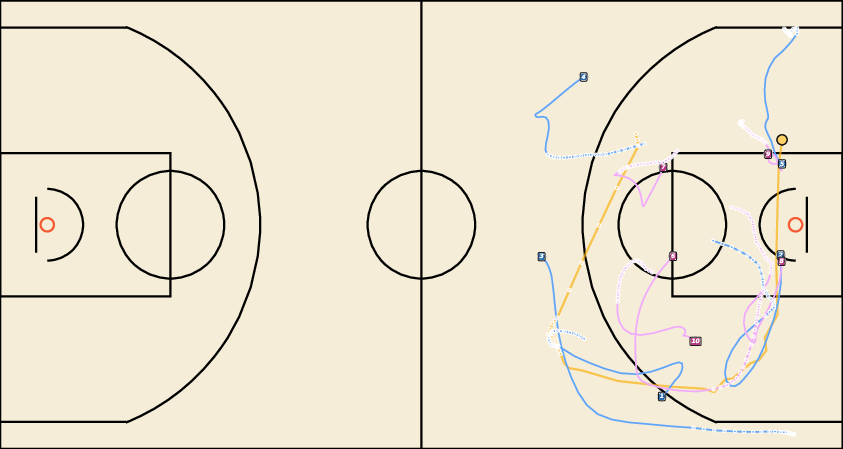
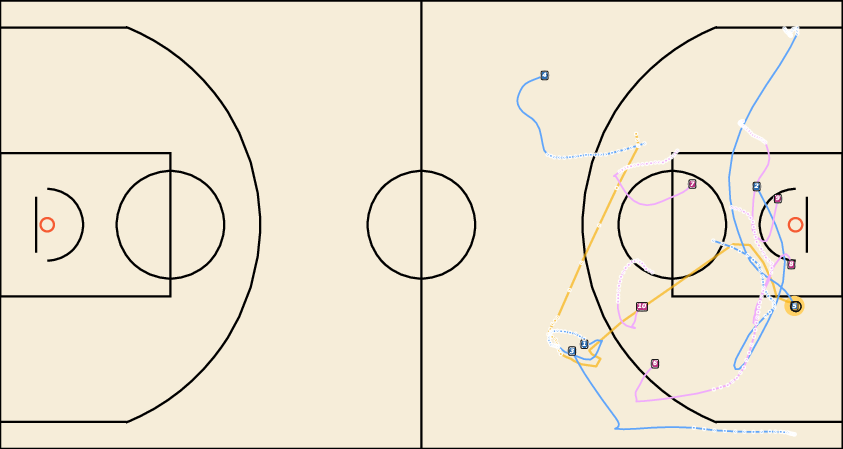
Figure 8: Controllable Generation with WPG. JointDiff accurately follows possessor sequences, outperforming non-joint variants.
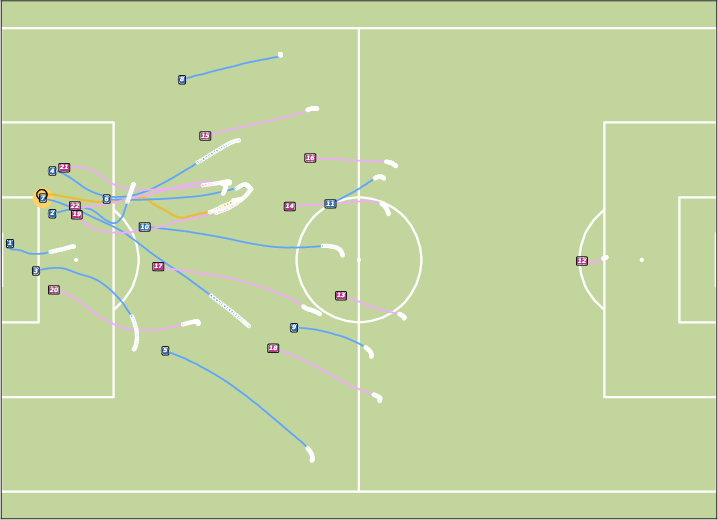
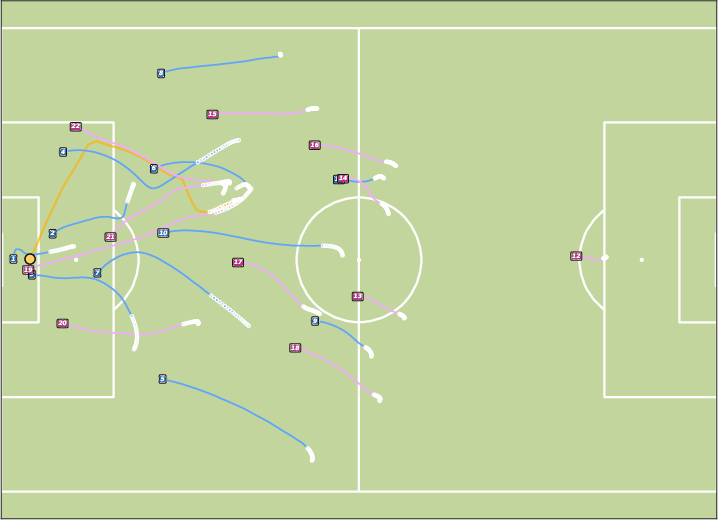
Figure 9: Controllable Generation with Text. JointDiff generates scenes consistent with natural language prompts, demonstrating fine-grained control.
Human Evaluation and Interpretability
Pairwise human evaluation on NBA data shows that JointDiff is consistently preferred over baselines, indicating perceptual superiority. Attention entropy analysis reveals that joint modeling leads to more focused inter-agent attention, especially in early denoising steps.
Figure 10: Human Evaluation Interface used for perceptual quality assessment.
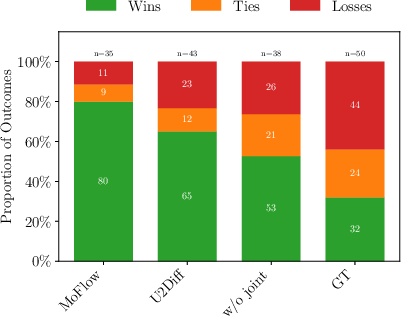
Figure 11: Winning Rate. JointDiff achieves higher win rates in human evaluation compared to baselines.
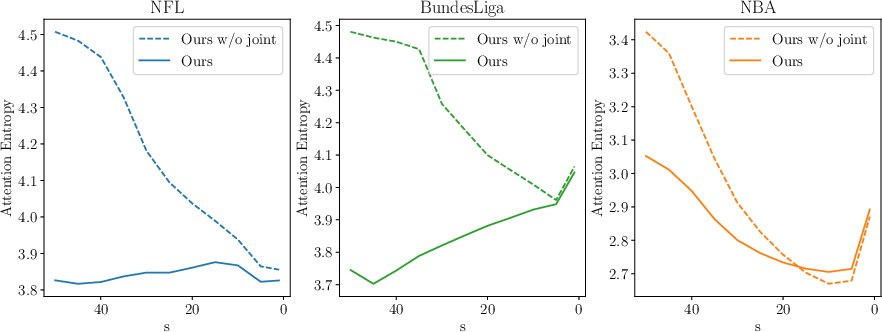
Figure 12: Entropy vs Denoising Step. JointDiff maintains lower attention entropy, indicating more specialized agent interactions.
Implementation Considerations
- Computational Requirements: The architecture leverages efficient sequence modeling (Temporal Mamba) and parallelizable attention mechanisms. Training is feasible on modern GPUs with batch sizes of 16 and hidden sizes of 256.
- Sampling Efficiency: Hybrid DDIM and multinomial sampling reduce inference time, with optimal discrete denoising steps empirically determined.
- Scalability: The model generalizes across sports domains and agent counts, with unified event extraction heuristics.
- Limitations: The current framework assumes dense event patterns and cannot directly handle sparse temporal point processes. Event annotation in NFL relies on heuristics due to missing actor labels.
Implications and Future Directions
JointDiff establishes a new paradigm for generative modeling in multi-agent systems, demonstrating that joint continuous-discrete diffusion is essential for realistic and controllable scene generation. The framework enables semantic control via both structured and unstructured guidance, paving the way for applications in sports analytics, simulation, and interactive video synthesis. Future work should address sparse event modeling, integration with high-dimensional generative models, and improved event annotation pipelines.
Conclusion
JointDiff presents a unified diffusion framework for multi-agent trajectory and event generation, achieving state-of-the-art results in both completion and controllable tasks. The joint modeling of continuous and discrete modalities is shown to be critical for scene-level coherence and controllability. The architecture and methodology are extensible to other domains where synchronous continuous and discrete processes interact, and the released benchmark and code will facilitate further research in this area.