- The paper presents an annotation-free framework that aligns CNN attention with VLM-generated maps to mitigate shortcut learning.
- It employs a joint training objective using KL divergence to align saliency maps, achieving 64.88% accuracy on ColorMNIST.
- The study demonstrates that cognitive attention alignment shifts model focus from spurious cues to task-relevant features, improving generalization.
Cognitive Attention Alignment in Vision-LLMs: A Scalable Framework
Motivation and Background
Convolutional Neural Networks (CNNs) are susceptible to shortcut learning, often exploiting spurious correlations in data rather than acquiring robust, generalizable representations. This phenomenon undermines reliability, especially in settings where superficial cues (e.g., color, background artifacts) are confounded with true class semantics. Cognitive science emphasizes the role of attention in human perception, guiding focus toward task-relevant features and supporting robust generalization. Prior approaches to attention alignment in neural networks—such as concept-based supervision and explanation regularization—require labor-intensive, expert-provided annotations, limiting scalability and introducing annotation bias.
This paper introduces a scalable, annotation-free framework for attention alignment in CNNs, leveraging vision-LLMs (VLMs) to generate semantic attention maps via natural language prompts. The framework employs an auxiliary loss to align CNN attention with these language-guided maps, promoting cognitively plausible decision-making and reducing shortcut reliance.
Methodology
Automatic Generation of Semantic Attention Maps
The framework utilizes WeCLIP+, a state-of-the-art VLM, to generate class-specific attention maps for each image using natural language prompts. For a given input xi and class label yi, a prompt tyi (e.g., "a photo of a digit") is constructed. WeCLIP+ produces an affinity map MVL(xi,yi), highlighting regions associated with the semantic concept. Optionally, background or distractor prompts are included to help the model distinguish foreground from context.
Attention maps may be post-processed using morphological dilation or edge detection to refine inductive biases, but unmodified WeCLIP+ maps are often sufficient.
Attention-Aligned CNN Training
The CNN fθ is trained to minimize a joint objective:
L=LCE+λLattn
where LCE is the standard cross-entropy loss and Lattn is the KL divergence between the normalized CAM saliency map Sθ(xi,yi) and the WeCLIP+ attention map MVL(xi,yi). The training schedule consists of two phases: initial epochs focus solely on attention alignment, followed by joint optimization with a ramped λ to prioritize attention supervision.
Hyperparameters (λ,Eattn) are selected via grid search using a composite metric, Optim Value:
Optim Value=ValAcc×(1−Lattn)
which favors configurations that jointly maximize accuracy and minimize attention divergence.
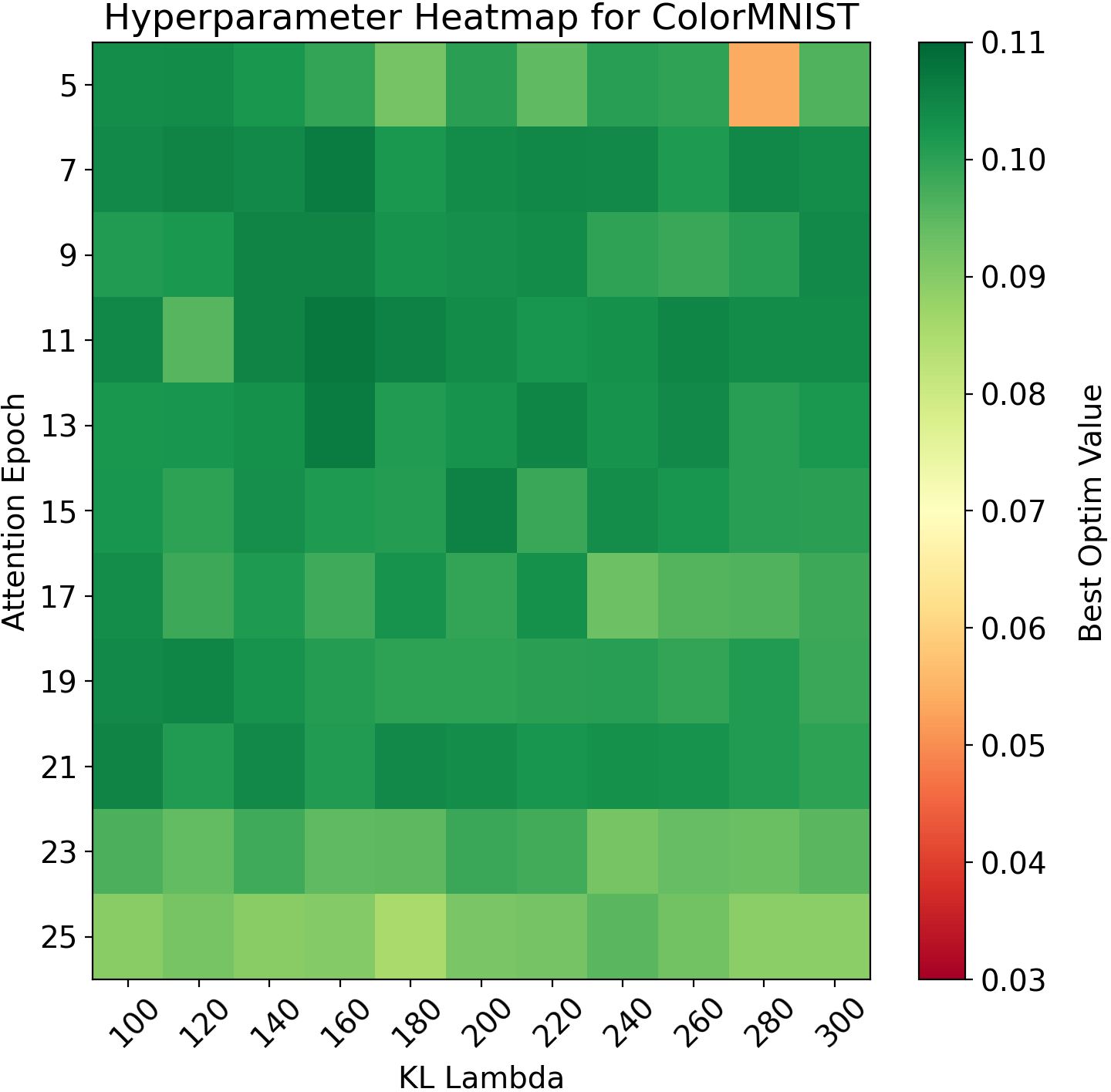
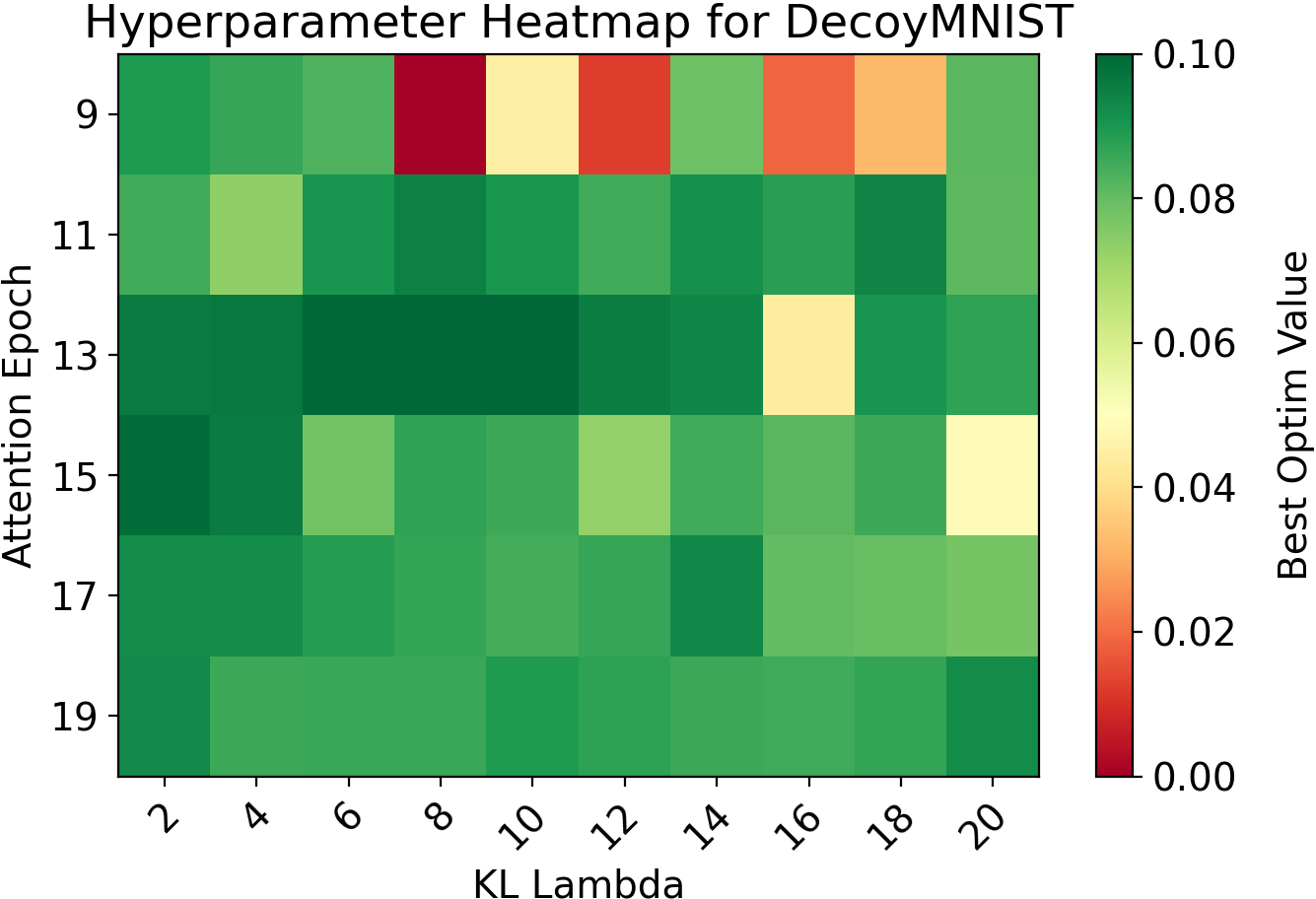
Figure 1: ColorMNIST: Optim Value across (λ,Eattn), illustrating the impact of attention alignment hyperparameters on joint accuracy and attention loss.
Experimental Evaluation
Datasets and Baselines
Experiments are conducted on ColorMNIST and DecoyMNIST, benchmarks designed to test model reliance on spurious correlations. In ColorMNIST, digit classes are assigned unique colors during training, with color mappings reversed at test time. DecoyMNIST augments digits with class-indicative gray patches, creating spurious associations.
Baselines include a vanilla CNN (Base), concept distillation (CDBS), and explanation regularization methods (RRR, CDEP).
Quantitative Results
On ColorMNIST, the baseline CNN achieves only 0.1% accuracy, indicating complete shortcut reliance. RRR performs similarly, while CDEP and CDBS reach 31.0% and 50.93% respectively. The proposed method achieves 64.88±2.85%, outperforming annotation-heavy baselines and demonstrating effective shortcut mitigation.
On DecoyMNIST, manual supervision methods achieve near-perfect accuracy ($97.2$–99.0%). The proposed method attains 96.19±0.35%, remaining competitive despite relying solely on automatically generated pseudo-maps.
Qualitative Analysis
Saliency map comparisons reveal that attention alignment shifts model focus from spurious cues (color, corner patches) to digit shape, aligning with human intuition.
(Figure 2)
Figure 2: Qualitative comparison of saliency maps on ColorMNIST and DecoyMNIST, showing original inputs, base model saliency, and attention-aligned saliency. Brighter regions indicate higher saliency.
Implementation Considerations
- Computational Requirements: Precomputing and storing attention maps for large datasets can be memory-intensive. On-the-fly generation is a promising direction for future work.
- Backbone Agnosticism: The framework is compatible with various CNN architectures and differentiable saliency techniques. Extension to Vision Transformers is feasible by adapting the attribution mechanism.
- Hyperparameter Sensitivity: Performance is sensitive to the choice of λ and Eattn, necessitating careful grid search.
- Bias in Teacher Signals: Reliance on VLM-generated attention maps may introduce biases inherent to the teacher model. Mitigation strategies include debiasing or ensemble teacher approaches.
Limitations and Future Directions
The evaluation is restricted to simple benchmarks; extension to complex, high-dimensional datasets is necessary to assess generalizability. Memory overhead from precomputed maps and potential teacher bias are open challenges. Future work should explore dynamic attention map generation, broader dataset coverage, and robust debiasing techniques.
Conclusion
This work presents a scalable, annotation-free framework for cognitive attention alignment in vision-LLMs, leveraging language-driven attention maps to guide neural networks toward task-relevant features. The approach achieves state-of-the-art accuracy on ColorMNIST and remains competitive on DecoyMNIST, requiring no human-provided saliency or concept labels. The framework is flexible, backbone-agnostic, and amenable to extension. Future research should address scalability, teacher bias, and applicability to more complex domains, advancing the integration of cognitive inductive biases in deep learning systems.