- The paper presents CCRA, a novel framework integrating LPWCA and PAI to enhance vision-language alignment while mitigating attention drift.
- It employs combined spatial and layer-wise attention to capture fine-grained text-image correlations, thereby improving interpretability.
- Experiments on ten benchmarks show significant gains, particularly in OCR and spatial reasoning, with only a minimal increase in parameters.
Optimizing Vision-Language Consistency via Cross-Layer Regional Attention Alignment
The paper presents the Consistent Cross-layer Regional Alignment (CCRA) framework, which integrates diverse attention mechanisms to enhance Vision LLMs (VLMs). CCRA introduces Layer-Patch-Wise Cross Attention (LPWCA) and Progressive Attention Integration (PAI) to optimize cross-modal embedding learning, offering a comprehensive approach to balancing regional and semantic information to mitigate attention drift and improve model interpretability.
Methodology
Layer-Patch-Wise Cross Attention (LPWCA)
LPWCA is a foundational operation that enhances the representation of visual features by considering both regional and semantic importance. By combining spatial and layer-wise attention, this mechanism captures fine-grained correlations between the text and image. It begins by flattening multi-layer visual features into a single sequence, transforming them into a compatible space where correlations with query text embeddings can be established. This is achieved through a self-attention module applied to the text embeddings, followed by alignment with visual features via calculated attention scores.
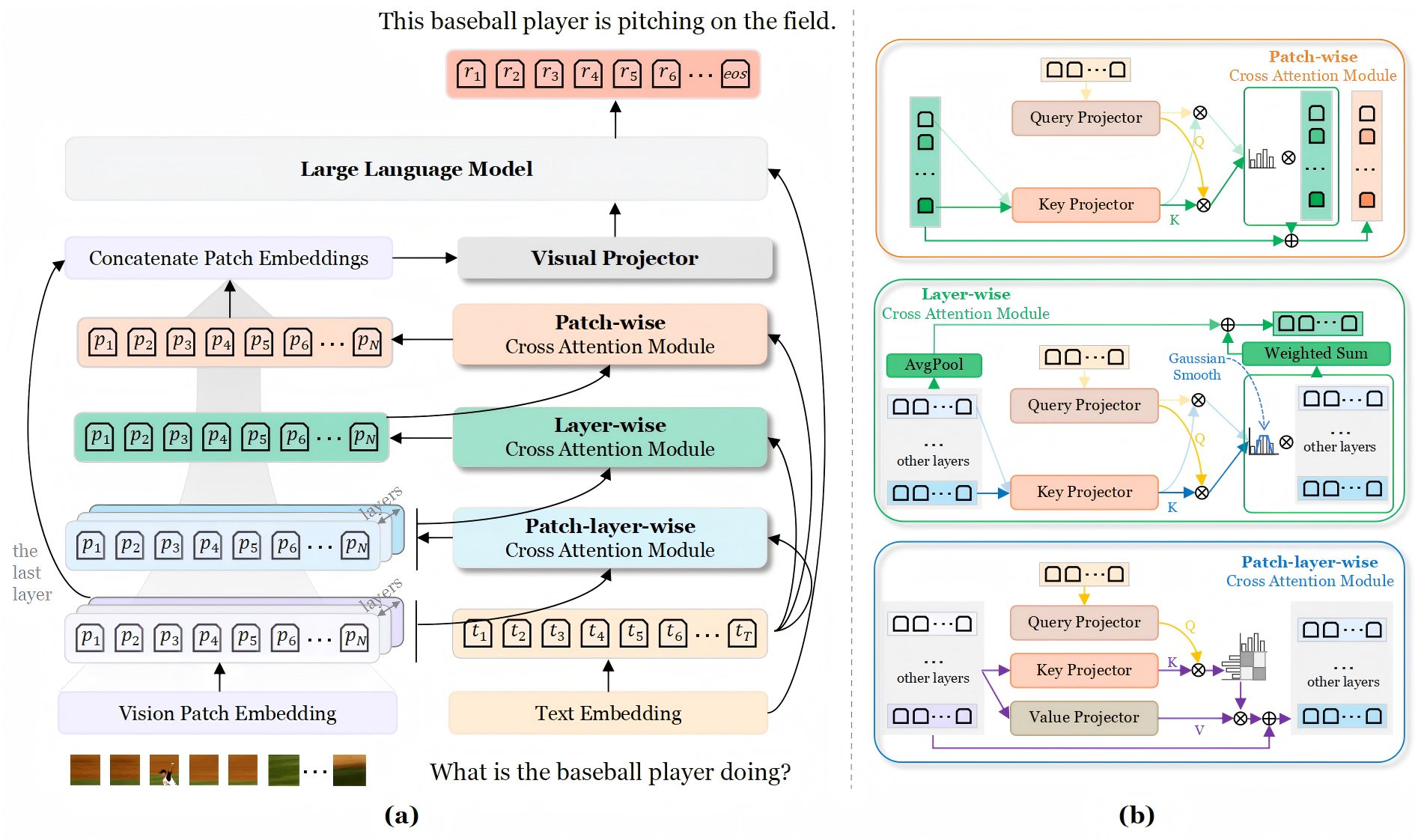
Figure 1: An overview of the VLM with Consistent Cross-layer Regional Alignment, demonstrating the use of PLWCA, LWCA, and PWCA for progressive feature alignment.
Progressive Attention Integration (PAI)
PAI systematically integrates LPWCA, optimized Layer-Wise Cross Attention (LWCA), and Patch-Wise Cross Attention (PWCA) to maintain semantic and regional consistency. This method ensures that the final visual representations are aligned with the task requirements, promoting better interpretability through smooth attention transitions. Gaussian smoothing is applied to LWCA, refining semantic layer selections and maintaining complete information continuity without disregarding non-selected layers.
Experimental Results
The authors evaluated CCRA across ten diverse benchmarks, demonstrating superior performance with only a 3.55 million parameter increase compared to baseline models. Notably, CCRA showed significant improvements in tasks requiring fine-grained OCR and spatial reasoning.
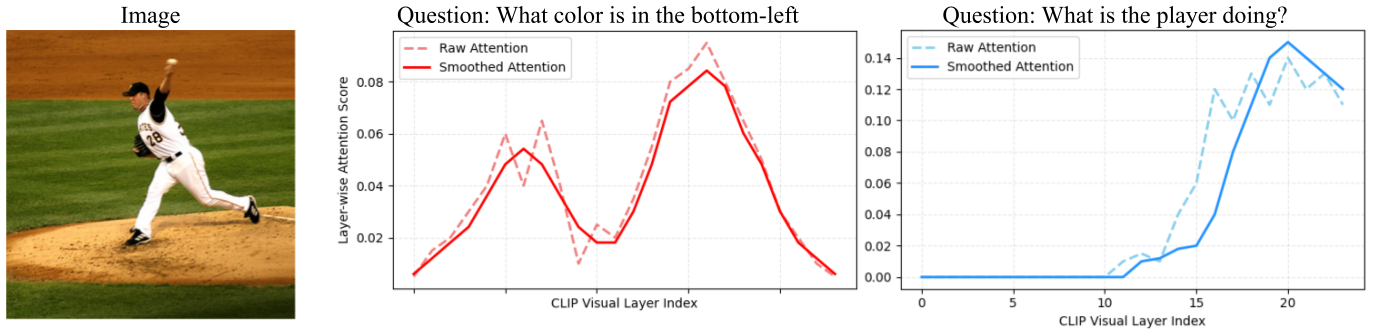
Figure 2: Comparison of LWCA distributions for queries of different semantic levels, illustrating adapted layer activation.

Figure 3: Visualization of cross-attention, showcasing focused attention in CCRA versus alternatives.
CCRA's performance gains are attributed to its enhanced ability to align visual content with text queries across various contexts, as detailed in qualitative analyses. Attention visualizations reveal more coherent and focused model behavior, directly linking improved attention precision to language output accuracy.
Conclusion
The paper effectively outlines a novel approach to vision-language alignment in VLMs through CCRA, showcased by impressive quantitative and qualitative results across challenging benchmarks. Future research could further refine attention smoothing mechanisms to optimize semantic integration within CCRA.
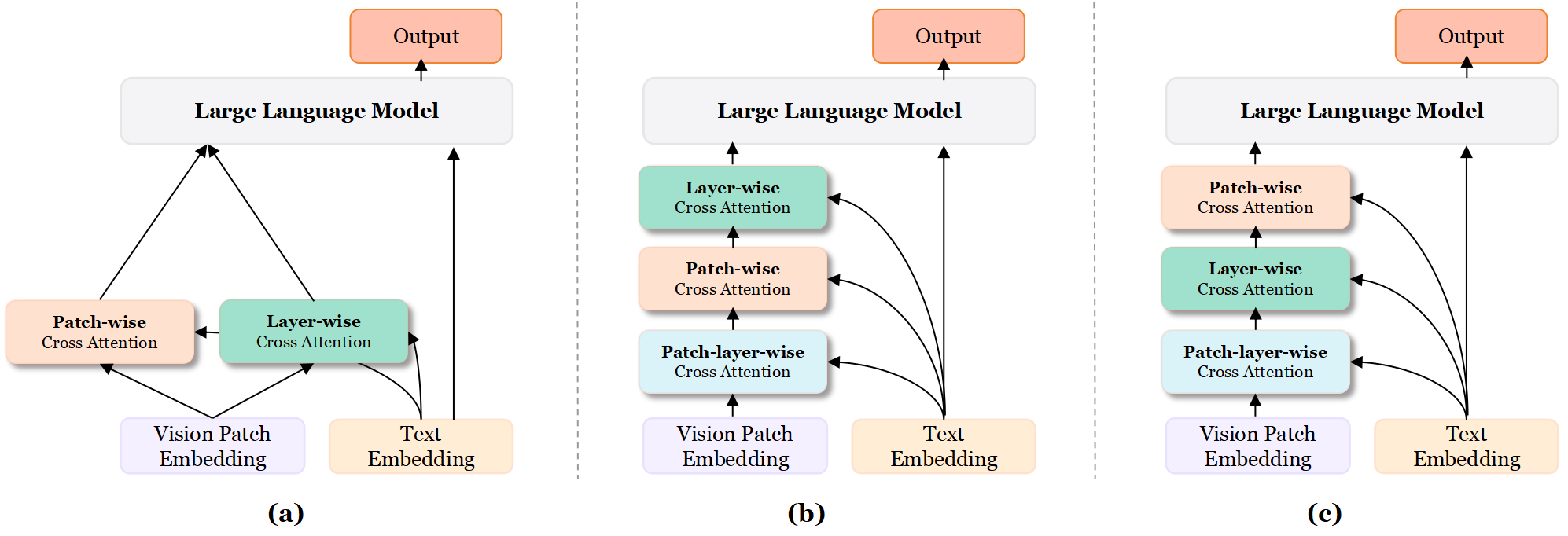
Figure 4: Comparison of cross-attention strategies, with CCRA (c) yielding sharper alignment than alternatives.
By maintaining both semantic smoothness and regional consistency, CCRA sets a new standard for crafting robust, interpretable multimodal models with minimal computational overhead.

