SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild (2503.18892v3)
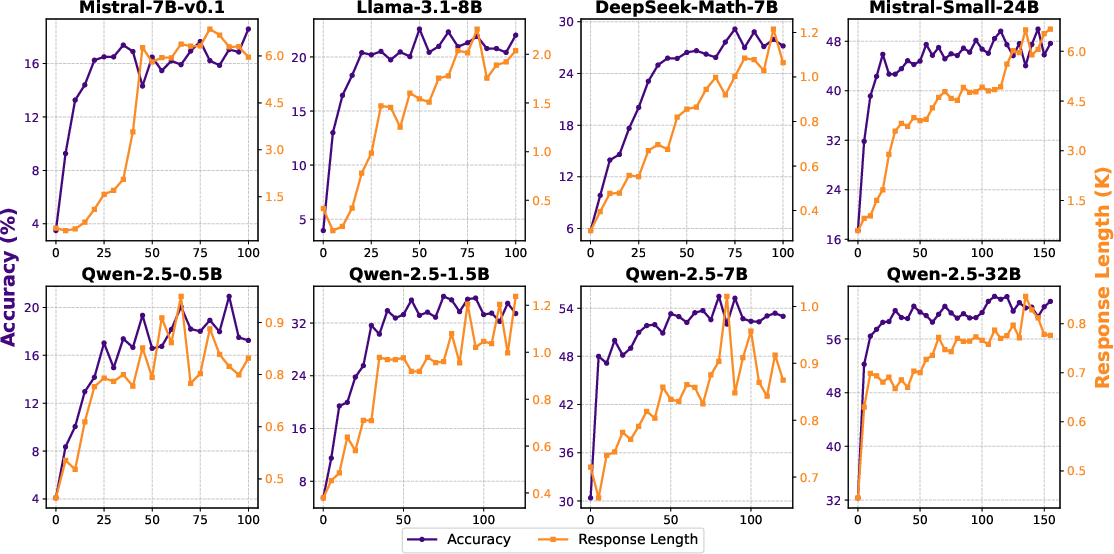
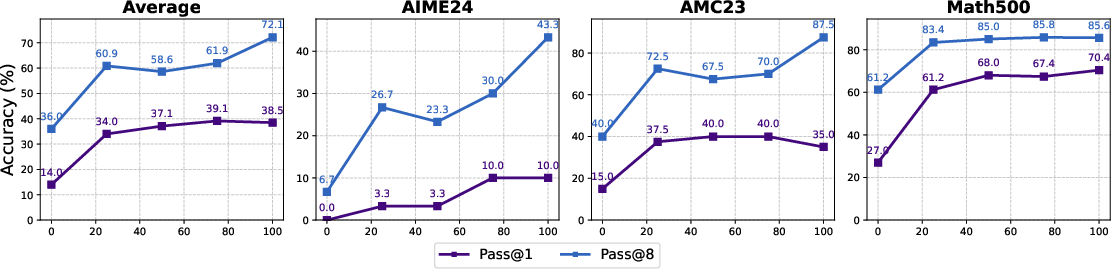
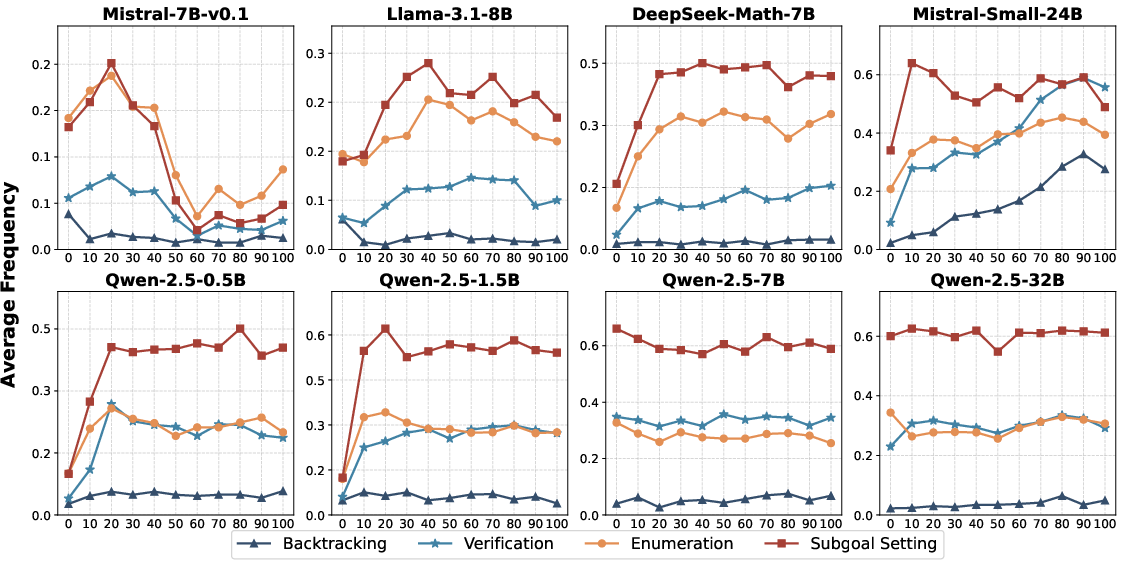
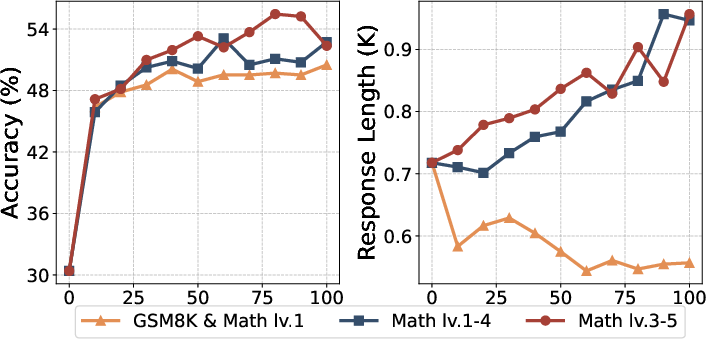
Abstract: DeepSeek-R1 has shown that long chain-of-thought (CoT) reasoning can naturally emerge through a simple reinforcement learning (RL) framework with rule-based rewards, where the training may directly start from the base models-a paradigm referred to as zero RL training. Most recent efforts to reproduce zero RL training have primarily focused on the Qwen2.5 model series, which may not be representative as we find the base models already exhibit strong instruction-following and self-reflection abilities. In this work, we investigate zero RL training across 10 diverse base models, spanning different families and sizes including LLama3-8B, Mistral-7B/24B, DeepSeek-Math-7B, Qwen2.5-math-7B, and all Qwen2.5 models from 0.5B to 32B. Leveraging several key design strategies-such as adjusting format reward and controlling query difficulty-we achieve substantial improvements in both reasoning accuracy and response length across most settings. However, by carefully monitoring the training dynamics, we observe that different base models exhibit distinct patterns during training. For instance, the increased response length does not always correlate with the emergence of certain cognitive behaviors such as verification (i.e., the "aha moment"). Notably, we observe the "aha moment" for the first time in small models not from the Qwen family. We share the key designs that enable successful zero RL training, along with our findings and practices. To facilitate further research, we open-source the code, models, and analysis tools.
Collections
Sign up for free to add this paper to one or more collections.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.