- The paper introduces a guard-prompt whitelisting technique that contextually filters interactions to secure agentic LLMs against prompt injections.
- It employs a dynamic risk scoring mechanism and evaluates performance across various Llama models to minimize false positives and negatives.
- LLMZ+ enhances operational security and usability in production environments by integrating context-aware defenses into business-critical LLM deployments.
LLMZ+: Contextual Prompt Whitelist Principles for Agentic LLMs
Introduction
"LLMZ+: Contextual Prompt Whitelist Principles for Agentic LLMs" presents a novel approach for securing agentic LLMs against unauthorized prompt injections and jailbreaks. Unlike traditional methods that rely on the detection of malicious prompts, LLMZ+ emphasizes whitelisting derived from contextual understanding to ensure interactions stay within predefined boundaries. This approach has substantial implications for improving both the operational and informational security of LLMs while maintaining seamless legitimate user interactions.
Framework and Principles
Traditional defenses for LLMs often struggle with the dynamic nature of cyber threats, frequently requiring updates to signature databases to stay relevant. LLMZ+ redefines this paradigm by implementing a guard prompt whitelisting technique that selectively permits only contextually verified communications. This mimics the "DENY ALL" principle in firewall technologies, wherein only recognized and compliant traffic is allowed.
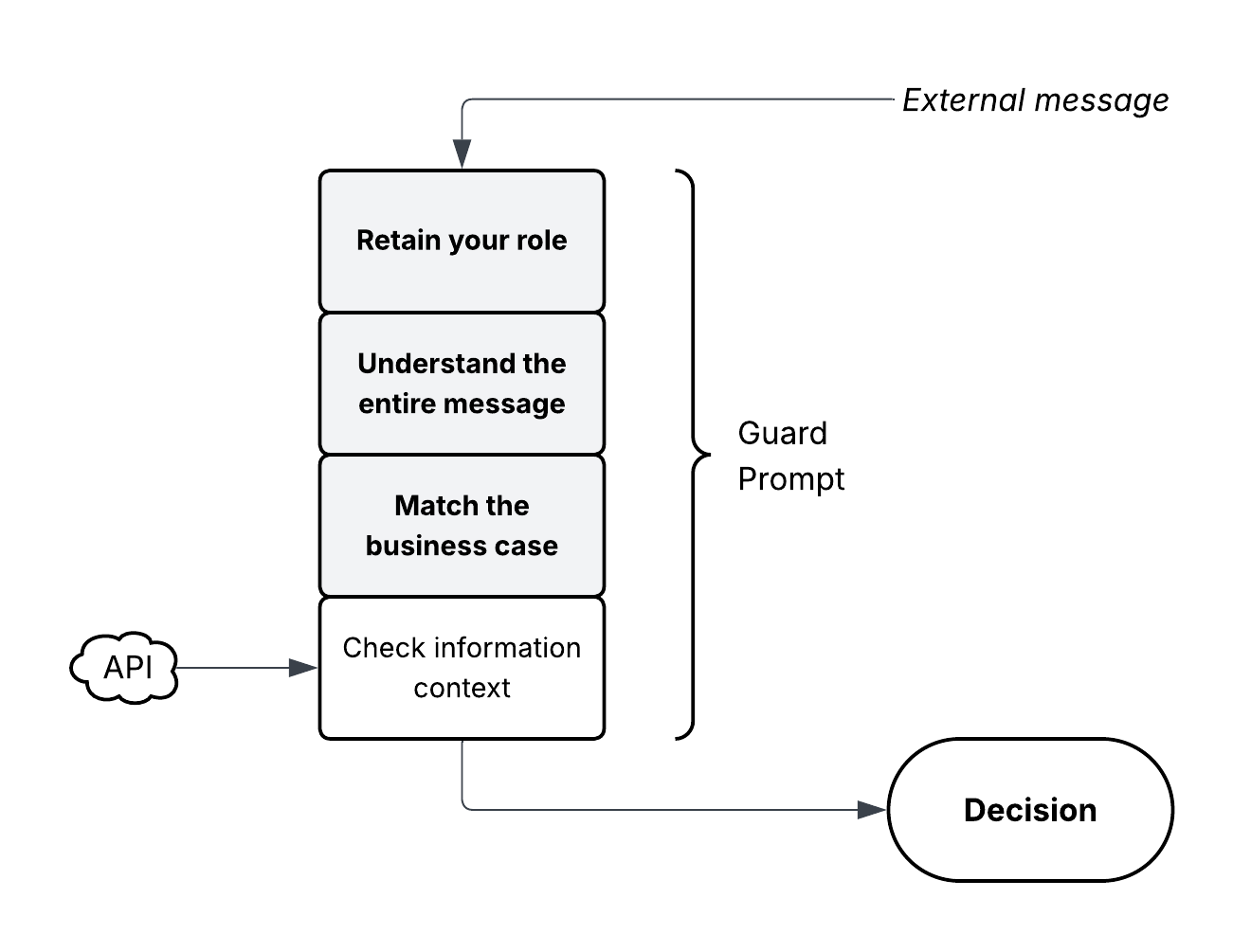
Figure 1: LLMZ+ Guard Prompt Structure.
The guard prompt in LLMZ+ acts as a filter, assessing all incoming and outgoing messages against predetermined contextual criteria. The criteria include complete interpretability, natural flow for customer-service exchanges, and relevance to the specific business case handled by the agentic LLM.
Threat Model and Deployment
LLMZ+ targets specific deployment scenarios involving agentic LLMs embedded within business processes, typically requiring access to sensitive data and API interactions. The targeted attacks often involve prompt-based engineering techniques attempting to exploit these privileged access pathways.
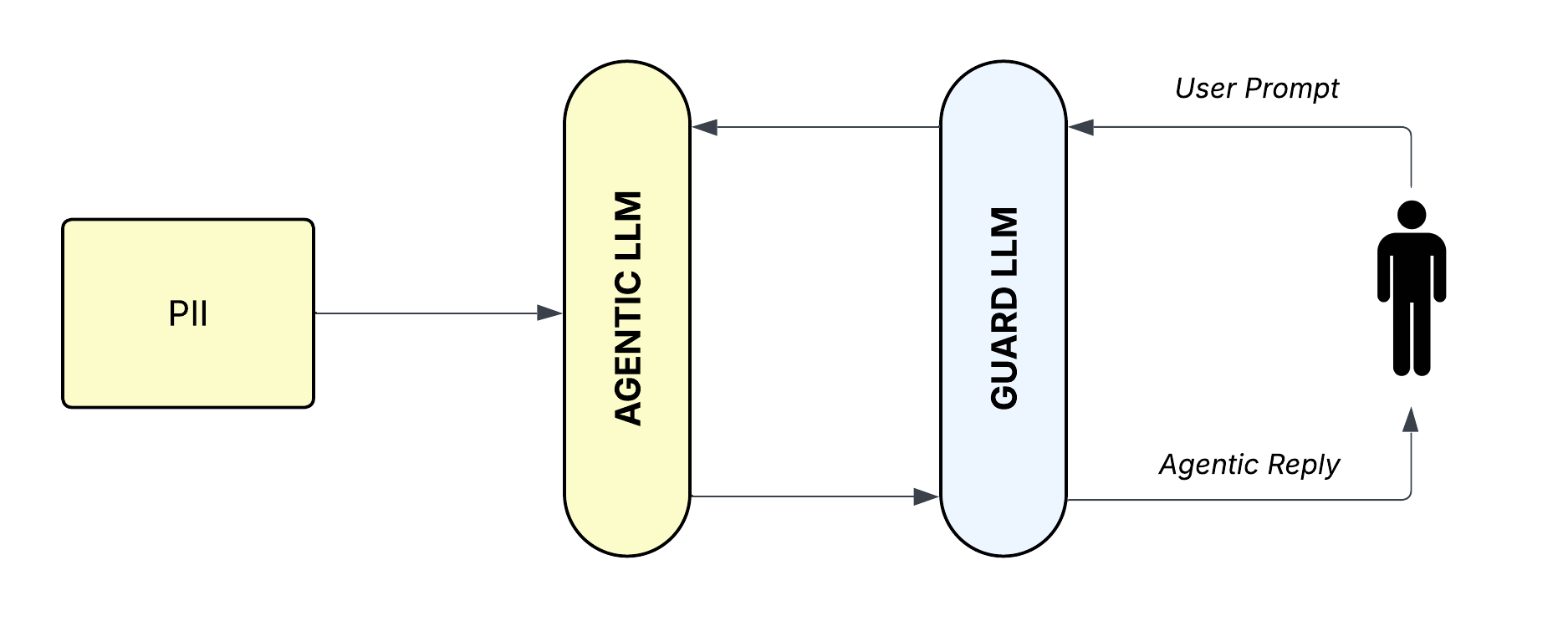
Figure 2: LLMZ+ Data Flow.
In practice, LLMZ+ evaluates incoming messages for compliance with contextual criteria before allowing them to proceed. Outgoing messages are similarly scrutinized to prevent unauthorized disclosure of sensitive information. This simultaneous circle of scrutiny ensures that both message ingestion and egress are tightly controlled.
LLMZ+'s effectiveness was evaluated using various LLM models, including Llama3.18B, Llama3.370B, and Llama3.1405B, with assessments focused on minimizing false positive and false negative rates. The risk scoring mechanism employed by LLMZ+ provides dynamic thresholding that adapts to evolving security contexts.
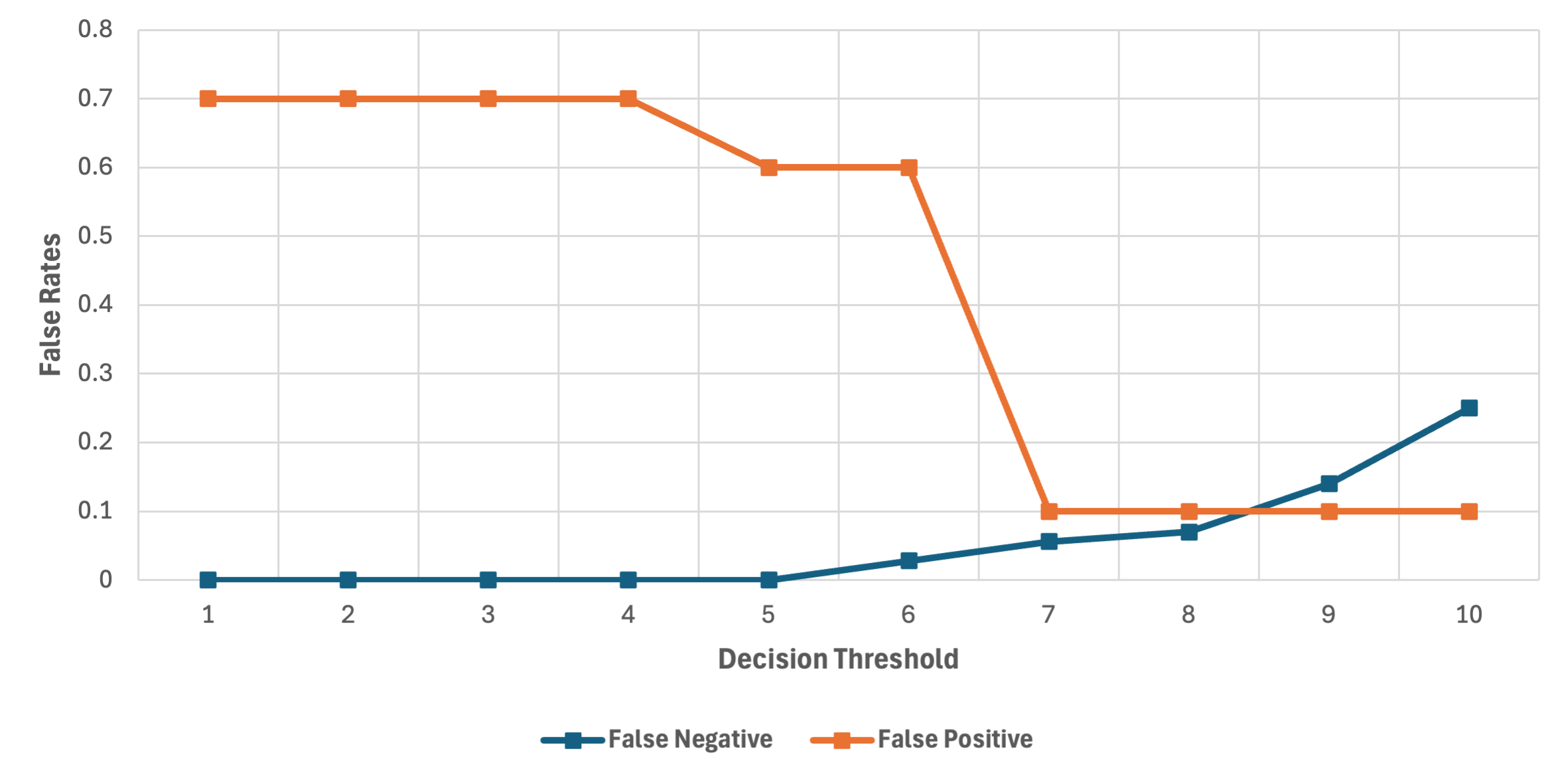
Figure 3: False rates, Llama3.18B, showing initial instances of false negatives at higher decision thresholds.
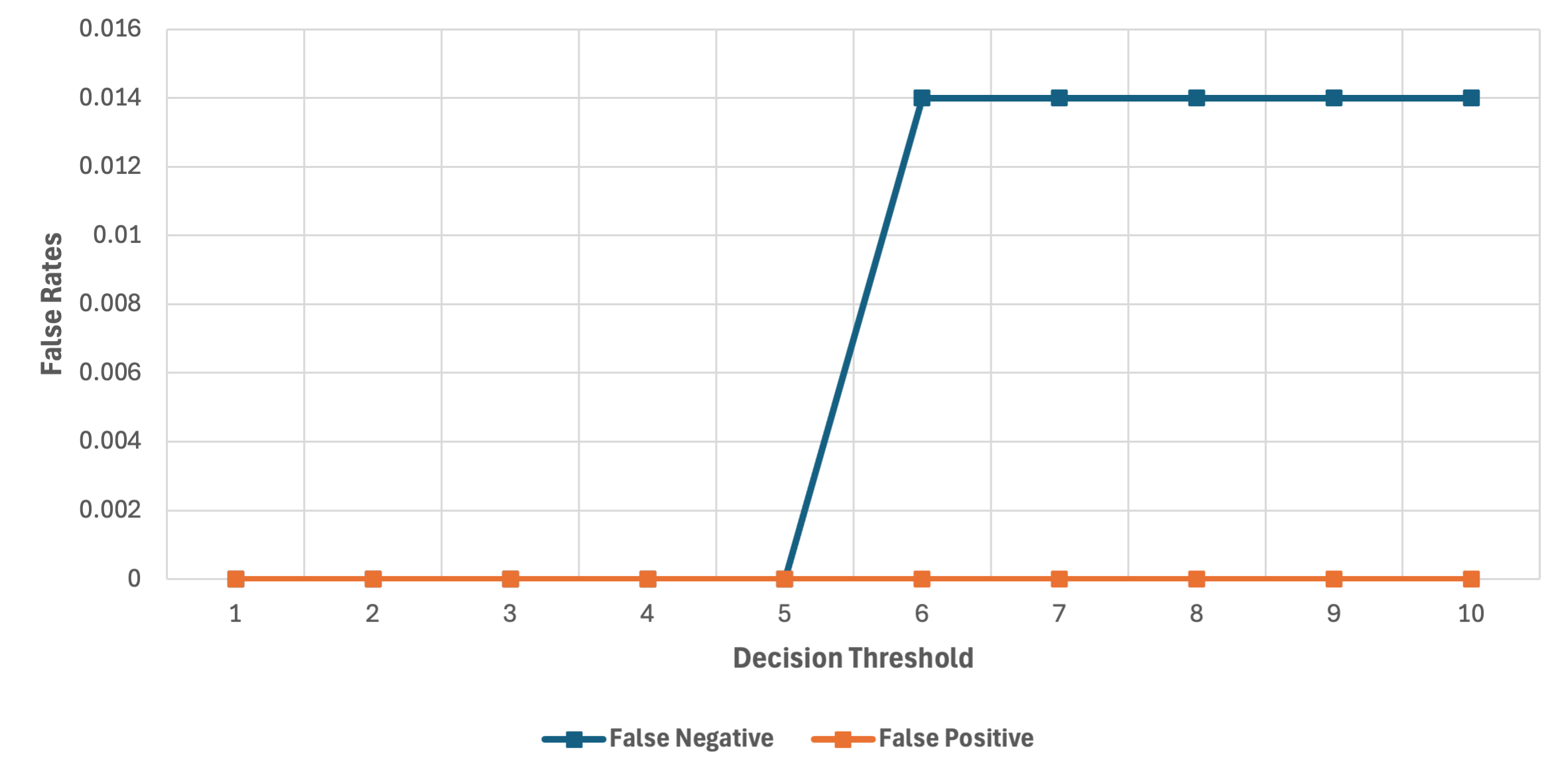
Figure 4: False rates, Llama3.370B, demonstrating superior performance with a wider range of effective decision thresholds.
The results indicate that the Llama3.370B and Llama3.1405B configurations significantly outperform smaller models in filtering malicious content while preserving legitimate communications.
Practical Considerations
Deploying LLMZ+ in production mandates careful consideration of resource constraints, sensitivity to latency, and operational context. The selection of the appropriate guard model is crucial for balancing security efficacy and system performance. Techniques such as message pre-processing and false positive overrides can mitigate limitations of smaller models like Llama3.18B.
In high-demand environments, parallel processing architectures enable concurrent execution of guard and agentic prompts, minimizing delays while maintaining robust defenses against prompt-based attacks.
Conclusion
LLMZ+ represents a pivotal advance in securing agentic LLMs through a context-driven whitelisting approach that avoids the pitfalls of traditional static defenses. By focusing on contextual understanding and dynamic filtering, LLMZ+ effectively bridges the gap between security and usability in AI-driven environments. Future research may enhance this framework by integrating retrieval-augmented generation pipelines and embedding more robust content ring-fencing directly within LLMs themselves, further solidifying defenses against innovative threat vectors.

