- The paper demonstrates that CPO fine-tuning improves synthetic query quality by reducing the need for aggressive filtering.
- It incorporates dynamic prompt optimization via DSPy and Chain-of-Thought reasoning to generate more contextually relevant queries.
- Experimental results on SciFact and MS MARCO validate improved retrieval metrics, ensuring reproducibility and enhanced computational efficiency.
Introduction
The paper "InPars+: Supercharging Synthetic Data Generation for Information Retrieval Systems" (2508.13930) presents a systematic study and extension of synthetic query generation (QGen) pipelines for Neural Information Retrieval (NIR). The authors focus on the InPars Toolkit, an open-source, end-to-end framework for generating synthetic training data using LLMs, and introduce two principal enhancements: (1) fine-tuning the query generator LLM via Contrastive Preference Optimization (CPO), and (2) replacing static prompt templates with dynamic, Chain-of-Thought (CoT) optimized prompts using the DSPy framework. The work addresses the inefficiencies and reproducibility challenges in existing QGen pipelines and demonstrates improved retrieval performance and reduced filtering requirements.
Background: Synthetic Query Generation Pipelines
Synthetic data generation for NIR typically involves using LLMs to generate queries for a given document corpus, followed by filtering and using the highest-quality query-document pairs to fine-tune a reranker model. The InPars family of pipelines (InPars-V1, InPars-V2, Promptagator) differ in their choice of generator LLMs, prompt templates, and filtering mechanisms. A key limitation in these pipelines is the high rejection rate of generated queries—often discarding up to 90% of generations due to low quality, resulting in significant computational waste.
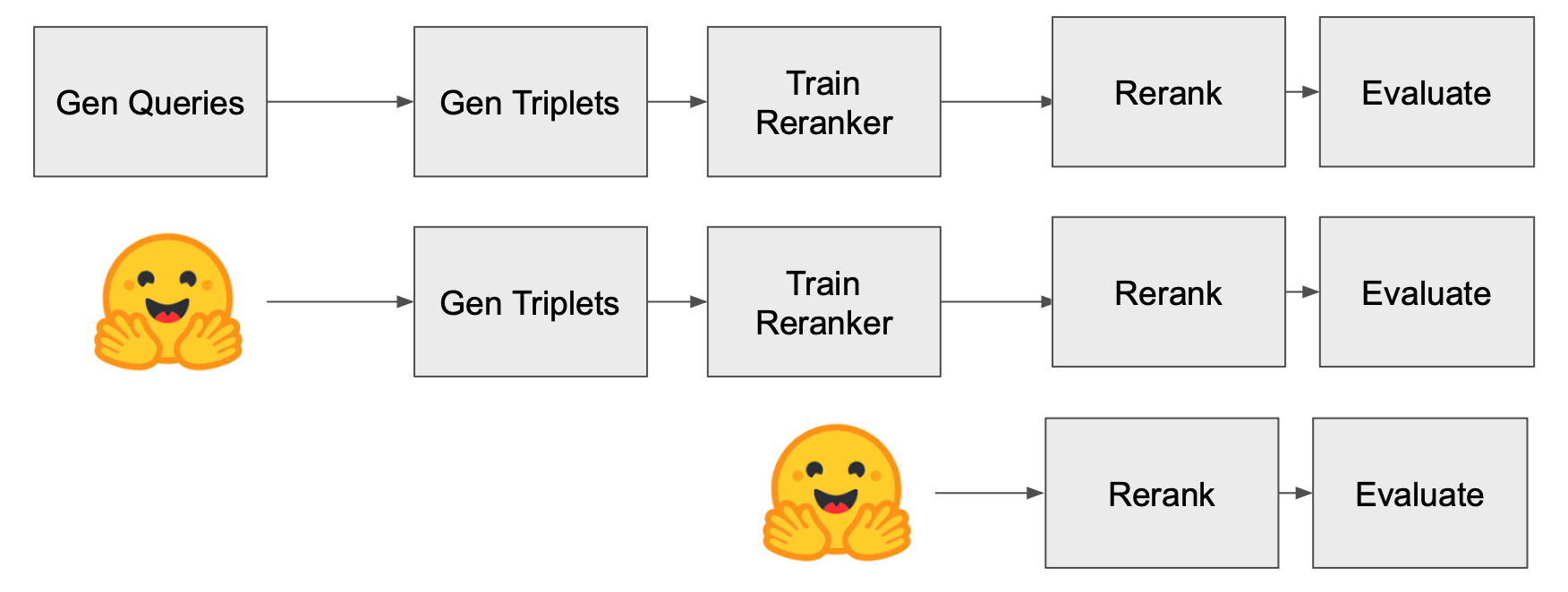
Figure 1: Diagram of the three different reproducibility experiments.
The InPars Toolkit was introduced to address reproducibility and accessibility issues, providing a modular, GPU-compatible, and open-source implementation of these pipelines. However, the toolkit still inherits the inefficiencies of aggressive filtering and static prompt design.
Methodological Extensions
Fine-Tuning the Generator with Contrastive Preference Optimization
The authors propose fine-tuning the generator LLM using CPO, a preference-based optimization technique that leverages triplets of reference, teacher, and student generations, scored by a reference-free metric. The CPO objective encourages the student model to generate queries that are preferred over less relevant alternatives, while a behavior-cloning regularizer ensures the student does not diverge excessively from the teacher's distribution. This approach is designed to reduce the noise in generated queries, thereby minimizing the need for extensive filtering.
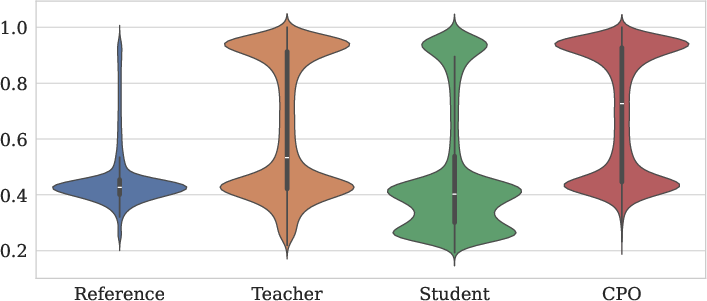
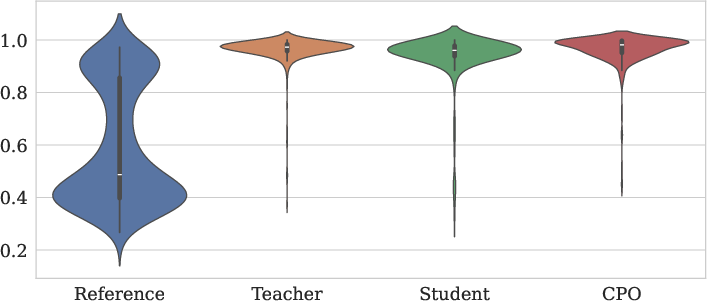
Figure 2: MS MARCO.
The CPO-based fine-tuning pipeline samples relevant query-document pairs, generates queries using both teacher and student models, scores them for relevance, and constructs triplets for optimization. The scoring function combines a Siamese network-based encoder similarity with normalized BM25 scores, providing a robust signal for preference optimization.
Dynamic Prompt Optimization with DSPy and Chain-of-Thought
To address the rigidity of static prompt templates, the authors integrate the DSPy framework, which enables dynamic, programmatic prompt construction and optimization. By leveraging CoT reasoning, the LLM is guided to decompose the document content into logical steps before generating a query, resulting in more contextually appropriate and higher-quality queries.

Figure 3: Module definition for AgentQueryGenerator, a DSPy signature that prompts a meta-llama/Llama-3.1-8B model to behave as a skilled research assistant.
The DSPy-based approach treats the LLM as an agent, embedding instructions and reasoning steps directly into the prompt. This method is shown to improve the diversity and relevance of generated queries, though it introduces additional computational overhead and requires careful management of output adherence.
Experimental Results
Reproducibility and Baseline Validation
The authors conduct three reproducibility experiments on the SciFact dataset, validating the end-to-end reproducibility, resource publication, and plug-and-play functionality of the InPars Toolkit. Results closely match those reported by the original authors, confirming the toolkit's reliability and flexibility in integrating alternative LLMs such as Llama 3.1 8B.
Impact of Generator Fine-Tuning and Prompt Optimization
The main experimental results demonstrate that:
- Fine-tuning the generator with CPO on MS MARCO yields a student model capable of generating higher-quality queries, as evidenced by improved score distributions and downstream reranker performance.
- Dynamic prompt optimization with DSPy and CoT consistently improves retrieval metrics across datasets, particularly in low-resource or high-noise settings.
- The need for aggressive filtering is reduced; CoT-based prompts allow for comparable or superior reranker performance with fewer generated queries, enhancing computational efficiency.
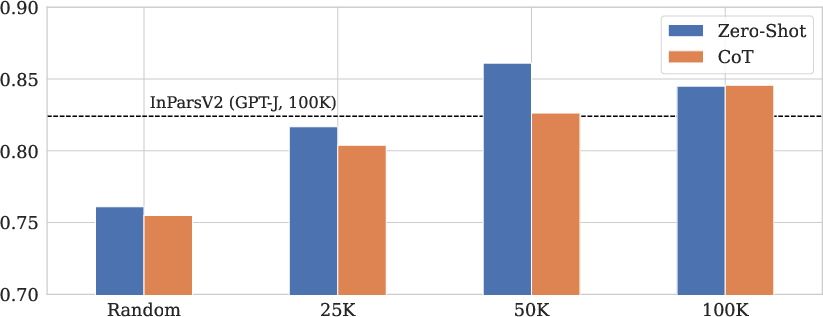
Figure 4: Impact of filtering for zero-shot generation and CoT-derived generation using monoT5 as reranker (K=1000). The dotted line represents the baseline performance using the top 10,000 queries from GPT-J, while the bars depict results for queries generated by Llama 3.1 8B across various subsets.
Notably, the results indicate that larger generator models do not always yield better downstream performance, and that filtering can be beneficial or detrimental depending on the dataset and reranker configuration. The combination of CPO fine-tuning and dynamic prompt optimization provides the most robust improvements.
Discussion
The study highlights several important findings:
- CPO fine-tuning effectively distills preference knowledge from larger teacher models, improving the quality of synthetic queries and reducing the reliance on expensive filtering.
- Dynamic prompt optimization via DSPy and CoT enhances the adaptability and contextual relevance of generated queries, outperforming static templates in most scenarios.
- The relationship between generator model size, filtering strategy, and reranker performance is non-trivial; optimal configurations are dataset-dependent.
- The modularity and reproducibility of the InPars Toolkit facilitate rapid experimentation and integration of new LLMs and prompting strategies.
Theoretical implications include the potential for preference-based optimization and programmatic prompt design to generalize across NIR tasks, while practical implications center on improved efficiency and accessibility for synthetic data generation in resource-constrained environments.
Conclusion
This work rigorously validates and extends the InPars Toolkit for synthetic data generation in NIR, demonstrating that CPO-based generator fine-tuning and dynamic prompt optimization with DSPy and CoT can significantly improve retrieval performance and computational efficiency. The findings suggest that future research should further explore adaptive prompt construction, preference-based optimization, and more sophisticated query evaluation metrics to maximize the utility of synthetic data in information retrieval systems. The public release of code, models, and datasets further supports ongoing advancements in this domain.

