Federated Learning with Ad-hoc Adapter Insertions: The Case of Soft-Embeddings for Training Classifier-as-Retriever
Abstract: When existing retrieval-augmented generation (RAG) solutions are intended to be used for new knowledge domains, it is necessary to update their encoders, which are taken to be pretrained LLMs. However, fully finetuning these large models is compute- and memory-intensive, and even infeasible when deployed on resource-constrained edge devices. We propose a novel encoder architecture in this work that addresses this limitation by using a frozen small LLM (SLM), which satisfies the memory constraints of edge devices, and inserting a small adapter network before the transformer blocks of the SLM. The trainable adapter takes the token embeddings of the new corpus and learns to produce enhanced soft embeddings for it, while requiring significantly less compute power to update than full fine-tuning. We further propose a novel retrieval mechanism by attaching a classifier head to the SLM encoder, which is trained to learn a similarity mapping of the input embeddings to their corresponding documents. Finally, to enable the online fine-tuning of both (i) the encoder soft embeddings and (ii) the classifier-as-retriever on edge devices, we adopt federated learning (FL) and differential privacy (DP) to achieve an efficient, privacy-preserving, and product-grade training solution. We conduct a theoretical analysis of our methodology, establishing convergence guarantees under mild assumptions on gradient variance when deployed for general smooth nonconvex loss functions. Through extensive numerical experiments, we demonstrate (i) the efficacy of obtaining soft embeddings to enhance the encoder, (ii) training a classifier to improve the retriever, and (iii) the role of FL in achieving speedup.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making “retrieval-augmented generation” (RAG) systems faster, cheaper, and more private, especially on small devices like phones or laptops. RAG systems help AI answer questions by first looking up helpful documents (retrieval) and then using a LLM to write a good answer (generation). The authors show a new way to train the “retriever” part so it works well on new topics without needing huge computers or risking user privacy.
What questions did the researchers ask?
They focused on one big question, broken into simple parts:
- How can we tune a small, frozen LLM so it understands a new set of documents, without retraining the whole big model?
- Can we replace the usual “similarity search” with something smarter that learns what “similar” really means for the task?
- Can we train all this across many users’ devices (federated learning) while keeping their data private (differential privacy)?
- Will this training still work reliably (mathematically converge) even when we add privacy noise?
How did they try to solve it?
They combined a few ideas. Here are the core pieces, explained with everyday language:
1) Soft embeddings with tiny “adapters”
- Words and sentences are turned into numbers called “embeddings.” These are like coordinates that place similar meanings close together.
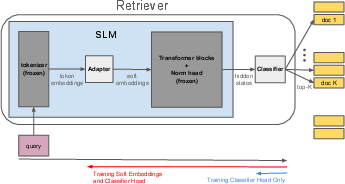
- Instead of retraining a giant model, they keep a small LLM frozen (unchanged) to save memory and speed.
- They insert a tiny trainable layer (an “adapter”) right after the word-embedding step. Think of the model as a big machine you don’t want to rebuild; the adapter is a small knob you can adjust to fine-tune the output for a new topic.
- The adapter learns “soft embeddings”: improved versions of the original embeddings that better match the new domain (like medical notes or news articles).
2) Classifier-as-Retriever (CaR)
- Usual retrievers find similar documents using a simple math trick (dot products), which can miss what really matters.
- Instead, they add a small “classifier head” at the end that learns to directly predict which documents best answer a given question.
- During use, the model picks the top K documents the classifier scores highest. This is like asking a trained librarian (the classifier) which books to pull, instead of blindly measuring how similar the titles look.
3) Federated learning (FL)
- Training happens across many devices that each keep their own data. Every device trains the small parts (adapter + classifier) locally and only shares model updates (not raw data) with a central server that averages them.
- Imagine many students each practicing on their notebooks and sending summaries of what they learned to a teacher, who blends the summaries into a better shared guide, then sends it back.
4) Differential privacy (DP)
- To protect privacy even more, each device “clips” the size of its update (so nothing stands out too much) and adds a little random noise before sending it. This blurs personal details while keeping the main learning signal intact.
- Think of it like whispering through a soft static so eavesdroppers can’t make out private facts.
5) Theory check (does it converge?)
- They include math showing that, under reasonable conditions, their training process still settles down (converges) to a good solution—even with the added noise for privacy.
What did they find?
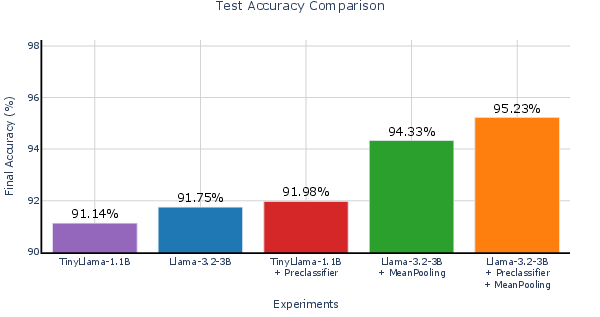
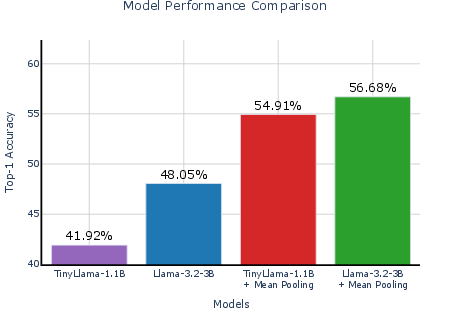
They ran tests on text classification datasets (like spam detection, news topics, and research paper categories) using small models (TinyLlama-1.1B and Llama-3.2-3B). Here are the main takeaways:
- Replacing the usual similarity search with their Classifier-as-Retriever works really well.
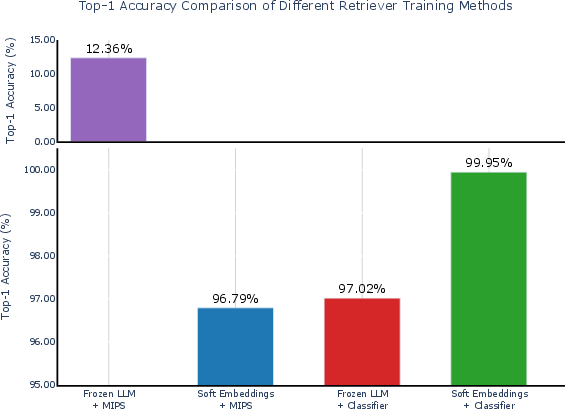
- On the SMS spam dataset, a standard similarity search did poorly (~12% accuracy).
- Training only the classifier head (no adapter) shot up to about 97% accuracy.
- Training both the adapter (soft embeddings) and the classifier head together performed best.
- Combined, they reached about 99.5–99.95% accuracy on the same task.
- The adapter helps the model “speak the language” of the new dataset, making the classifier’s job easier.
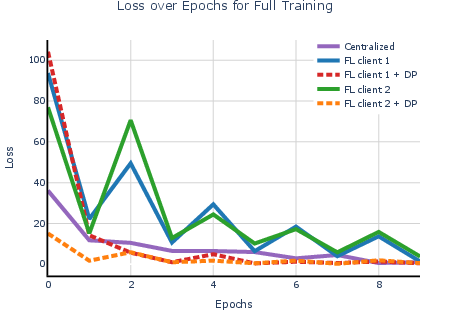
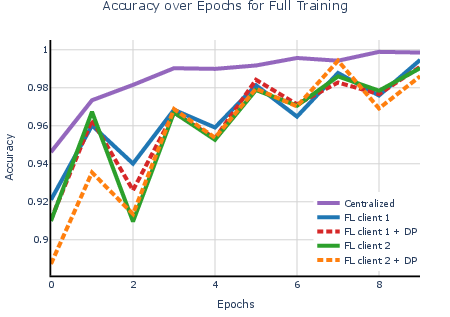
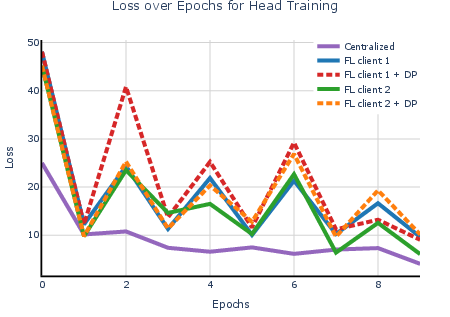
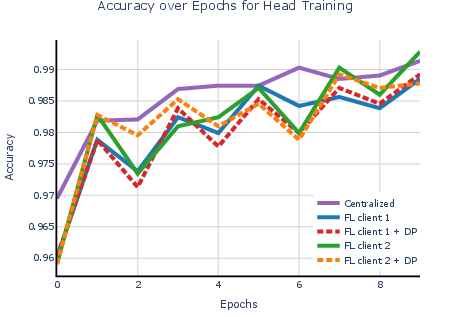
- Federated learning (distributed training) matched centralized accuracy and sped up training when the task was heavier.
- When they split the workload across 3 machines, they got up to ~2.6× speedup for the heavier training (adapter + classifier).
- Adding differential privacy caused only a small drop in accuracy.
- With DP turned on, performance stayed high while protecting users.
- The math supports that the method converges (doesn’t blow up or wander forever), even with privacy noise.
Why does this matter, and what could happen next?
- On-device AI: This approach makes it practical to update retrievers on small devices. You don’t need giant servers or to retrain entire models—just small parts.
- Better search for RAG: A learned classifier can understand task-specific similarity better than a one-size-fits-all math formula. That means more relevant documents and better answers.
- Privacy-friendly: Federated learning plus differential privacy lets organizations improve models without collecting users’ private data.
- Faster teamwork: Splitting work across devices brings real speedups, especially for heavier training.
- Future directions: The authors discuss scaling to even larger setups by:
- Sharing the heavy transformer blocks across servers (offloading) while devices keep training the small parts locally.
- Using “mixture of experts” (many small classifiers, each focused on a cluster of documents) to handle huge libraries efficiently.
In short, this paper shows a practical, private, and efficient way to make RAG systems smarter on new topics: adjust a tiny adapter to get better embeddings, use a classifier to retrieve smarter, train across many devices, and keep everyone’s data safe.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
This paper presents a novel methodology for retrieval-augmented generation using soft embeddings and federated learning. However, several aspects remain unexplored or could benefit from further investigation:
- Adapter Architecture Optimization: The paper utilizes a simple square transformation matrix for adapter insertion. Exploring alternative architectures for the adapter network, such as dynamic shapes or non-linear transformation layers, could potentially enhance the learning of soft embeddings.
- Efficiency of Distributed Load Offloading: While the paper discusses offloading transformer blocks across distributed clusters to optimize memory and computation, it does not detail the effectiveness or scalability of this approach in real-world scenarios. Future research should evaluate the performance and cost-benefit ratio of such distributed systems.
- Adaptive DP Scalability: The analysis of adaptive differential privacy (DP) is briefly mentioned in the context of federated learning without comprehensive empirical validation. Future work could focus on validating adaptive DP strategies across diverse datasets and larger model scales.
- Scalability of the Proposed Framework: Although the methodology aims to be scalable, detailed benchmarks or real-world implementations to assess scalability limits, especially in edge computing environments, are missing. Exploring scalability in terms of both computational resources and the number of edge devices could be beneficial.
- Comparison with Advanced Retrieval Methods: The paper demonstrates improvements over conventional maximum inner-product search (MIPS) but lacks comparison with other advanced retrieval techniques, such as using learned search indexes or transformer-based retrieval models.
- Integration with Existing Large Models: The paper proposes the usage of small LLMs (SLMs) due to resource constraints, but does not detail pathways for integrating with existing large-scale models more efficiently or effectively in practical applications.
- Privacy Trade-offs in Federated Learning with DP: While the added noise in DP helps preserve client privacy, there is no thorough exploration of the trade-offs between privacy preservation and model performance. Analyzing these trade-offs further, through varying noise scales and client diversity, could yield insightful results.
- Effectiveness of MoE in Edge Environments: Though the paper suggests using a mixture-of-experts (MoE) setup to handle large query-answer datasets, it does not provide empirical evidence on how efficient or feasible MoEs are within memory-constrained edge environments.
- Applicability Across Domains: The proposed approach is validated on text classification tasks but lacks empirical evidence across different data domains, such as multimedia or multi-modal data, which could be crucial for future applications in diverse fields.
- Security Considerations and Incentive Mechanisms: The mention of blockchain for secure communication and incentive mechanisms in federated learning highlights potential future directions but lacks specifics on implementation and scalability of these systems.
This list highlights areas that are either underexplored or present opportunities for subsequent research to refine the methodology and expand upon its applications.
Practical Applications
Immediate Applications
The following items can be deployed now with modest engineering effort, using the paper’s frozen SLM + adapter + classifier architecture, federated fine-tuning (FedAvg), and local differential privacy (DP).
- Bold application names denote the use case; sectors are indicated in parentheses. Each bullet summarizes the workflow and notes assumptions or dependencies that affect feasibility.
- On‑device enterprise RAG for private knowledge bases (software, enterprise IT)
- Workflow: Freeze an SLM retriever, insert the soft‑embedding adapter and a Classifier‑as‑Retriever (CaR) head; federated fine‑tune on departmental QA pairs; serve top‑K classifier outputs to an (optionally frozen) generator.
- Tools/products: CaR head plugin for common SLMs; FL orchestrator using gRPC; DP budget monitor; adapter tuner.
- Assumptions/dependencies: Labeled query–document pairs; device memory sufficient for SLM (1–3B params); policy approval for local DP; stable network for FL rounds.
- Customer support assistants with privacy-preserving domain adaptation (contact centers, software)
- Workflow: Agents’ machines fine‑tune adapters + CaR head on local ticket/email logs via FL; top‑K retrieval improves resolution quality without uploading raw text.
- Tools/products: Agent-side RAG SDK; central aggregator service; DP clipping/noise presets.
- Assumptions/dependencies: Sufficient label quality (query→solution mapping); quantized SLM for legacy hardware; DP parameter tuning to meet compliance.
- Healthcare clinical knowledge retrieval on‑prem (healthcare)
- Workflow: Hospital departments train adapters + CaR head on internal guidelines/EMR-derived QA pairs; inference runs behind firewall; FL across departments.
- Tools/products: On‑prem FL coordinator; DP audit tooling; EHR integration adapters.
- Assumptions/dependencies: Institutional review/compliance; strong DP settings; curated QA labels; generator guardrails for clinical use.
- Financial compliance search and audit (finance)
- Workflow: CaR-based retriever fine‑tuned via FL over policy/procedure manuals and historical filings; DP protects client text; top‑K outputs feed compliance report generation.
- Tools/products: Compliance RAG backend; DP logging and privacy accounting; adapter/CLF weight versioning.
- Assumptions/dependencies: Up‑to‑date, labeled domain corpus; regulator-approved privacy practices; controlled access to aggregator.
- Legal research and eDiscovery retrieval (legal services)
- Workflow: Train CaR head on case law citations and matter-specific QA; soft embeddings adapt SLM to firm-specific vocabulary; operate entirely on firm machines via FL.
- Tools/products: Case law CA(R) plugin; document management integration; DP metrics for client data.
- Assumptions/dependencies: High-quality labeled links (queries to precedents); compute for backprop through frozen transformer stack when training adapters.
- Academic literature assistants for domain-specific corpora (academia, research tooling)
- Workflow: Use arXiv or field-specific datasets to federate training across labs; adapters steer embeddings to subfield jargon; CaR produces relevant citations.
- Tools/products: Lab-scale FL coordinator; reproducible training recipes; MoE planning for large label spaces (optional later).
- Assumptions/dependencies: Availability of query–abstract/category labels; shared frozen generator acceptable; institutional DP policies.
- Campus/education knowledge search (education)
- Workflow: Departmental devices train CaR on course notes and FAQs via FL; top‑K retrieved snippets augment student queries for tutoring bots.
- Tools/products: LMS plugin; adapter/CLF training UI; DP settings aligned with FERPA-like policies.
- Assumptions/dependencies: Curated QA sets; student privacy requirements; device constraints (e.g., labs with Macs/PCs).
- Field service and IoT device manuals retrieval (manufacturing, IoT)
- Workflow: On-device retrievers with adapters + CaR head trained on troubleshooting QA; inference works offline; FL sync when network is available.
- Tools/products: Lightweight SLM builds with quantization; intermittent FL synchronization; DP noise scaled for small datasets.
- Assumptions/dependencies: Small memory footprint; robust tokenization for technical terminology; label availability.
- Spam/phishing detection with classifier head (security, communications)
- Workflow: Deploy CaR head for text classification (as demonstrated on SMS spam), optionally with soft embeddings to improve domain fit; federated training across user devices.
- Tools/products: Security agent plugin; FL coordinator; DP guardrails to protect user messages.
- Assumptions/dependencies: Sufficient supervised data; clear privacy posture; resourcing for adapter training if needed.
- Privacy-preserving personal assistants (daily life, consumer software)
- Workflow: On-device assistants adapt retriever to personal notes/emails using local CA(R) fine‑tuning; DP ensures parameters shared in FL don’t leak content.
- Tools/products: Mobile/desktop RAG SDK; DP budget tracker visible to user; local adapter/CLF management.
- Assumptions/dependencies: Device compute and storage; optional quantization to fit mobile; users consent to federated participation.
- Enterprise search modernization (vector DB alternative/hybrid) (software infrastructure)
- Workflow: Replace or augment MIPS-based retrieval with trainable CaR head for top‑K scoring; keep embeddings static or adapt via soft embeddings for domain-specific improvement.
- Tools/products: CaR scoring plugin for vector DBs; adapter training service; A/B testing harness.
- Assumptions/dependencies: Operator willingness to support classifier inference path; labeled data for training; monitoring for drift.
- Federated training proof-of-concept with gRPC (software engineering, DevOps)
- Workflow: Use the provided gRPC-based FL orchestration to validate speedups (1.75–2.62× in experiments) on small clusters; scale to departmental pilots.
- Tools/products: gRPC FL coordinator; model update synchronizers; convergence dashboards.
- Assumptions/dependencies: Stable network; harmonized local epochs/rounds; compatibility with chosen SLMs.
Long-Term Applications
These items are feasible with further research, scaling, or infrastructure investments (e.g., mixture-of-experts, load offloading, standardized privacy accounting).
- Distributed transformer block sharing service (Petals-like) for edge retrievers (software infrastructure, cloud/edge)
- Concept: Host frozen transformer blocks in clusters; clients run tokenization/soft embeddings locally, offload mid-stack compute, and finalize classification locally.
- Tools/products: “Transformer Hub” service; secure RPC; caching; autoscaling.
- Assumptions/dependencies: Robust latency/throughput; multi-tenant isolation; compatibility across SLM families; organizational buy-in.
- Hierarchical mixture-of-experts (MoE) CaR for massive corpora (software, search platforms)
- Concept: Cluster labels/documents; route queries to specialized classifier experts for scalable top‑K retrieval.
- Tools/products: Auto-clustering pipeline; gated MoE training framework; memory/compute budgeters for edge devices.
- Assumptions/dependencies: Reliable clustering quality; expert specialization reduces compute; careful gating design; ongoing maintenance.
- Cross-organization federated RAG networks (healthcare, finance, public sector)
- Concept: Multiple institutions jointly train adapters + CaR heads on shared schema without sharing raw data; DP ensures privacy across entities.
- Tools/products: Federated consortium governance; privacy accounting standards; cross-entity aggregators with audit trails.
- Assumptions/dependencies: Legal agreements; interoperable data labeling; DP epsilon bounds acceptable to regulators.
- Regulatory-grade DP governance and certification for FL RAG (policy, compliance)
- Concept: Standardize DP clipping/noise levels, reporting, and auditing for language systems; align with HIPAA/GDPR/CCPA.
- Tools/products: Compliance dashboards; third-party audits; DP budget certification pathways.
- Assumptions/dependencies: Industry consensus; regulators’ technical capacity; evolving legal frameworks for FL/DP.
- Marketplace for federated training with incentives (platforms, blockchain/fintech)
- Concept: Training agents subscribe to tasks, exchange encrypted model deltas, and receive micropayments for useful updates.
- Tools/products: Blockchain-backed parameter exchange; stake/slash mechanisms; quality scores for contributions.
- Assumptions/dependencies: Secure aggregation; robust contribution evaluation; economic viability; risk management.
- Energy-aware FL scheduling for edge LLMs (energy, IoT)
- Concept: Optimize FL rounds and adapter/CLF training to minimize energy use on edge devices; prioritize off-peak windows.
- Tools/products: Power-aware schedulers; lightweight quantization packs; device telemetry integration.
- Assumptions/dependencies: Granular device metrics; policy constraints for corporate devices; acceptable latency trade-offs.
- Hybrid retrieval engines combining CaR and MIPS (software, search)
- Concept: Use CaR for learned similarity and MIPS for recall/backoff; dynamically blend scores for robustness.
- Tools/products: Fusion scorer; retriever policy engine; online learning for blending weights.
- Assumptions/dependencies: Consistent performance monitoring; fallback design; label drift detection.
- Auto-labeling and weak supervision for CaR training (academia, tooling)
- Concept: Generate pseudo-labels from heuristics/logs; bootstrapped fine‑tuning of CaR head to reduce manual labeling burden.
- Tools/products: Weak supervision library; label quality estimators; iterative refinement workflows.
- Assumptions/dependencies: Initial signal quality; human-in-the-loop validation; bias mitigation.
- Personal multi-device FL for continuous private adaptation (consumer software)
- Concept: Seamless FL across a user’s devices; adapters + CaR head update with DP over time to reflect evolving personal corpora.
- Tools/products: Cross-device sync; local DP budget manager; conflict resolution for updates.
- Assumptions/dependencies: Secure device identity; reliable background processes; resource constraints on mobile.
- Sector-specific RAG platforms with domain adapters (vertical SaaS: healthcare, legal, finance, education)
- Concept: Prebuilt domain adapters and CaR templates per vertical; turnkey FL/DP deployments with best-practice defaults.
- Tools/products: Verticalized SDKs; compliance packs; monitoring and drift alarms.
- Assumptions/dependencies: Ongoing curation of domain corpora; support/ops capability; sustained product investment.
- Robust convergence tuning for heterogeneous clients (academia, MLOps)
- Concept: Advanced adaptive DP and learning-rate schemes for non-iid data and gradient heterogeneity; formal guarantees extended beyond the paper’s setting.
- Tools/products: Policy-based hyperparameter controllers; per-client adaptation; convergence analytics.
- Assumptions/dependencies: Extended theory and empirical validation; careful safety constraints; harmonized client telemetry.
Notes on feasibility across all applications:
- Dependencies include high-quality labeled query–document pairs, compatible SLMs that fit edge memory (often via quantization), reliable FL communication (e.g., gRPC), and DP parameter governance (clipping thresholds and noise scales tied to acceptable privacy budgets).
- Assumptions that matter: the generator quality (even when frozen), the stability of domain vocabulary, and organizational willingness to adopt FL/DP workflows.
- Potential bottlenecks: adapter backprop through the frozen transformer stack (compute cost), label scarcity, and scaling to very large corpora (addressed via MoE and load offloading in long-term items).
Glossary
- Adapter: A small trainable layer inserted into the encoder to transform token embeddings toward a target domain. "inserting a small adapter network before the transformer blocks of the SLM."
- Adapter tuning: A parameter-efficient fine-tuning method that trains only small adapters within an LLM. "adapter tuning \cite{houlsby2019parameter} fine-tunes only small-sized adapters inserted into the LLM,"
- Blockchain: A distributed ledger used to securely exchange model parameters among training agents. "model parameters could be encrypted and exchanged over blockchain, allowing multiple training agents to subscribe and join training groups"
- Classifier-as-Retriever (CaR): A retrieval method that uses a trainable classifier to select documents instead of a static similarity search. "we present a novel retrieval approach called ``Classifier-as-Retriever" (CaR),"
- Central Differential Privacy (Central DP): A DP setting where privacy noise is applied by a central server/aggregator. "unlike central DP, which is applied by a central aggregator"
- Central aggregator: The federated server that aggregates client updates into a global model. "shares the trained parameters of the soft embedding layer (local adapter parameters ) and the local classifier head () with the central aggregator."
- Clipping threshold: A bound on update norms used before adding DP noise to ensure privacy. "where is the clipping threshold for client ."
- Convergence guarantees: Theoretical assurances that the training process approaches a stationary solution under certain assumptions. "establishing convergence guarantees under mild assumptions on gradient variance"
- Differential Privacy (DP): A formal privacy framework that adds noise to limit information leakage about individuals. "we adopt federated learning (FL) and differential privacy (DP)"
- EOS token embeddings: The end-of-sequence token representations used as the final hidden state. "We take the hidden state to be the EOS token embeddings at the last layer unless otherwise stated."
- FedAvg: A federated optimization algorithm that aggregates client updates via weighted averaging. "We adopt the FedAvg \cite{mcmahan2017communication} method as the aggregation operation in our work,"
- Federated Learning (FL): Distributed training across multiple clients that keeps data local while sharing model updates. "we adopt federated learning (FL)"
- Frozen kNN retriever: A fixed nearest-neighbor retrieval component used to improve RAG without training the retriever itself. "employing a frozen kNN retriever followed by trainable attention layers"
- Gaussian noise: Random noise sampled from a normal distribution added to updates for DP. "a Gaussian noise with variance is added to the clipped difference"
- Gating mechanism: The router in a Mixture-of-Experts that directs inputs to the most appropriate expert. "the gating mechanism of the MoE directs the incoming input embeddings towards the best expert"
- gRPC protocol: A high-performance RPC framework used for client-server communication in distributed training. "communicate over the gRPC protocol."
- Gradient diversity: Variability among client gradients that reflects data heterogeneity across clients. "[Gradient diversity]"
- LLM: A high-parameter LLM pre-trained on vast corpora. "LLMs have shown promising breakthroughs in recent years"
- Lipschitz continuity: A smoothness property where gradient changes are bounded by a constant. "its gradient is -Lipschitz continuous."
- Load offloading: Distributing model components across servers to reduce client resource usage. "some works have focused on load offloading in which the LLM is decomposed and its blocks are distributed among multiple host servers"
- LoRA (Low-Rank Adaptation): A PEFT technique that adds low-rank matrices to LLM blocks to enable efficient fine-tuning. "low-rank adaptation (LoRA) \cite{hu2022lora} has been proposed as an alternative that does not alter the original LLM architecture, but adds low-rank matrices to its constituent blocks to fine-tune the LLM."
- Maximum inner-product search (MIPS): A similarity search that retrieves items with the largest dot product to a query vector. "using a maximum inner-product search (MIPS) to perform a similarity search"
- Maximum norm: The upper bound on the norm of clipped updates during DP. "ensures that the resulting clipped parameters have a maximum norm of ."
- Micropayments: Small payments used to incentivize participants contributing resources to training. "These agents could also receive micropayments as an incentive to contribute to the training process"
- Mixture of Experts (MoE): An architecture that uses multiple specialized expert classifiers with a gating router. "we design an MoE with the experts being classifier heads intended to solely classify the query-document pairs in a particular cluster."
- Non-convex loss functions: Objective functions without convexity; typical in deep neural network training. "general smooth non-convex loss functions"
- Norm head: A final normalization layer in the encoder that produces hidden states for downstream tasks. "and a final norm head layer."
- Parameter-efficient fine-tuning (PEFT): A family of methods that fine-tune a small subset of parameters to adapt large models. "Parameter-efficient fine-tuning (PEFT) \cite{ding2023parameter} has been proposed to partially fine-tune the LLMs and circumvent complete model training,"
- Prefix tuning: A PEFT method that prepends trainable prefix vectors to inputs. "prefix tuning \cite{li2021prefix} and prompt tuning \cite{lester2021power} prepend small and fixed prefix tokens to the input and only fine-tune them."
- Prompt tuning: A PEFT method that fine-tunes prompt tokens to steer model behavior. "prefix tuning \cite{li2021prefix} and prompt tuning \cite{lester2021power} prepend small and fixed prefix tokens to the input and only fine-tune them."
- Quantization: Reducing model parameter precision to lower memory and compute costs. "another line of research has studied quantization of LLMs"
- Retrieval-Augmented Generation (RAG): An LLM framework that augments prompts with retrieved documents to improve responses. "retrieval-augmented generation (RAG), where several similar documents to the input query are indexed from a given text corpus and augmented to the query as context"
- Retriever: The model component that selects relevant documents for a given query. "In our work, we present a novel retrieval mechanism by attaching classifier heads to the retriever."
- Small LLM (SLM): A compact LLM suitable for deployment on resource-constrained devices. "using a frozen small LLM (SLM)"
- Soft embeddings: Trainable embeddings adapted to a new corpus via an inserted adapter. "learns to produce enhanced soft embeddings for it"
- Stationarity point: A point where the gradient norm is small, indicating near-convergence. "Stationarity point for constant learning rate and fixed DP"
- Stochastic gradient: A gradient estimate computed from a mini-batch of data. "to compute a stochastic gradient "
- Token embeddings: Vector representations produced by the tokenizer for input tokens. "The trainable adapter takes the token embeddings of the new corpus"
- Top-K: Selecting the K highest-scoring items (documents) for retrieval. "The top- outputs of this classifier are then augmented to the input query"
- Transformer blocks: The stacked attention-based layers that form the core of LLM encoders. "before the transformer blocks of the SLM"
- Weighted averaging: Aggregation that weights client updates (e.g., by data size) when forming the global model. "client updates are aggregated via weighted averaging to train the global model."
- Local Differential Privacy (Local DP): DP applied on the client side before sending updates to an aggregator. "we focus on local DP, which ensures client-side privacy—unlike central DP, which is applied by a central aggregator"
Collections
Sign up for free to add this paper to one or more collections.