- The paper introduces SWiRL, a method that generates synthetic multi-step trajectories for improved complex reasoning and tool use.
- It demonstrates performance improvements of 11.1% to 21.5% on tasks like GSM8K and HotPotQA, highlighting strong cross-task generalization.
- The study emphasizes the importance of process-based data filtering and scalability in model training, enhancing robustness even without tool access.
Introduction
Step-Wise Reinforcement Learning (SWiRL) introduces a novel methodology for multi-step optimization, targeting complex reasoning tasks that require text generation and environmental interaction. Traditional RL approaches, such as RLHF and RLAIF, often treat these tasks as single-step processes, which are not conducive to tasks requiring multiple steps of reasoning and tool usage. SWiRL addresses this by generating multi-step synthetic trajectories and applying step-wise reinforcement learning on these data, allowing for effective decomposition of complex problems and improved performance across a variety of tasks.
Methodology
The SWiRL strategy is divided into two stages. Stage 1 involves generating multi-step synthetic data, where a model, optionally with access to tools such as search engines or calculators, creates multi-step reasoning trajectories.
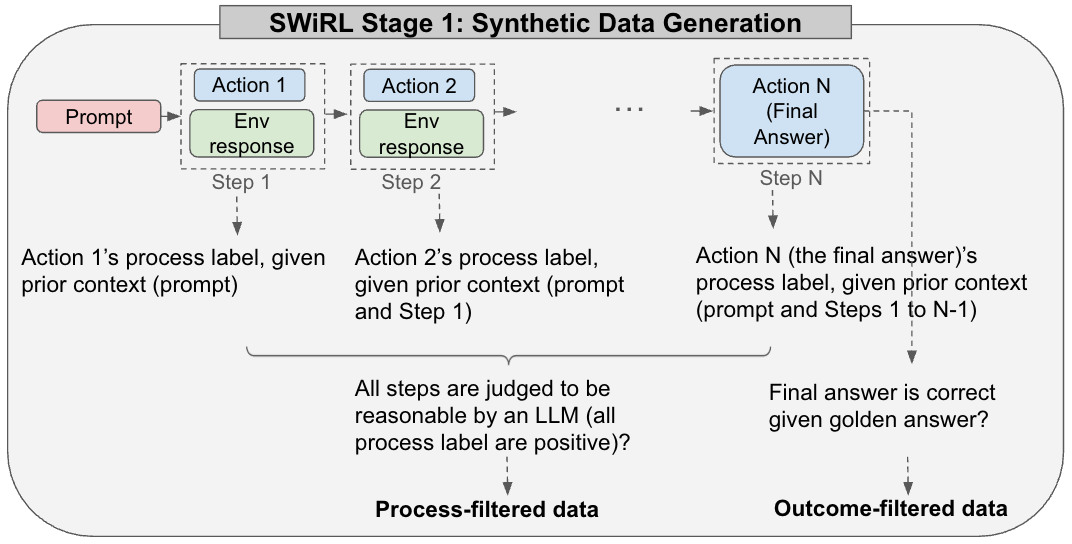
Figure 1: In SWiRL Stage 1, multi-step synthetic trajectories are generated, enabling the use of a chain of thought, tools, and end-answer synthesis.
Each step in a trajectory consists of actions and tool calls, evaluated by a model judge for rationale correctness. Stage 2 utilizes these trajectories to fine-tune the base model via step-wise reinforcement learning, optimizing actions individually with model-based feedback.
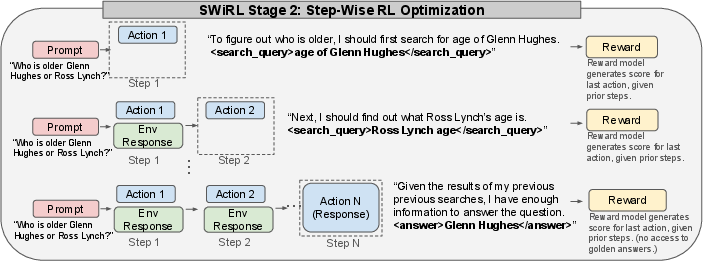
Figure 2: SWiRL Stage 2 uses step-wise RL for each synthetic trajectory, improving multi-step learning through granular feedback on actions.
Experiments
Experiments demonstrate SWiRL's superior performance over baseline models in several tasks, such as GSM8K, HotPotQA, and others, with improvements ranging from 11.1% to 21.5% relative accuracy. Particularly noteworthy is the transfer ability across different tasks: training exclusively on HotPotQA led to a 16.9% improvement in zero-shot performance on GSM8K.
Impact of Data Filtering
SWiRL's efficacy relies critically on process-based data filtering, which selects trajectories judged reasonable at each step by a model-based process reward model. This category outperforms unfiltered and outcome-filtered setups, highlighting the importance of step-wise soundness in training data.
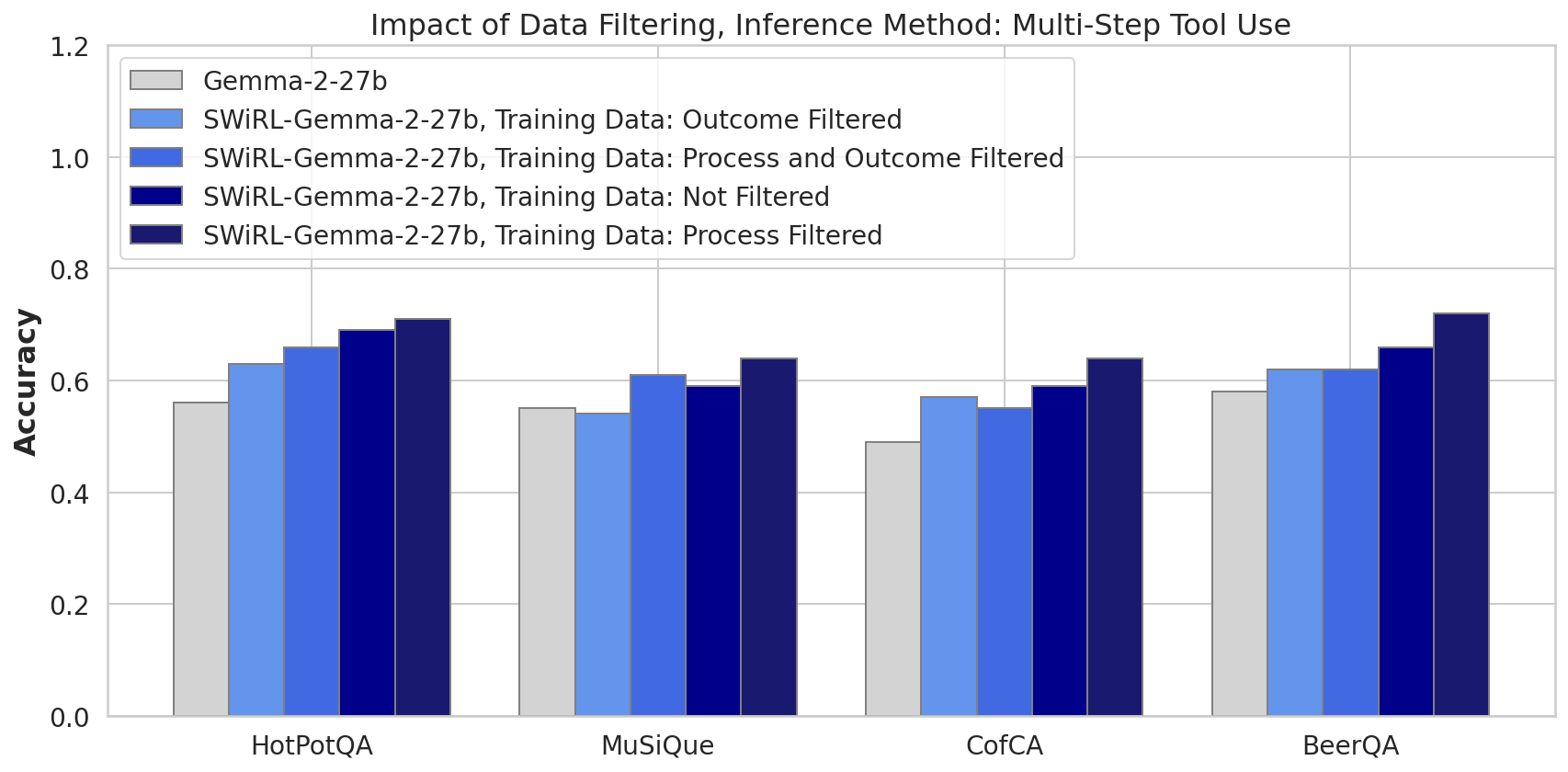
Figure 3: Filtering strategies reveal process-filtered data significantly enhances model performance.
Generalization Across Tasks
SWiRL shows marked generalization capabilities, where training on datasets such as HotPotQA enhances performance on disparate datasets like GSM8K, demonstrating an improved ability to manage multi-step reasoning and tool usage.
Comparison with Supervised Fine-Tuning
SWiRL demonstrates significant advantages over SFT, showing higher accuracy and robustness, due to its ability to generalize and adapt to various data filtering strategies and not rely heavily on final outcome correctness.
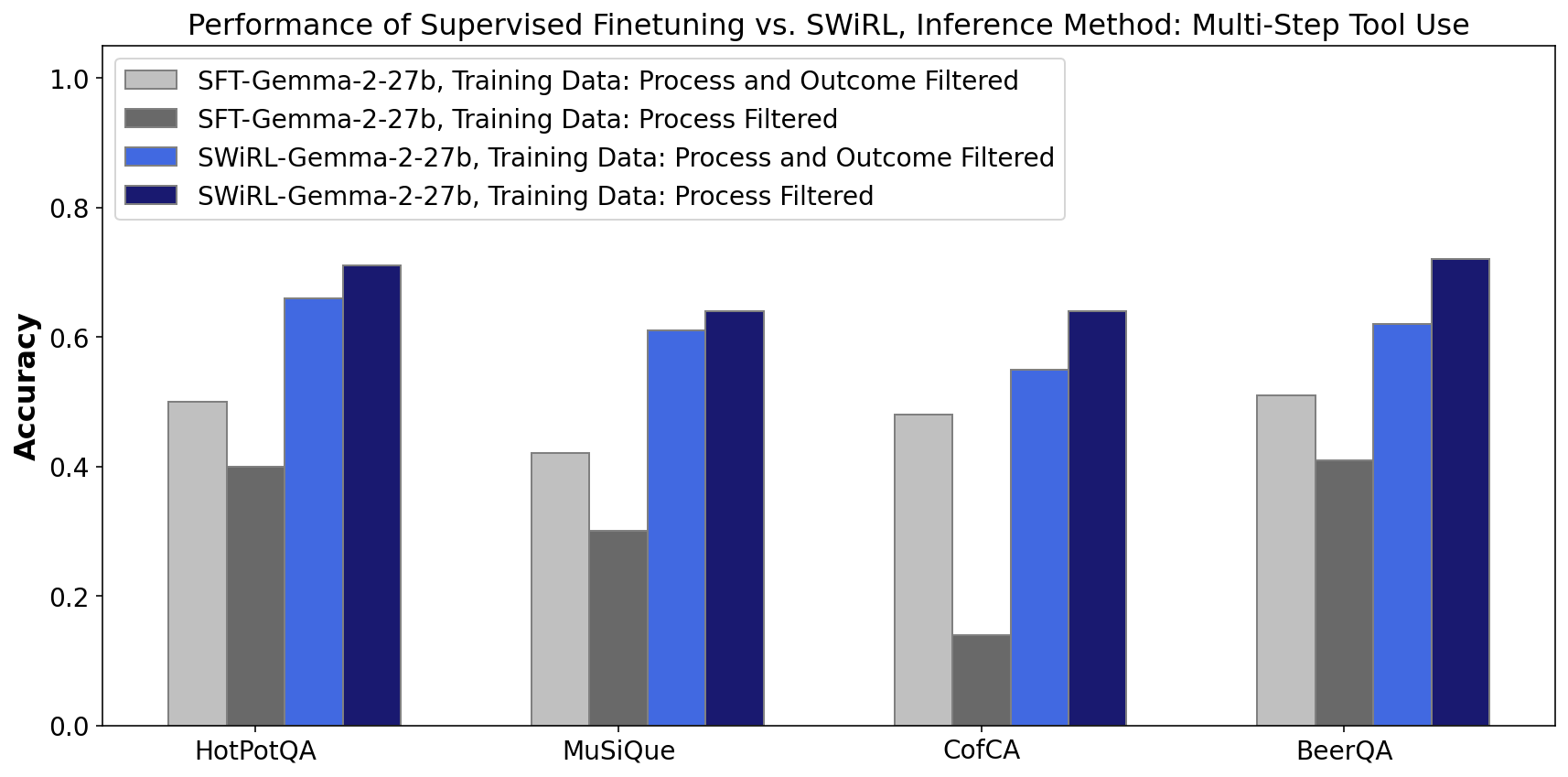
Figure 4: Comparing SFT and SWiRL, the latter excels due to its process-filtered data learning.
Tool usage at inference time under SWiRL guidance shows remarkable improvement in tackling complex queries more efficiently, although the trained model also exhibits strong performance even without tool access.
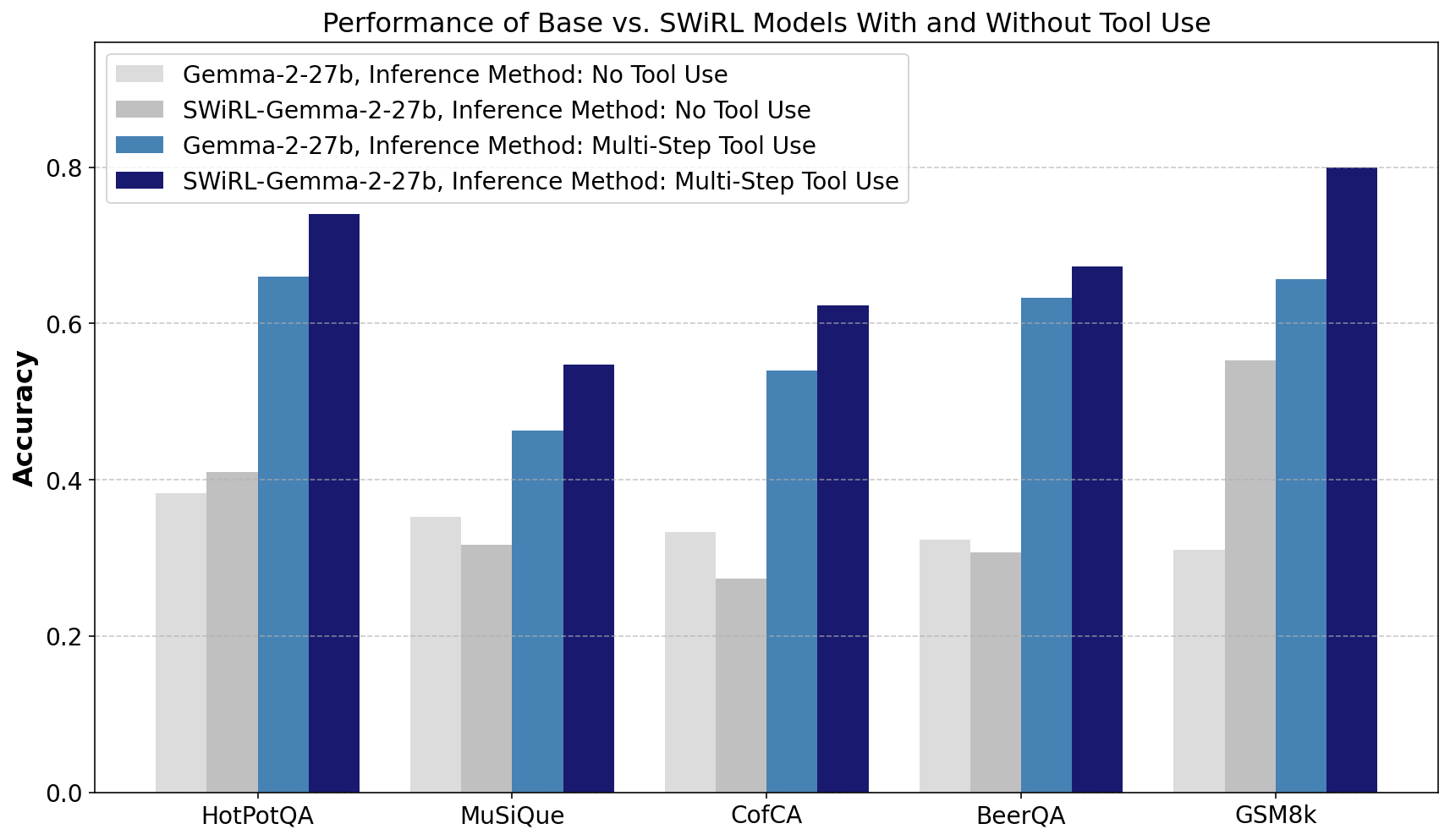
Figure 5: SWiRL boost in performance with and without tool use highlights its decomposition capacity in complex problems.
Dataset and Model Size Scalability
Performance increases with dataset size, suggesting the scalability of SWiRL in handling larger synthetic datasets for effective learning. Model size experiments highlight that larger models benefit more significantly from SWiRL's multi-step learning optimization.
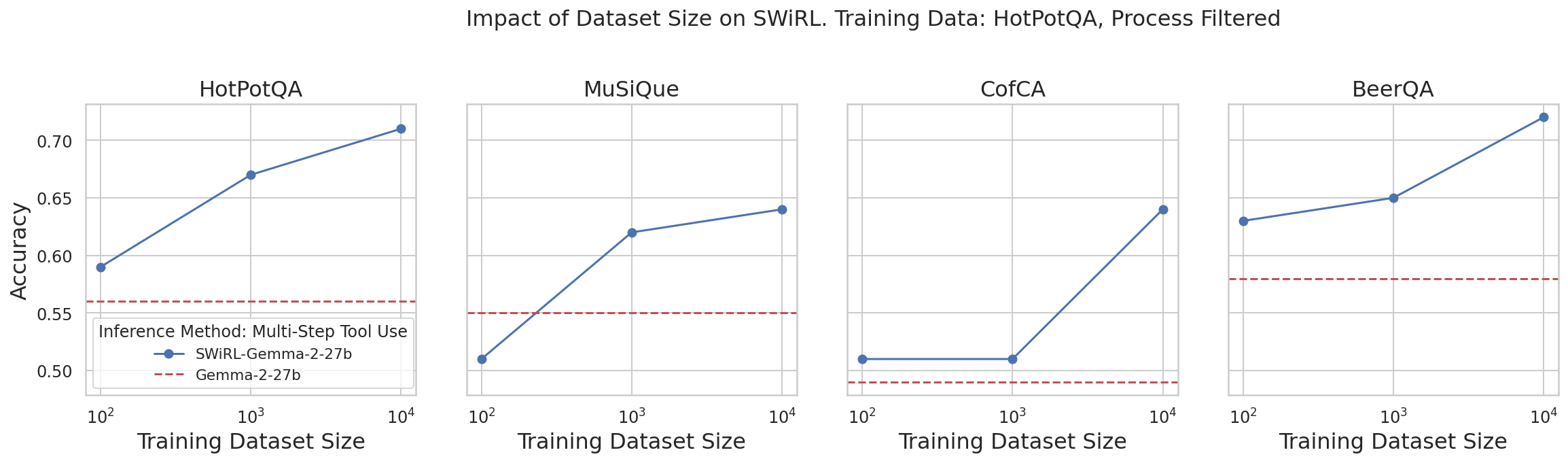
Figure 6: Successive dataset scaling results in consistent performance improvements.
Conclusion
SWiRL's innovative approach to multi-step reasoning and tool use demonstrates significant advantages in complex task optimization. Through synthetic data generation and reward model-guided optimization, it effectively surpasses traditional RL techniques in accuracy and generalization.
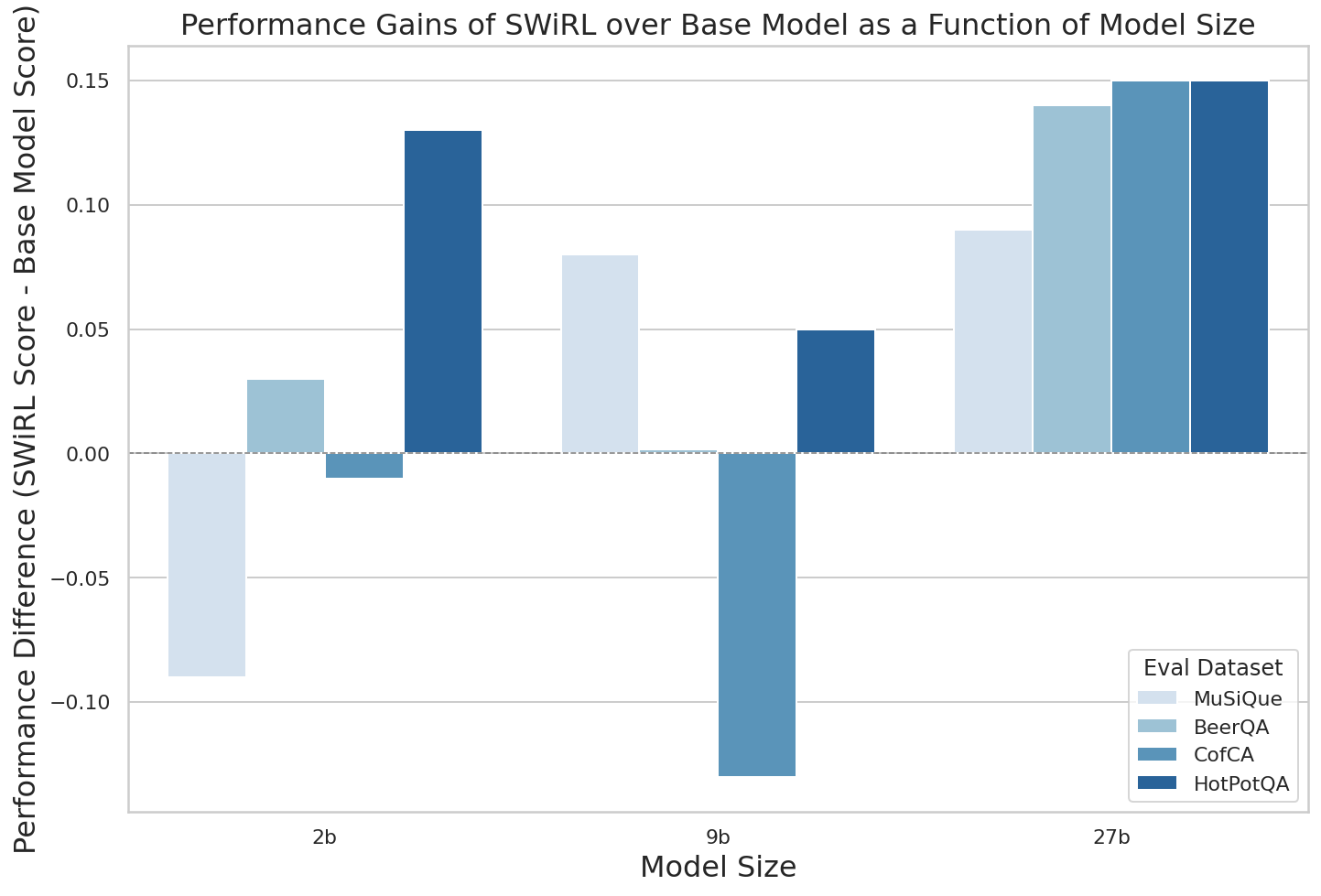
Figure 7: The effectiveness of SWiRL escalates with model size, attaining the most consistent improvements with larger models.

