- The paper introduces a novel diffusion-based framework that integrates environmental context to enable high-fidelity character animation.
- It employs a shape-agnostic mask strategy and object guider to enhance character-environment fusion and preserve interactive details.
- Experimental results demonstrate superior metrics (SSIM, PSNR, LPIPS, FVD) and robust pose modulation for handling diverse motions.
Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance
The paper "Animate Anyone 2: High-Fidelity Character Image Animation with Environment Affordance" focuses on enhancing the fidelity and coherence of character image animations by integrating environmental context into the animation process. Existing methods often lack the ability to effectively animate characters with their surrounding environments, leading to disjointed interactions. This work introduces a novel framework that addresses these limitations by capturing and incorporating environmental features, thereby enabling high-fidelity animations with environment affordance.
Framework and Methodology
The proposed framework, Animate Anyone 2, employs a diffusion-based approach to synthesize animated sequences from reference character images and source videos. A key innovation is the integration of environmental representations as conditional inputs, allowing the model to produce animations that reflect the context of the surrounding environment.
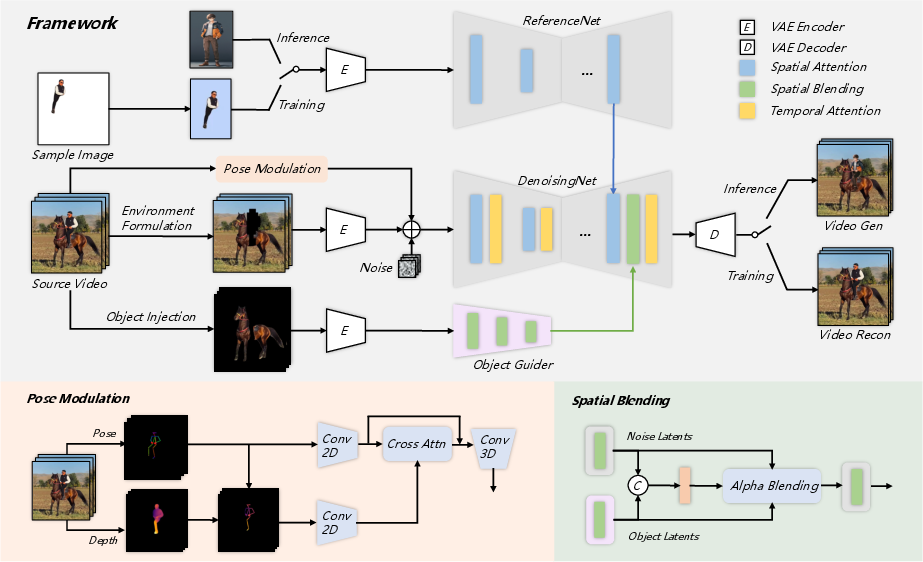
Figure 1: The framework of Animate Anyone 2. We capture environmental information from the source video, enabling end-to-end learning of character-environment fusion.
Environment Representation and Object Interaction
The environment is formulated by excluding character regions in the source video, allowing the model to generate characters that fit seamlessly into these spaces. A shape-agnostic mask strategy is introduced to improve the representation of boundary relationships between characters and environments, mitigating shape leakage and enhancing integration.
To preserve object interactions, an object guider extracts features of objects that interact with the character. This information is merged into the denoising process through spatial blending, preserving intricate interaction dynamics from the source video (Figure 2).
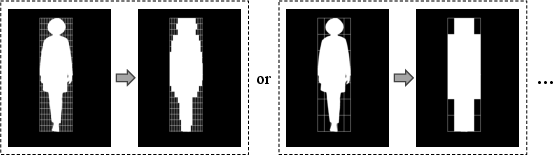
Figure 2: Different coefficients for mask formulation.
Pose Modulation and Motion Handling
The framework handles diverse motions through a pose modulation strategy, which better represents the spatial relationships between body limbs (Figure 3). This approach enhances the model's robustness in managing various motion patterns while maintaining character consistency.

Figure 3: Qualitative Results. Animate Anyone 2 achieves consistent character animation while enabling integration between characters and environments.
Experimental Results
Extensive experiments demonstrate that the proposed method surpasses existing character animation techniques in several metrics, including SSIM, PSNR, LPIPS, and FVD. Qualitative results highlight the model's ability to produce animations with high fidelity and seamless environment interaction, as illustrated in Figure 4, where backgrounds are normalized for visual comparison.

Figure 4: Qualitative comparison for character animation. We normalize the background to a uniform color.
Figure 5 further exemplifies the method's superiority in environment integration and object interaction compared to baseline methods.

Figure 5: Our method demonstrates superior environment integration and object interaction.
Ablation Studies and Limitations
A series of ablation studies were conducted to evaluate the effectiveness of the environment formulation strategy and object modeling approach (Figures 6 and 7). These studies confirm the significant contributions of each component to the overall performance.

Figure 6: Ablation study of environment formulation.
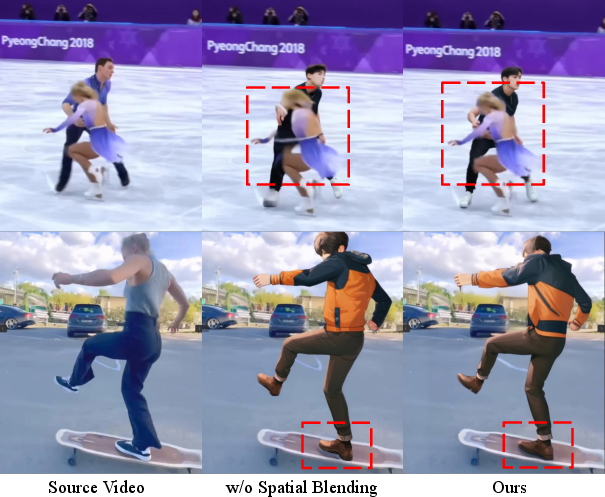
Figure 7: Qualitative ablation of object modeling method.
The paper acknowledges limitations, such as the potential for visual artifacts in complex scenes and interactions, and the influence of segmentation accuracy on performance.
Conclusion
Animate Anyone 2 presents a comprehensive solution for high-fidelity character animation with environment affordance. By incorporating environmental contexts and employing advanced pose modulation strategies, the framework achieves superior character-environment integration. This work lays the groundwork for future developments in character animation, emphasizing the importance of contextual awareness and interaction in animated content. Further research might explore enhancements in interactive object segmentation and integration to address identified limitations.