- The paper introduces a universal animation framework that employs enhanced motion representation, including Implicit and Explicit Pose Indicators, to preserve identity across diverse characters.
- The paper utilizes a 3D-UNet with CLIP-based feature extraction and simulated misalignment training to robustly generate animation from arbitrary reference and motion inputs.
- The paper demonstrates superior performance on the A²Bench with higher PSNR and SSIM, outperforming state-of-the-art methods in qualitative and quantitative evaluations.
Animate-X: Universal Character Image Animation with Enhanced Motion Representation
The paper "Animate-X: Universal Character Image Animation with Enhanced Motion Representation" presents Animate-X, a framework designed specifically for enhancing character image animation capabilities across a broad range of character types. The method introduces novel techniques that improve upon existing animation models, especially by addressing limitations in motion representation that hinder generalization to non-human characters.
Problem Statement and Method Overview
Character image animation processes typically generate high-quality videos using a reference image and a sequence of pose inputs. However, most conventional techniques are heavily centered around human figures and often perform poorly on anthropomorphic or stylized characters found in gaming and animation industries. This paper addresses these shortcomings by developing Animate-X, a framework based on Latent Diffusion Models (LDM) for universal application across diverse character types, referred to collectively as "X."
Enhanced Motion Representation
The central advancement in Animate-X lies in its approach to motion representation. Traditional methods impose a target pose sequence rigidly onto characters, often distorting identity features in non-human characters. Animate-X innovates by incorporating the Pose Indicator—a combination of implicit and explicit techniques aimed at capturing the essence of motion more comprehensively.
- Implicit Pose Indicator (IPI): Utilizes CLIP image features to extract nuanced motion patterns that go beyond mere skeleton-based pose data, preserving essential identity features.
- Explicit Pose Indicator (EPI): Simulates various pose configurations during training to enhance model robustness against discrepancies between reference images and driven poses during inference.
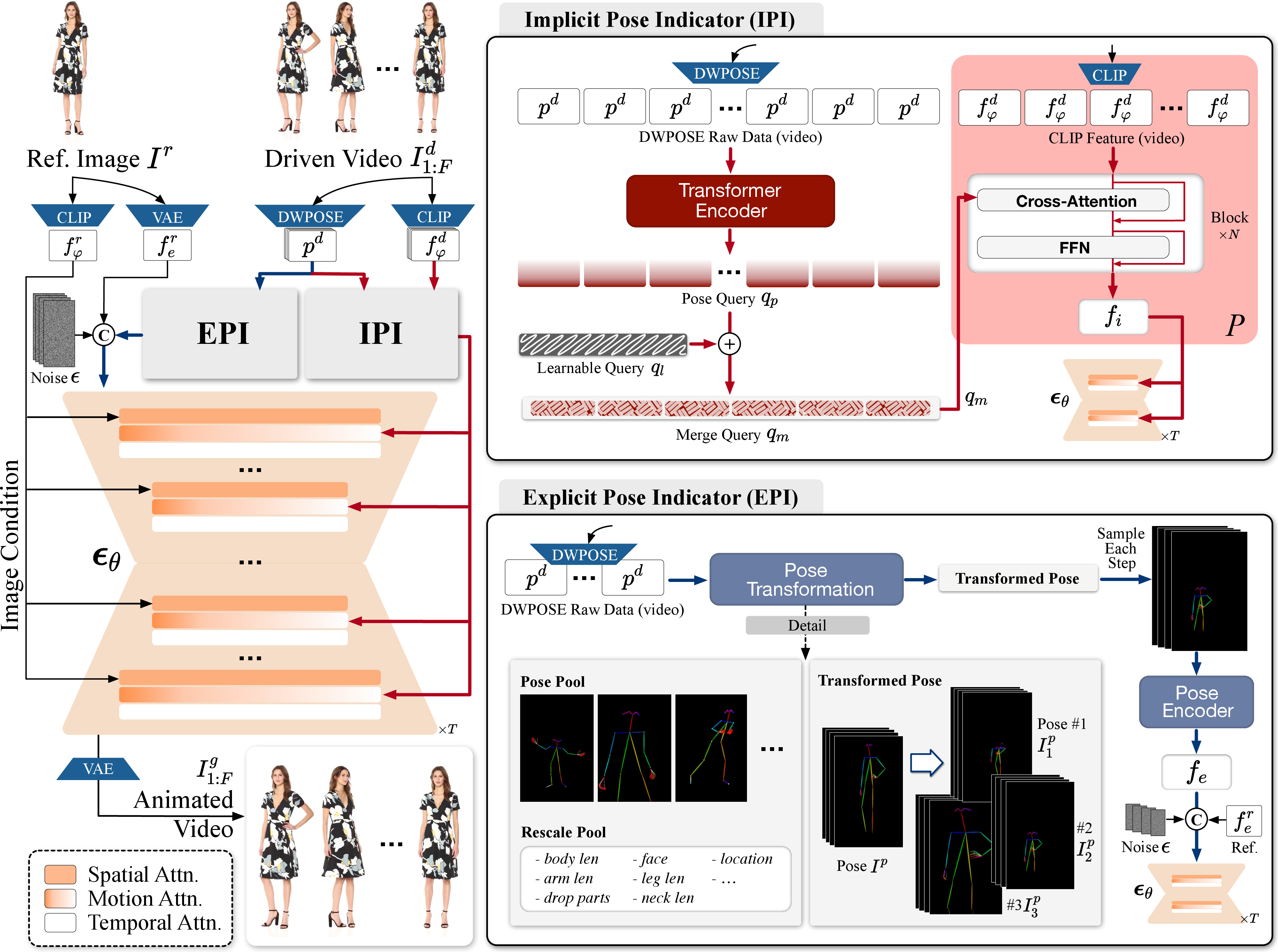
Figure 1: (a) The overview of our Animate-X. Given a reference image Ir, we first extract CLIP image feature fφr and latent feature fer via CLIP image encoder Φ and VAE encoder E. The proposed Implicit Pose Indicator (IPI) and Explicit Pose Indicator (EPI).
Implementation Details
Architecture
Animate-X employs a 3D-UNet as its backbone for video generation, leveraging CLIP for feature extraction. Motion features are extracted through IPI, which incorporates cross-attention layers and feed-forward networks employing queries derived from both keypoints and learnable embeddings. The explicit pose indicator ensures robustness by generating explicit pose features aligned via training with simulated pose misalignments.
Training and Inference
Training involves simulating potential misalignments between reference and driving inputs to bolster model resilience in varied animation scenarios. Inferentially, the system enables arbitrary coupling of reference images and driven videos, extending applicability well beyond conventional datasets.
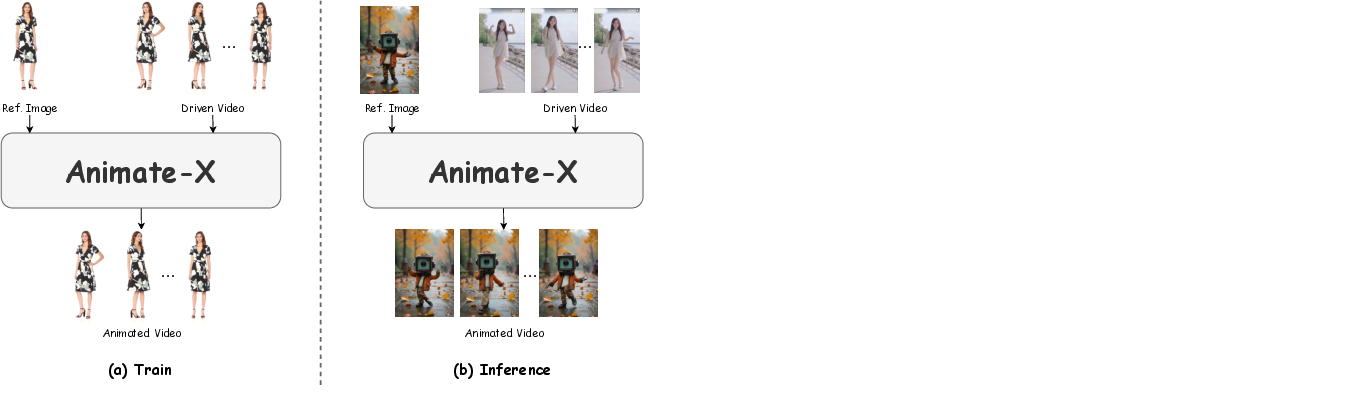
Figure 2: The difference of training and inference pipeline. During training, the reference image and the driven video come from the same video, while in the inference pipeline, the reference image and the driven video can be from any sources and appreciably different.
Experiments and Results
The paper introduces the "Animated Anthropomorphic Benchmark" (A2Bench), which evaluates the efficacy of Animate-X across diverse anthropomorphic characters. Extensive experiments showcase superior qualitative and quantitative results compared to state-of-the-art methods, highlighting improvements in identity preservation and motion consistency.
Conclusion
This study demonstrates significant advances in the domain of character image animation, primarily through the innovative use of enhanced motion representation techniques. By bridging the gap between human-centric and universal character animation, Animate-X sets a precedent for future developments in this field. Its comprehensive framework not only expands the applicability of character animation to a broader spectrum of character designs but also provides an effective solution to the limitations posed by previous methodologies in maintaining identity fidelity amidst diverse motion scenarios. Future work may explore refining hand and facial modeling and improving real-time capabilities.
