- The paper introduces ReSum, a novel approach that continuously summarizes interaction histories to overcome context window limitations in LLM-based web search tasks.
- It employs a specialized ReSumTool-30B and a ReSum-GRPO algorithm, yielding significant performance improvements over existing ReAct methods in benchmarks.
- The evaluation demonstrates that ReSum efficiently manages long-horizon search with minimal architectural changes, paving the way for enhanced agent autonomy.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
This essay provides an authoritative examination of the paper titled "ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization" (2509.13313). ReSum is introduced as a novel paradigm targeting the context limitations inherent in long-horizon search tasks conducted by web agents using LLMs. The primary goal is to enable indefinite exploration by continuously converting interaction histories into compact reasoning states, thus bypassing context constraints. This paradigm is systematically evaluated across benchmarks, demonstrating significant improvements over existing methods such as ReAct.
Introduction and Motivation
LLMs-based agents have become pivotal in executing complex, knowledge-intensive tasks. Their application often involves web agents performing iterative cycles of search, browse, and synthesis. A crucial obstacle encountered is the context window limitation; agents indoctrinated with paradigms like ReAct swiftly exhaust their context budget, leading to premature termination before task completion, as illustrated (Figure 1).
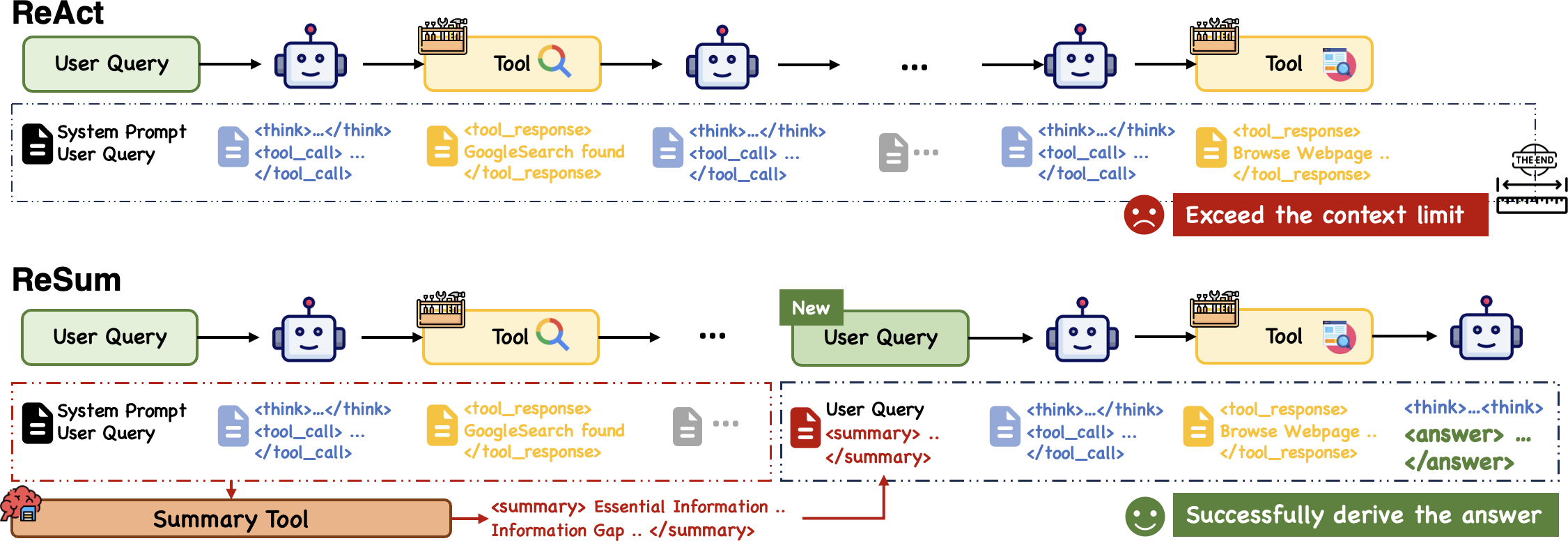
Figure 1: Comparison between ReAct~\citep{yao2023react and ReSum paradigms.
Consider complex queries requiring sophisticated search cycles and extensive evidence collection. ReSum emerges as a solution, periodically summarizing long interaction histories to sustain exploration without exceeding the context limit. This facilitates a seamless shift in focus from raw data accumulation to compressed, actionable states enabling continued reasoning. The technique minimizes modifications to the existing ReAct framework, retaining efficiency and simplicity.
Methodology
ReSum Paradigm
ReSum operates through key phases:
- Trajectory Initialization: Start with the user query, building upon each interaction (thought, action, observation) to update the conversation history.
- Context Summarization: When summary-trigger conditions—such as approaching token limits—are met, a summary tool compresses the history into a compact state, aiding in proactive context management (Figure 2).
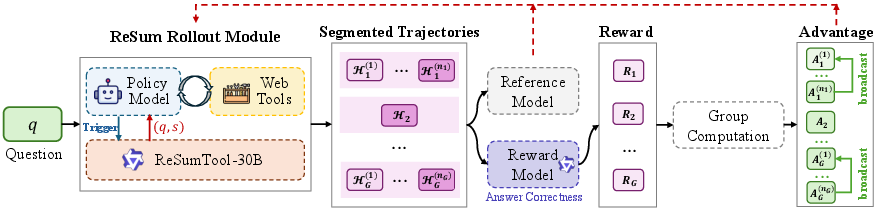
Figure 2: Illustration of ReSum-GRPO.
- Trajectory Termination: Despite enabling extensive exploration, practical deployments impose a tool call budget, designating the trajectory as complete or as failure upon limit breaches.
ReSum excels by implementing a structured summary tool tailored to distill key evidence and information gaps from interactions, reinforcing an agent's ability to pursue long-horizon searches efficiently.
In ReSum, generic models are integrated as summarizers. Yet, deploying the ReSumTool-30B enriches summarization capabilities through specialized training on pairs extracted from models like Qwen3-30B-A3B. Extensive evaluations affirm ReSumTool-30B's superiority over larger models in terms of summarization quality—a testament to its task-specific enhancements.
ReSum-GRPO Algorithm
To advance agents with summary-conditioned reasoning, ReSum embraces Reinforcement Learning (RL) through the ReSum-GRPO. This approach nurtures self-evolution without altering ingrained skills, contending with trajectory segmentation based on summary interactions and leveraging trajectory-level advantages to revitalize learning signals across segments.
Experimental Evaluation
Extensive experiments highlight that ReSum paradigms outperform ReAct by facilitating extended exploration phases. Training-free implementations showcase considerable performance gains, with ReSumTool-30B outperforming larger models and enabling agents such as WebSailor-30B to approach proprietary models' performance levels across various benchmarks.
Likewise, ReSum-GRPO complements training with refined, paradigm-oriented RL processes, ensuring agents adeptly negotiate complex inquiries with long trajectories—aided by continuous summarization.
Implications and Future Developments
ReSum offers a promising optimism in advancing LLM-agent capabilities, particularly by addressing inherent context limitations with minimal architectural alterations. Future trajectories point towards enhancing agent autonomy in self-summarization and optimizing summary invocation, potentially eliminating reliance on external tools and pre-set rules.
Conclusion
ReSum presents a methodical enhancement over legacy paradigms for web agent exploration, facilitating refined reasoning states and extending inquiry capabilities bound by traditional context windows. Its integration via ReSum-GRPO encourages agents to master summary-driven reasoning, pivot towards sophisticated understanding, and unveils possibilities for further algorithmic and practical innovations in LLM agent designs.

