- The paper introduces a comprehensive pipeline to reconstruct dynamic 3D smoke assets from a single in-the-wild video using robust segmentation, pose estimation, and multi-view inference.
- It incorporates Gaussian particle training to achieve physically plausible simulations with a +2.22 dB PSNR improvement over baselines on real and synthetic datasets.
- The method produces simulation-ready assets that support realistic editing and interactions, offering valuable applications in VFX, diagnostics, and scientific visualization.
WildSmoke: Dynamic 3D Smoke Asset Reconstruction from Single In-the-Wild Videos
The paper introduces a comprehensive pipeline for reconstructing dynamic 3D smoke fields from a single unconstrained video captured in the wild. The motivation stems from the limitations of prior fluid reconstruction methods, which depend on controlled multi-view laboratory setups with calibrated cameras and clean backgrounds. In contrast, real-world smoke videos exhibit noisy backgrounds, unknown camera poses, and a single camera trajectory that couples spatial and temporal viewpoints, making the reconstruction of physically plausible, temporally consistent, and editable 3D smoke assets a challenging task.
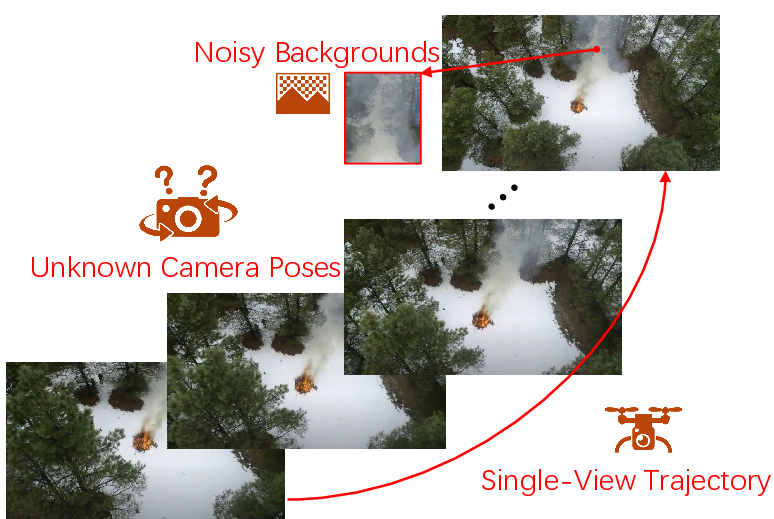
Figure 1: Challenges of smoke reconstruction from a single in-the-wild video: 1) noisy backgrounds and boundaries; 2) unknown camera poses; 3) single video with coupled camera viewpoints and timesteps.
Pipeline Overview
The proposed pipeline consists of five stages: smoke extraction, pose estimation and coarse geometry initialization, multi-view inference, Gaussian particle training, and simulation-ready asset composition.
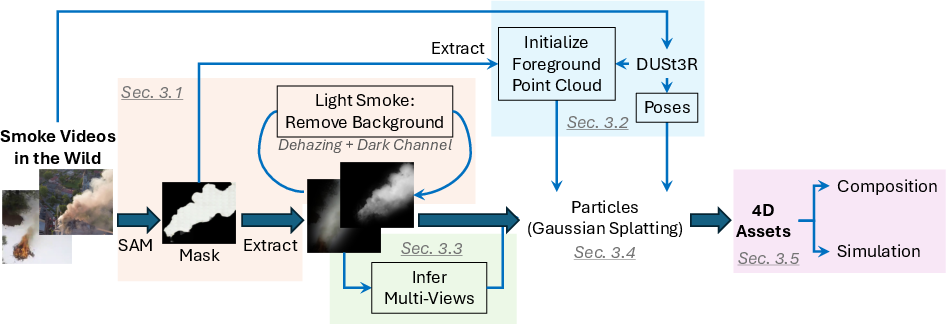
Figure 2: The WildSmoke pipeline: 1) smoke extraction and background removal; 2) pose estimation and 3D point cloud initialization; 3) multi-view inference; 4) Gaussian particle training; 5) simulation-ready 4D asset composition.
Smoke Extraction and Background Removal
Smoke segmentation is performed using a hybrid approach: SAM for interactive annotation and SegGPT for mask propagation. For light smoke, where background leakage is significant, a fine-tuned DehazeFormer is used to remove background artifacts, leveraging a synthetic dataset constructed by blending extracted smoke with clean backgrounds. Dense smoke is handled directly via mask extraction.

Figure 3: Smoke extraction, with background removal for light smoke.
Camera Pose and Particle Initialization
Camera intrinsics and extrinsics are estimated using DUSt3R, which also provides a sparse 3D point cloud. The point cloud is filtered using the extracted smoke masks to initialize both physical and visual particles, providing spatial priors for subsequent optimization.
Multi-View Inference and Local Pose Perturbation
To decouple the inherent coupling between camera viewpoint and timestep in single-camera videos, the pipeline generates auxiliary multi-view supervision using SV4D 2.0, synthesizing novel views at various azimuth angles. Additionally, local pose perturbation is introduced by shifting camera poses within a short temporal window, further enriching the view trajectory and improving generalization for novel-view synthesis.
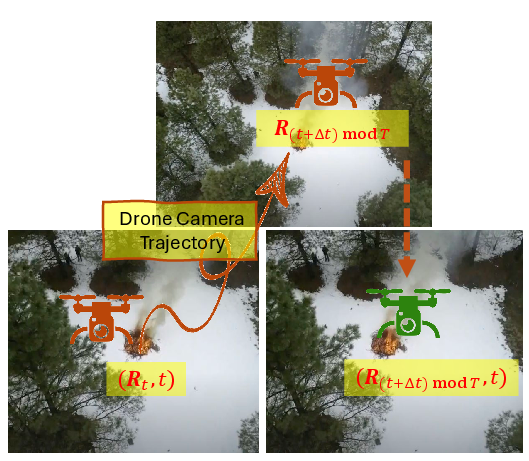
Figure 4: Local pose perturbation: original and perturbed camera poses are used to decouple viewpoint and timestep during training.
Gaussian Particle Training
Visual and physical particles are optimized using 3D Gaussian Splatting, minimizing photometric errors between rendered and input frames. Physical particles are regularized via position-based fluid simulation with incompressibility constraints. The density and velocity fields are constructed from the learned particle attributes, enabling physically consistent simulation.
Experimental Results
Synthetic Data
On synthetic smoke videos, the pipeline achieves superior PSNR for both novel view synthesis and future prediction tasks compared to HyFluid, FluidNexus, and Trellis. Notably, the pipeline yields a +2.22 dB PSNR improvement on in-the-wild videos. Ablation studies demonstrate that each component—smoke extraction, DUSt3R initialization, local perturbation, and multi-view supervision—contributes incrementally to reconstruction fidelity.

Figure 5: Visualization of novel view synthesis and future predictions on synthetic smoke videos.
Real-World Data
On the FLAME dataset and diverse videos from Pixabay, the method consistently outperforms baselines in future prediction tasks, maintaining stable reconstructions and blending seamlessly with original backgrounds.

Figure 6: Visualization of future predictions (input view) on the FLAME dataset.

Figure 7: Visualization of future predictions (input view) on videos collected from Pixabay.
Simulation and Editing
The reconstructed assets are directly usable for interactive simulation in PhiFlow. The pipeline supports realistic editing scenarios, including wind forces and obstacle interactions, demonstrating the physical plausibility and editability of the reconstructed smoke fields.

Figure 8: Simulations with reconstructed smoke assets under wind and obstacle interactions.
Implementation Considerations
The pipeline is modular and leverages pretrained models (SAM, SegGPT, DehazeFormer, DUSt3R, SV4D 2.0) for segmentation, dehazing, pose estimation, and multi-view generation. Gaussian particle training is computationally efficient, requiring 4–6 GPU-hours for full reconstruction at 1080p resolution over 270 frames. The use of DUSt3R for pose initialization reduces the need for excessive particle seeding, accelerating convergence. The pipeline is robust to both light and dense smoke, and the multi-view generation strategy mitigates overfitting to the single camera trajectory.
Implications and Future Directions
The WildSmoke pipeline enables the extraction of physically plausible, temporally consistent, and editable 3D smoke assets from unconstrained real-world videos, addressing a critical gap in graphics and simulation workflows. The approach generalizes to diverse smoke scenarios and supports downstream applications in VFX, diagnostics, and scientific visualization. The integration of generative multi-view synthesis and local pose perturbation provides a blueprint for handling spatiotemporal coupling in other dynamic scene reconstruction tasks.
Theoretically, the work demonstrates the feasibility of reconstructing high-dimensional fluid fields from severely underconstrained visual data, leveraging advances in segmentation, generative modeling, and differentiable simulation. Future research may extend the pipeline to other fluid phenomena (e.g., fire, fog), incorporate more sophisticated physical priors, and explore end-to-end differentiable training across all pipeline stages. The approach also suggests potential for foundation models in scientific machine learning, where real-world data is noisy and multi-view supervision is unavailable.
Conclusion
WildSmoke presents a unified solution for reconstructing dynamic 3D smoke assets from single in-the-wild videos, overcoming challenges of noisy backgrounds, unknown camera poses, and spatiotemporal coupling. The pipeline achieves strong quantitative and qualitative results, supports physically consistent simulation, and is computationally efficient. The methodology sets a new standard for ready-to-use fluid asset generation from unconstrained visual data, with broad implications for graphics, simulation, and scientific computing.