- The paper introduces the RAS paradigm that integrates dynamic retrieval with structured knowledge to mitigate LLM limitations like hallucination and outdated information.
- It systematically categorizes retrieval methods—from sparse to dense—and evaluates advanced structuring techniques such as taxonomy enrichment and knowledge graph construction.
- The survey outlines challenges including scalability, knowledge quality assurance, and human-AI collaboration, offering a roadmap for future research in LLM augmentation.
Retrieval and Structuring Augmented Generation with LLMs: A Comprehensive Survey
Introduction
The surveyed work provides a systematic and in-depth analysis of the Retrieval And Structuring (RAS) paradigm, which augments LLMs by integrating dynamic information retrieval with structured knowledge representations. The motivation for RAS arises from the persistent limitations of LLMs in real-world deployments, including hallucination, outdated knowledge, and insufficient domain expertise. The survey delineates the evolution from classical Retrieval-Augmented Generation (RAG) to the more advanced RAS paradigm, emphasizing the synergy between retrieval mechanisms and knowledge structuring for robust, factual, and context-aware language generation.
Foundations: LLMs and Retrieval-Augmented Generation
The paper begins by categorizing LLM architectures into encoder-only, encoder-decoder, and decoder-only models, each optimized for distinct NLP tasks. It details the multi-stage training pipeline—pre-training, supervised fine-tuning, and reinforcement learning—highlighting the role of in-context learning and chain-of-thought prompting in enhancing LLM adaptability and reasoning.
Retrieval-Augmented Generation (RAG) is positioned as a foundational approach, where external knowledge is retrieved and incorporated into the LLM's context window to mitigate hallucination and knowledge staleness. The survey distinguishes between sparse, dense, and hybrid retrieval methods, and discusses advanced RAG workflows such as adaptive, iterative, and recursive retrieval. The modularization of RAG pipelines, including context reranking and compression, is shown to be critical for both efficiency and retrieval quality.
The survey provides a granular taxonomy of retrieval methods:
- Sparse Retrieval: Techniques like TF-IDF and BM25 remain competitive due to their efficiency and interpretability, especially in low-resource or domain-specific settings. Neural sparse retrieval (e.g., SPLADE, DeepCT) leverages transformer-based reweighting for improved semantic matching.
- Dense Retrieval: Dual-encoder architectures (e.g., DPR, ColBERT) enable semantic retrieval via vector similarity, but require large-scale labeled data and suffer from reduced interpretability.
- Hybrid and Generative Retrieval: Hybrid models combine sparse and dense signals for robustness, while generative retrieval leverages LLMs to directly generate document identifiers, offering improved performance and interpretability in certain settings.
Recent advances include data augmentation (e.g., doc2query, Inpars), query rewriting/expansion (e.g., DeepRetrieval, s3), and multi-stage reranking with LLMs, which have demonstrated significant improvements in retrieval effectiveness across open-domain and specialized tasks.
Text Structuring: Taxonomies, Classification, and Information Extraction
The structuring of unstructured text is addressed through three main axes:
- Taxonomy Construction and Enrichment: Methods such as HiExpan, CoRel, and TaxoCom automate the expansion and enrichment of taxonomies, leveraging PLMs and clustering for both flat and hierarchical structuring.
- Text Classification: The survey covers both flat and hierarchical classification, with recent advances in prompt-based and weakly-supervised methods (e.g., CARP, TELEClass) that exploit LLMs' reasoning and generalization capabilities.
- Information Extraction: Entity mining (NER, FET, UFET) and relation extraction are discussed, with LLM-based approaches (e.g., GPT-NER, RelationPrompt, QA4RE) showing strong performance in low-resource and generative settings. The limitations of traditional evaluation metrics for generative RE are highlighted, with GenRES proposed as a more comprehensive framework.
Knowledge structuring is further extended to knowledge graph construction, database population, and tabular data organization, with LLMs increasingly used for end-to-end extraction, completion, and reasoning over structured data.
The RAS Paradigm: Integration of Retrieval and Structuring
The core contribution of the survey is the formalization of the RAS paradigm, which unifies information retrieval, structured knowledge representation (e.g., taxonomies, KGs), and LLM-based generation. The RAS workflow is characterized by iterative cycles of retrieval, structuring, and generation, where structured representations guide both the retrieval process and the grounding of LLM outputs.
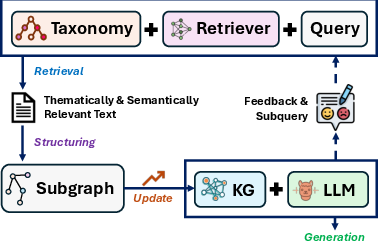
Figure 1: An abstractive example of the RAS paradigm, illustrating the iterative integration of taxonomy-enhanced retrieval, knowledge graph construction, and LLM-based generation for comprehensive and accurate responses.
Structure-Enhanced Retrieval
Taxonomy-guided retrieval (e.g., ToTER, TaxoIndex) and KG-based retrieval (e.g., KG-RAG, HippoRAG, GFM-RAG) are shown to improve both precision and recall, particularly in theme-specific and multi-hop reasoning tasks. The survey emphasizes the importance of aligning retrieval strategies with the underlying knowledge structure, enabling more targeted and contextually relevant information access.
Structure-Enhanced LLM Generation
The integration of structured knowledge into LLM generation is categorized into:
- Early Approaches (PLM + KG): Neural and rule-based methods (e.g., KG-BART, QA-GNN) fuse KGs with PLMs for improved commonsense reasoning and explicit multi-hop inference.
- Modern Approaches (LLM + KG): Recent frameworks (e.g., ToG, GoT, Graph CoT, RoG, ChatRule, MindMap, ORT) enable LLMs to reason directly over KGs, leveraging graph traversal, planning, and rule mining for faithful and interpretable outputs.
- KG-Embedded LLMs: Approaches like GraphToken and G-Retriever encode graph structure into LLMs via soft-token prompts and graph encoders, supporting scalable and efficient graph reasoning.
- Structure Summarization: Methods such as GraphRAG and KARE condense complex knowledge structures into textual summaries, facilitating global corpus understanding and interpretable reasoning.
Technical Challenges and Research Opportunities
The survey identifies several open challenges:
- Retrieval Efficiency: Scaling retrieval to large corpora and complex queries while maintaining low latency.
- Knowledge Quality: Ensuring the accuracy, coherence, and domain alignment of automatically constructed taxonomies and KGs.
- Integration: Reconciling heterogeneous knowledge sources and supporting incremental updates.
Key research opportunities include:
- Multi-modal Knowledge Integration: Extending RAS to handle images, audio, and video alongside text.
- Cross-lingual Systems: Building language-agnostic taxonomies and KGs for global knowledge sharing.
- Interactive and Self-Refining Systems: Leveraging reinforcement learning and meta-learning for autonomous error correction and user-guided refinement.
- Human-AI Collaboration: Incorporating expert and crowd-sourced feedback for taxonomy and KG maintenance.
- Personalized Knowledge Delivery: Adapting retrieval and structuring to individual user profiles and privacy constraints.
Conclusion
This survey establishes RAS as a comprehensive paradigm for augmenting LLMs with dynamic retrieval and structured knowledge, addressing critical limitations in factuality, recency, and domain expertise. The integration of advanced retrieval strategies, automated structuring, and LLM-based reasoning enables more robust, interpretable, and context-aware language generation. The outlined challenges and research directions underscore the need for continued innovation in scalable retrieval, knowledge quality assurance, and adaptive integration, with significant implications for the future of knowledge-intensive AI systems.

