- The paper presents innovative multimodal retrieval-augmented generation methods that reduce hallucinations and enhance factual accuracy using diverse data sources.
- It categorizes approaches into retrieval strategies, fusion mechanisms, augmentation techniques, and generation methods, evaluated with nearly 60 distinct metrics.
- The study highlights challenges in cross-modal reasoning and outlines future research to improve robustness in real-time, multimodal AI applications.
A Comprehensive Overview on Multimodal Retrieval-Augmented Generation
Introduction
The paper "Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation" (2502.08826) explores the nuanced and rapidly advancing field of Multimodal Retrieval-Augmented Generation (RAG). Traditional LLMs face substantial challenges such as hallucinations and reliance on static data, which limit their applicability to real-world, dynamic contexts. Retrieval-Augmented Generation has emerged as a promising solution by incorporating external and up-to-date data, which significantly enhances factual accuracy and reduces hallucinations.
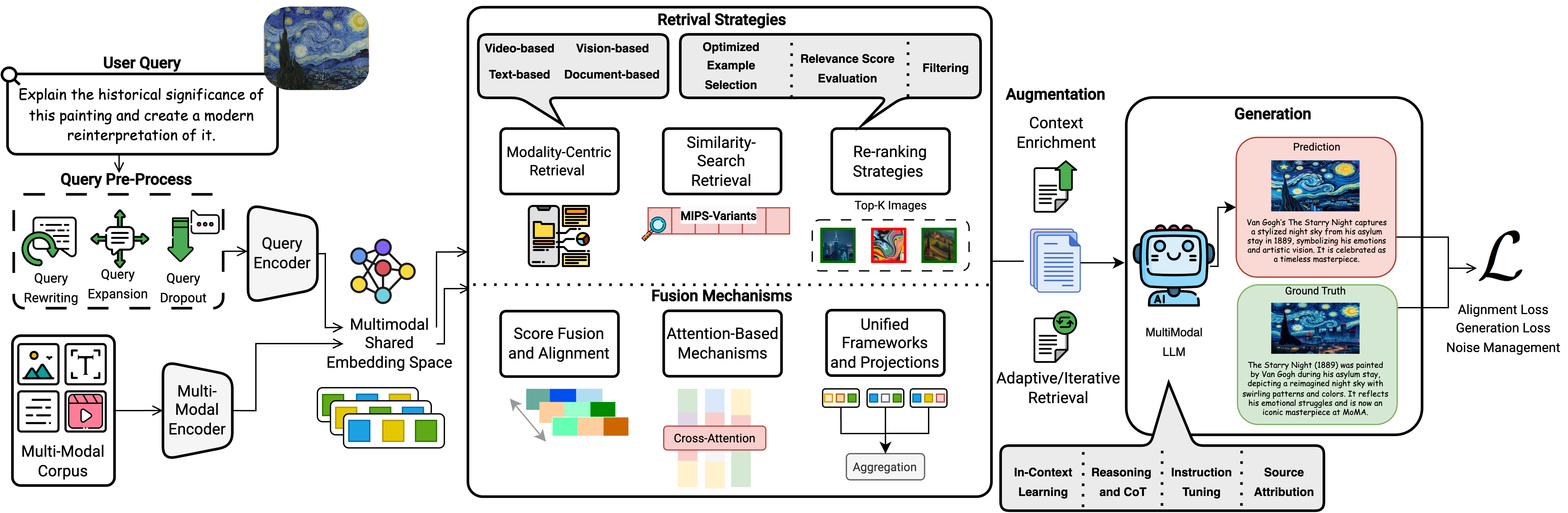
Figure 1: Overview of the multimodal retrieval-augmented generation (RAG) pipeline, highlighting the advancements and techniques employed at each stage.
Background and Motivation
The foundational underpinning of this research lies in the integration of multimodal data—text, images, audio, and video—into Retrieval-Augmented Systems, thereby propelling their utility far beyond single-modal RAG architectures. Advances in multimodal learning, characterized by models such as CLIP, have revolutionized AI's ability to correlate information across disparate data types. Despite this, these developments introduce unique challenges in cross-modal alignment and reasoning, necessitating innovative methodologies.
Contributions and Key Insights
Comprehensive Taxonomy and Methodologies
The paper systematically reviews the current landscape of Multimodal RAG, including datasets, evaluation metrics, and methodologies. The authors categorize recent innovations into distinct domains—retrieval strategies, fusion mechanisms, augmentation techniques, and generation methodologies:
- Retrieval Strategies: Emphasizes efficiency and cross-modal compatibility using architectures like CLIP and BLIP, leveraging Maximum Inner Product Search (MIPS) for rapid document retrieval.
- Fusion Mechanisms: Outline advanced methods like score fusion and attention-based techniques, instrumental in aligning and integrating data from different modalities.
- Augmentation Techniques: Discusses context enrichment and iterative retrieval processes that refine retrieval outputs to better support complex querie.
- Generation Techniques: Highlight the importance of in-context learning, instruction tuning, and evidence transparency for generating coherent, factual, and evidence-backed responses.
Evaluation and Benchmarking
The paper meticulously evaluates current systems using approximately 60 distinct metrics, ensuring comprehensive analysis across vision-LLMs, generative AI, and retrieval systems. The benchmark datasets and metrics propel our understanding of these systems' capabilities and limitations, as reflected in practical applications ranging from healthcare to software engineering.
Theoretical and Practical Implications
Addressing Multimodal Challenges
Multimodal RAGs are positioned to tackle complex tasks by enabling more holistic information processing capabilities, thereby actively contributing to the advancement of AI towards artificial general intelligence (AGI). The theoretical implications lie in overcoming cross-modal reasoning difficulties—how systems interpret and generate responses based on multimodal inputs.
Future Directions
Despite significant advancements, difficulties like handling complex video queries, ensuring source attribution, and dealing with inadequate datasets remain. The paper advocates for future research focusing on improving the robustness of multimodal RAGs, especially in real-time applications, which include autonomous systems and personalized AI solutions.
Conclusion
The paper "Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation" serves as a crucial resource for understanding the state of Multimodal RAG systems. It maps the terrain of existing research, tackles ongoing challenges, and identifies future opportunities to refine AI systems. By thoroughly examining the integration of multimodal inputs, the paper sets the stage for advanced research endeavors that aim to overcome current limitations and enhance AI applications across eclectic domains.

