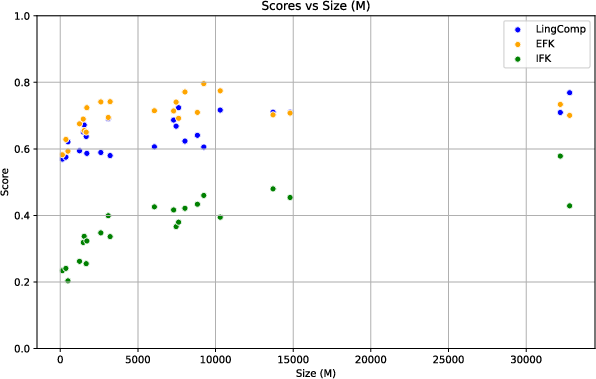
- The paper finds that linguistic competence plateaus with increased size while internal factual knowledge scales sharply, highlighting a decoupling opportunity.
- The methodology rigorously benchmarks models from 135M to 32B parameters using tests like WiC, BLiMP, RTE, MNLI, and QQP.
- Results support a modular approach where smaller FLMs, aided by external fact retrieval, can maintain robust language processing.
Towards Fundamental LLMs: Does Linguistic Competence Scale with Model Size?
Introduction
The paper entitled "Towards Fundamental LLMs: Does Linguistic Competence Scale with Model Size?" explores the feasibility of separating linguistic competence from factual knowledge in LLMs. This separation is articulated through the Fundamental LLM (FLM) paradigm, which advocates for smaller, linguistically competent models that rely on external tools for factual retrieval. The paper evaluates a range of models from 135 million to 32 billion parameters, aiming to discern whether linguistic competence scales in tandem with model size or if it stabilizes, thus supporting a modular approach to language modeling.
Theoretical Perspective
The FLM paradigm is introduced as a solution to address the limitations faced by monolithic LLMs, such as hallucinations, biases, and high computational costs. Traditional LLMs embed both factual and linguistic information, which can result in inefficient models once external retrieval could suffice for factual data. The FLM approach posits that linguistic competence, defined by the model's ability to understand and generate language structures (e.g., grammar and semantics), can be maintained in smaller models. This suggests that scaling larger models predominantly enhances factual memorization rather than core linguistic proficiency.
Methodology
The paper systematically evaluates models across three dimensions: linguistic competence, external factual knowledge, and internal factual knowledge. Using benchmarks from the LM Evaluation Harness, such as WiC for lexical competence, BLiMP for grammatical competence, and RTE, MNLI, and QQP for semantic competence, the authors examine whether model size impacts core language abilities. Models from various families like SmolLM2, Qwen2.5, Llama-3, and more, are assessed with parameter sizes ranging from 135M to 32B.
Results and Analysis
The results reveal a nuanced perspective on scaling LLMs:
Regression Analysis and Statistical Tests
The analysis included linear regression, with log(Size) proving a more accurate predictor for internal factual knowledge than for linguistic competence. The regression slopes illustrate that factual knowledge scales more sharply with model size than linguistic competence. Moreover, Mann-Whitney U tests suggest significant performance gains mainly occur when comparing models at the extremes of size (small vs. large), particularly in factual knowledge tasks.
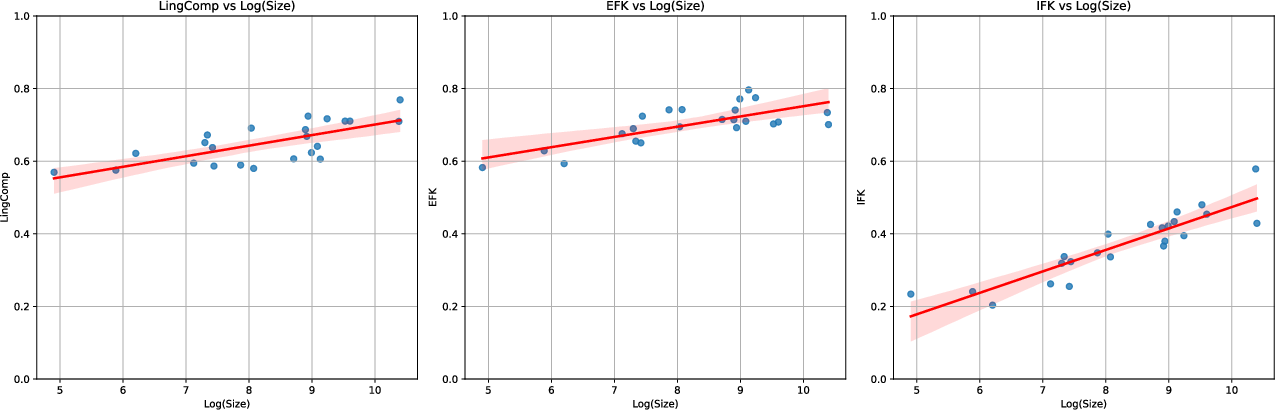
Figure 2: Linear regressions for each competence against log(Size) in million parameters.
Discussion
The findings validate the FLM approach, proposing that linguistic competence can be decoupled from factual knowledge, thus informing the design of more efficient and interpretable models. By externalizing factual retrieval to specialized systems, smaller models can maintain robust linguistic capabilities. This modular design aligns with cognitive models and offers a promising path towards sustainable AI applications.
Conclusion
This study provides evidence supporting the development of Fundamental LLMs, which focus on separating linguistic competence from factual knowledge. The results advocate for smaller, specialized models that efficiently handle language processing while relying on external systems for factual information, potentially transforming NLP infrastructures.
This modular approach not only enhances model efficiency but also paves the way for more adaptable and scalable AI systems, with implications for the future of artificial intelligence research and application.