How Multimodal LLMs Solve Image Tasks: A Lens on Visual Grounding, Task Reasoning, and Answer Decoding
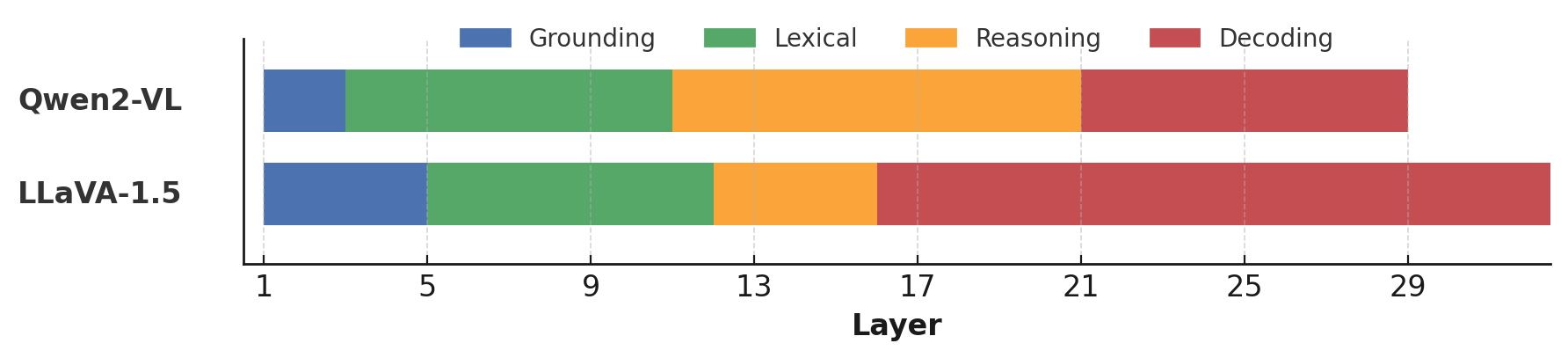
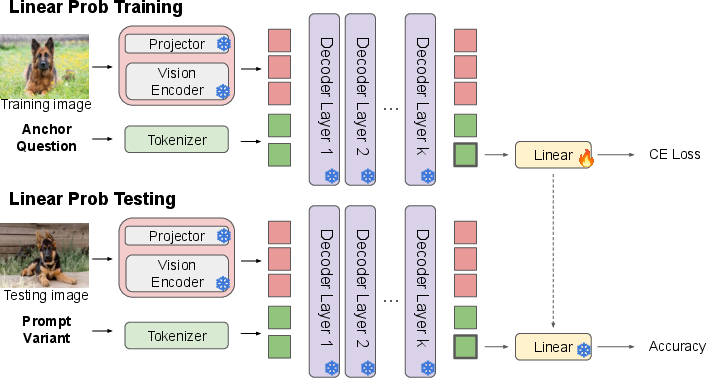
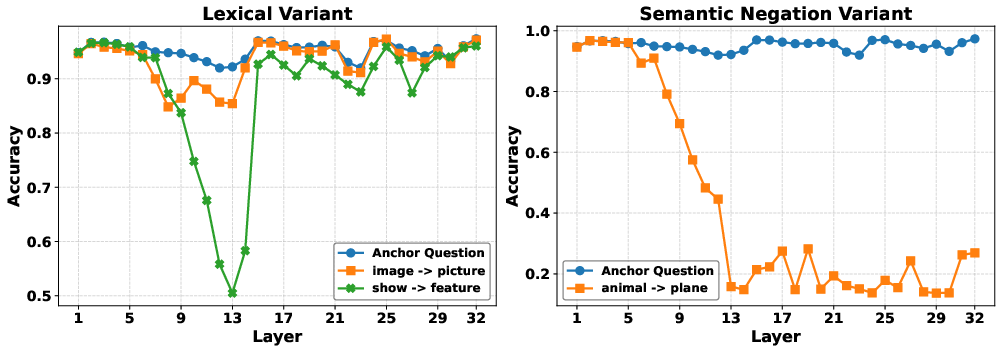
Abstract: Multimodal LLMs (MLLMs) have demonstrated strong performance across a wide range of vision-language tasks, yet their internal processing dynamics remain underexplored. In this work, we introduce a probing framework to systematically analyze how MLLMs process visual and textual inputs across layers. We train linear classifiers to predict fine-grained visual categories (e.g., dog breeds) from token embeddings extracted at each layer, using a standardized anchor question. To uncover the functional roles of different layers, we evaluate these probes under three types of controlled prompt variations: (1) lexical variants that test sensitivity to surface-level changes, (2) semantic negation variants that flip the expected answer by modifying the visual concept in the prompt, and (3) output format variants that preserve reasoning but alter the answer format. Applying our framework to LLaVA-1.5, LLaVA-Next-LLaMA-3, and Qwen2-VL, we identify a consistent stage-wise structure in which early layers perform visual grounding, middle layers support lexical integration and semantic reasoning, and final layers prepare task-specific outputs. We further show that while the overall stage-wise structure remains stable across variations in visual tokenization, instruction tuning data, and pretraining corpus, the specific layer allocation to each stage shifts notably with changes in the base LLM architecture. Our findings provide a unified perspective on the layer-wise organization of MLLMs and offer a lightweight, model-agnostic approach for analyzing multimodal representation dynamics.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

