- The paper demonstrates that VLLMs encode semantic features linearly, as evidenced by competitive ImageNet classifications using linear probes.
- It employs steering vectors with Contrastive Activation Addition to causally manipulate model outputs at early transformer layers.
- Sparse autoencoders reveal a hierarchical structure in multimodal features, highlighting both interpretability and limitations for adversarial use.
Line of Sight: On Linear Representations in VLLMs
Introduction
The paper "Line of Sight: On Linear Representations in VLLMs" explores how vision-LLMs (VLLMs), specifically LlaVA-Next, represent images in their hidden activations. The study focuses on the linear decodability of image concepts, specifically ImageNet classes, from the residual stream of transformer models. The paper utilizes various techniques, including linear probes, steering vectors, and Sparse Autoencoders (SAEs), to decrypt and manipulate these hidden representations.
Linear Probes and Their Efficacy
Linear probe techniques are a primary method explored to assess the presence of decodable features in the residual streams of VLLMs. To determine if the ImageNet class information is linearly encodable, linear classifiers trained on the mean embeddings of image tokens at different layers are applied.
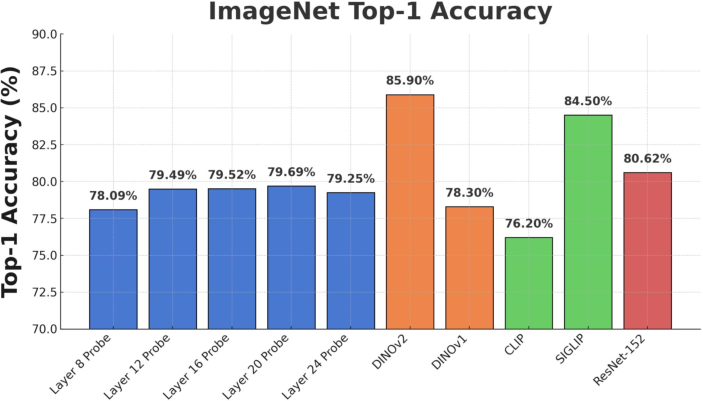
Figure 1: ImageNet Accuracy. We benchmark linear probes trained on mean embeddings across image tokens on ImageNet Classification.
The performance of these probes is found to be competitive with state-of-the-art self-supervised learning (SSL) techniques, suggesting that a significant portion of semantic information is indeed encoded linearly.
Steering Vectors: Causal Manipulation of Model Representations
Steering vectors emerge as a pivotal method for causally testing the influence of linearly encodable features within model representations. By using Contrastive Activation Addition (CAA), the paper investigates model behavior manipulation. Steering vectors are employed to test the causal effect of such linear decodings on model outputs.
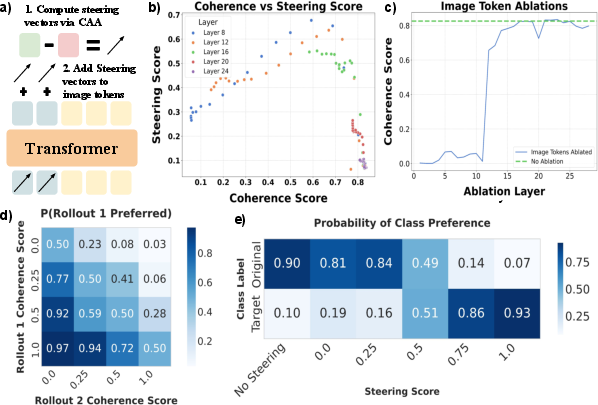
Figure 2: Steering Vector Interventions. Overview and evaluation of steering vector effects.
The study reinforces that steering at earlier layers is most fruitful, indicating an "information transfer" point where image semantics significantly influence text tokens. This highlights the potential for targeted interventions to dynamically control model outputs.
Sparse Autoencoders: Expanding Multimodal Feature Interpretability
The paper also explores the use of Sparse Autoencoders (SAEs) to extend the exploration of linear feature spaces beyond simple probing. SAEs provide a scalable method for discovering interpretable features within a model's residual streams.
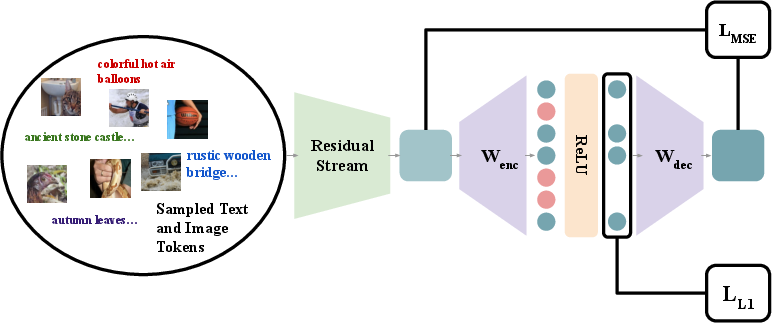
Figure 3: Sparse Autoencoder Training and Evaluation. Training overview and loss recovery measures.
The deployment of SAEs in VLLMs unveils a hierarchy of information across different layers, confirming that while individual neurons are informative, they are less structured than SAE features. This approach underscores SAE's effectiveness in decoding complex feature sets like those in ImageNet.
Adversarial Implications and Limitations
Although the linear representations offer significant insights and manipulative control, the paper acknowledges the inherent limitations in their deployment for adversarial attacks. The linear features provide a comparatively brittle basis for such applications, indicating areas for further exploration and refinement.
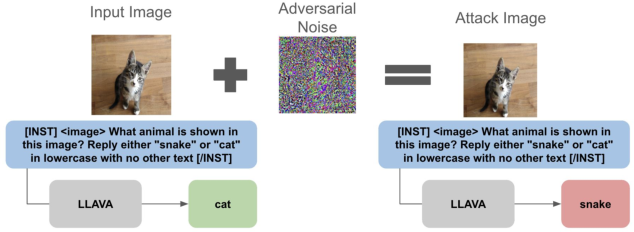
Figure 4: Analysis of noise robustness in adversarial settings.
Conclusion
The research conducted in "Line of Sight: On Linear Representations in VLLMs" contributes valuable insights into the role and potential of linear feature representations in vision-LLMs. Through robust methodologies like linear probes, steering vectors, and sparse autoencoders, the study navigates the hidden intricacies of multimodal models, revealing both the promise and limitations of current frameworks. Future work should aim to deepen the understanding of information conversion from image to text in VLLMs, potentially revolutionizing how such models are trained and deployed in real-world scenarios.