Intern-S1: A Scientific Multimodal Foundation Model
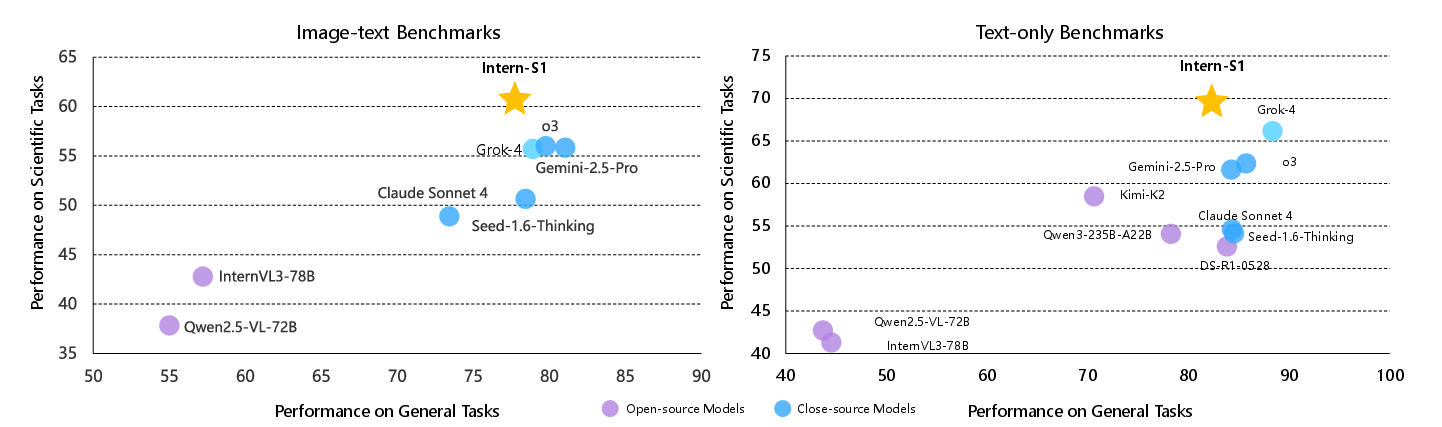
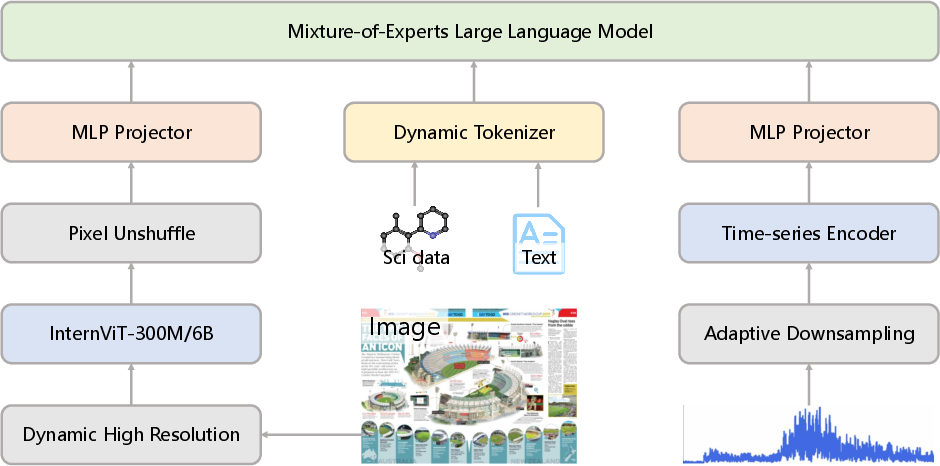
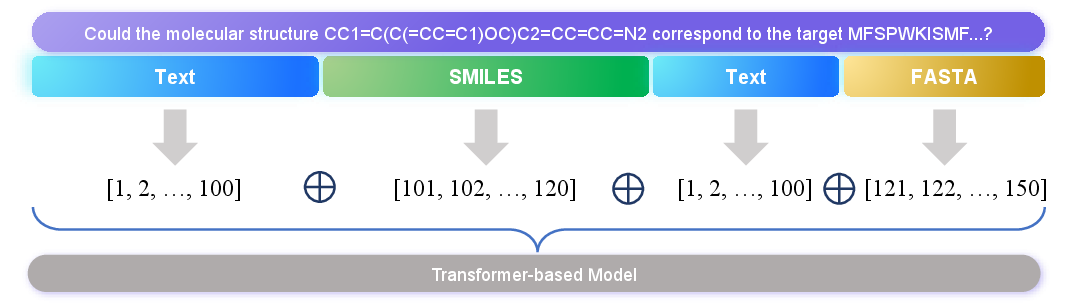
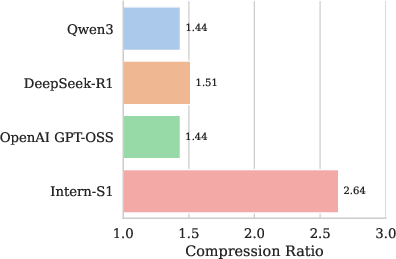
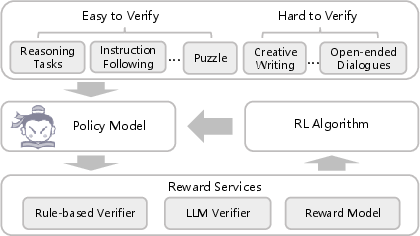
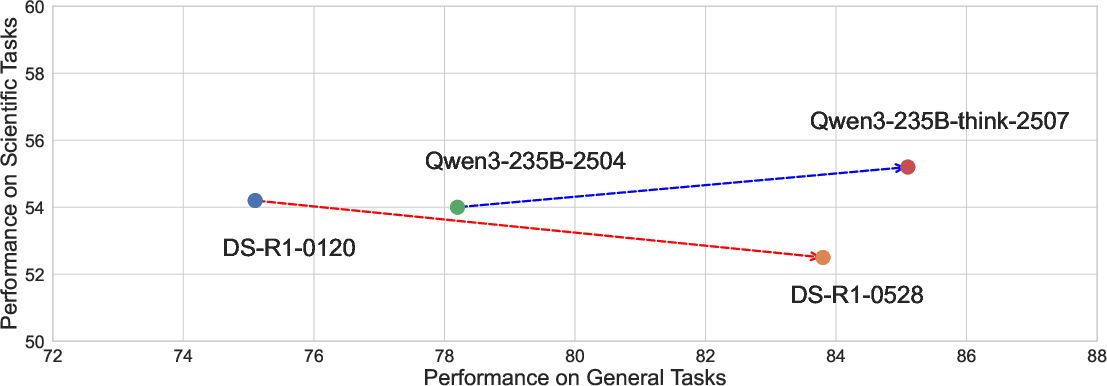
Abstract: In recent years, a plethora of open-source foundation models have emerged, achieving remarkable progress in some widely attended fields, with performance being quite close to that of closed-source models. However, in high-value but more challenging scientific professional fields, either the fields still rely on expert models, or the progress of general foundation models lags significantly compared to those in popular areas, far from sufficient for transforming scientific research and leaving substantial gap between open-source models and closed-source models in these scientific domains. To mitigate this gap and explore a step further toward AGI, we introduce Intern-S1, a specialized generalist equipped with general understanding and reasoning capabilities with expertise to analyze multiple science modal data. Intern-S1 is a multimodal Mixture-of-Experts (MoE) model with 28 billion activated parameters and 241 billion total parameters, continually pre-trained on 5T tokens, including over 2.5T tokens from scientific domains. In the post-training stage, Intern-S1 undergoes offline and then online reinforcement learning (RL) in InternBootCamp, where we propose Mixture-of-Rewards (MoR) to synergize the RL training on more than 1000 tasks simultaneously. Through integrated innovations in algorithms, data, and training systems, Intern-S1 achieved top-tier performance in online RL training. On comprehensive evaluation benchmarks, Intern-S1 demonstrates competitive performance on general reasoning tasks among open-source models and significantly outperforms open-source models in scientific domains, surpassing closed-source state-of-the-art models in professional tasks, such as molecular synthesis planning, reaction condition prediction, predicting thermodynamic stabilities for crystals. Our models are available at https://huggingface.co/internlm/Intern-S1.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.