Humans Perceive Wrong Narratives from AI Reasoning Texts
Abstract: A new generation of AI models generates step-by-step reasoning text before producing an answer. This text appears to offer a human-readable window into their computation process, and is increasingly relied upon for transparency and interpretability. However, it is unclear whether human understanding of this text matches the model's actual computational process. In this paper, we investigate a necessary condition for correspondence: the ability of humans to identify which steps in a reasoning text causally influence later steps. We evaluated humans on this ability by composing questions based on counterfactual measurements and found a significant discrepancy: participant accuracy was only 29%, barely above chance (25%), and remained low (42%) even when evaluating the majority vote on questions with high agreement. Our results reveal a fundamental gap between how humans interpret reasoning texts and how models use it, challenging its utility as a simple interpretability tool. We argue that reasoning texts should be treated as an artifact to be investigated, not taken at face value, and that understanding the non-human ways these models use language is a critical research direction.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Humans Perceive Wrong Narratives from AI Reasoning Texts”
1. What is this paper about?
Some new AI systems write out their “thinking” step by step before giving an answer. People often read these steps and believe they show how the AI actually figured things out. This paper asks a big question: do humans really understand these “reasoning texts” the way the AI actually uses them?
The short answer the paper finds: not really. People often get the story wrong.
2. What questions did the researchers ask?
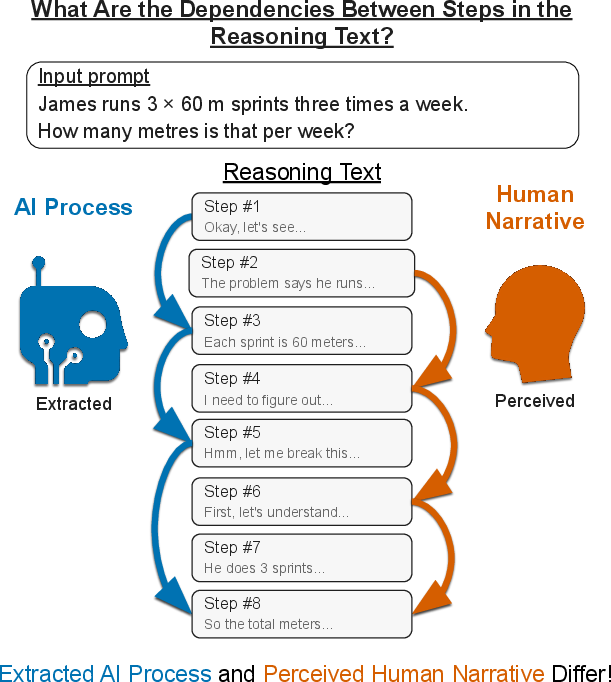
They focused on one important, easy-to-check piece of understanding: can people tell which earlier sentence in the AI’s reasoning actually caused a later sentence to be written?
In other words, given a target sentence in the AI’s step-by-step text, can you pick the earlier sentence that truly influenced it? If people can’t even do that, it’s a warning sign that the “reasoning text” isn’t a clear window into the AI’s real process.
3. How did they study it?
Think of the AI’s reasoning text like a chain of dominoes—one sentence after another. To test what really matters:
- They took AI-generated reasoning for simple math word problems (things like totaling distances or costs).
- They split the reasoning into sentences.
- For a chosen target sentence, they tested each earlier sentence one by one by “removing” it and asking the AI to regenerate just the target sentence.
- If removing sentence X makes the target sentence change in meaning, then sentence X truly caused (influenced) the target sentence.
- If the target doesn’t change, then sentence X didn’t matter for that target.
- They did this carefully so the only difference was the missing sentence (no randomness).
- They used another AI to double-check whether the original and new target sentences really said the same thing or not.
Then they made a human quiz:
- People saw the problem and the AI’s reasoning up to a target sentence.
- They saw four earlier sentences and had to pick which single one actually caused the target sentence.
- There was always exactly one correct choice.
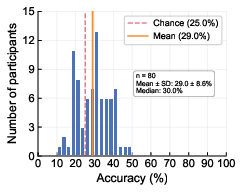
- 80 adult participants took 50 such questions each.
This is like asking: which domino, if removed, would change how a later domino falls?
4. What did they find, and why does it matter?
Key results:
- Individuals did poorly: average accuracy was about 29%, barely above guessing (25%).
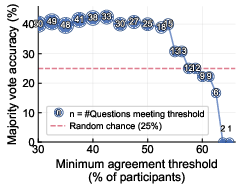
- Even when many people agreed on the same answer (a strong “shared story”), they were still wrong a lot: only about 40% correct.
- Background and experience didn’t help: people with STEM degrees, people who use AI often, or people who took more time didn’t do better.
- The gap showed up across different AI models. People did a bit better on one model’s texts than the other, but overall performance was still low.
Why this matters:
- It shows a big mismatch between the story humans think the AI is following and the way the AI actually uses its own text.
- That means we shouldn’t treat AI “reasoning text” as a trustworthy explanation of how the AI got its answer just by reading it like a human explanation.
5. What does this mean for the future?
- Don’t take AI “thinking” text at face value. It may look like an explanation, but humans can easily misread it.
- We need better tools and tests to probe what parts of the AI’s text actually affect later steps and the final answer.
- AIs might “use” language differently from humans. They can write fluent, logical-looking text, but the hidden cause-and-effect inside their process doesn’t match human expectations.
- Building safe, trustworthy AI will require new ways to study and interpret these systems, not just reading their step-by-step text as if it were a human diary.
Collections
Sign up for free to add this paper to one or more collections.

