How Likely Do LLMs with CoT Mimic Human Reasoning?
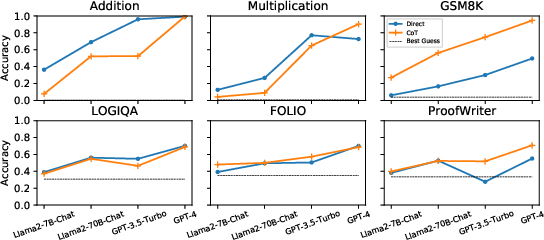
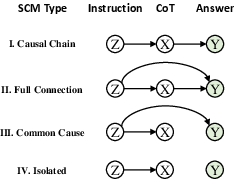
Abstract: Chain-of-thought emerges as a promising technique for eliciting reasoning capabilities from LLMs. However, it does not always improve task performance or accurately represent reasoning processes, leaving unresolved questions about its usage. In this paper, we diagnose the underlying mechanism by comparing the reasoning process of LLMs with humans, using causal analysis to understand the relationships between the problem instruction, reasoning, and the answer in LLMs. Our empirical study reveals that LLMs often deviate from the ideal causal chain, resulting in spurious correlations and potential consistency errors (inconsistent reasoning and answers). We also examine various factors influencing the causal structure, finding that in-context learning with examples strengthens it, while post-training techniques like supervised fine-tuning and reinforcement learning on human feedback weaken it. To our surprise, the causal structure cannot be strengthened by enlarging the model size only, urging research on new techniques. We hope that this preliminary study will shed light on understanding and improving the reasoning process in LLM.
- Joshua Angrist and Guido Imbens. 1995. Identification and estimation of local average treatment effects.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- A survey of chain of thought reasoning: Advances, frontiers and future. arXiv preprint arXiv:2309.15402.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Plug and play language models: A simple approach to controlled text generation. arXiv preprint arXiv:1912.02164.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335.
- Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Transactions of the Association for Computational Linguistics, 10:1138–1158.
- Giorgio Franceschelli and Mirco Musolesi. 2023. On the creativity of large language models. arXiv preprint arXiv:2304.00008.
- Causal reasoning through intervention. Causal learning: Psychology, philosophy, and computation, pages 86–100.
- Folio: Natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840.
- Mary Hegarty. 2004. Mechanical reasoning by mental simulation. Trends in cognitive sciences, 8(6):280–285.
- David R Heise. 1975. Causal analysis. John Wiley & Sons.
- Mathprompter: Mathematical reasoning using large language models. arXiv preprint arXiv:2303.05398.
- Guido W Imbens and Donald B Rubin. 2015. Causal inference in statistics, social, and biomedical sciences. Cambridge University Press.
- Mistral 7b.
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Efficient memory management for large language model serving with pagedattention.
- Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702.
- Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35:3843–3857.
- Pretrained language models for text generation: A survey. arXiv preprint arXiv:2201.05273.
- Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing.
- Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv preprint arXiv:2304.03439.
- Emily McMilin. 2022. Selection bias induced spurious correlations in large language models. arXiv preprint arXiv:2207.08982.
- Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153–157.
- Representation learning via invariant causal mechanisms. In International Conference on Learning Representations.
- Collaborative storytelling with large-scale neural language models. In Proceedings of the 13th ACM SIGGRAPH Conference on Motion, Interaction and Games, pages 1–10.
- OpenAI. 2022. ChatGPT. https://chat.openai.com/.
- OpenAI. 2023. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774.
- Training language models to follow instructions with human feedback.
- Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. arXiv preprint arXiv:2305.12295.
- Judea Pearl. 2009. Causality. Cambridge university press.
- Elements of causal inference: foundations and learning algorithms. The MIT Press.
- Limitations of language models in arithmetic and symbolic induction. arXiv preprint arXiv:2208.05051.
- Improving language understanding by generative pre-training.
- Donald B Rubin. 1974. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of educational Psychology, 66(5):688.
- John Schulman. 2023. Reinforcement learning from human feedback: Progress and challenges. In Berkley Electrical Engineering and Computer Sciences. URL: https://eecs. berkeley. edu/research/colloquium/230419 [accessed 2023-11-15].
- Do massively pretrained language models make better storytellers? arXiv preprint arXiv:1909.10705.
- Herbert A Simon. 1954. Spurious correlation: A causal interpretation. Journal of the American statistical Association, 49(267):467–479.
- Steven A Sloman and David Lagnado. 2015. Causality in thought. Annual review of psychology, 66:223–247.
- Musr: Testing the limits of chain-of-thought with multistep soft reasoning. arXiv preprint arXiv:2310.16049.
- Proofwriter: Generating implications, proofs, and abductive statements over natural language. arXiv preprint arXiv:2012.13048.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944.
- Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. arXiv preprint arXiv:2305.04388.
- Attention is all you need. Advances in neural information processing systems, 30.
- Counterfactual invariance to spurious correlations: Why and how to pass stress tests. arXiv preprint arXiv:2106.00545.
- Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Finetuned language models are zero-shot learners.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Polyjuice: Generating counterfactuals for explaining, evaluating, and improving models. In Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021).
- Are large language models really good logical reasoners? a comprehensive evaluation from deductive, inductive and abductive views. arXiv preprint arXiv:2306.09841.
- Exploring the efficacy of automatically generated counterfactuals for sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 306–316, Online. Association for Computational Linguistics.
- Alignment for honesty. arXiv preprint arXiv:2312.07000.
- Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.
- Beyond chain-of-thought, effective graph-of-thought reasoning in large language models. arXiv preprint arXiv:2305.16582.
- Causal parrots: Large language models may talk causality but are not causal. Transactions on Machine Learning Research.
- A survey of controllable text generation using transformer-based pre-trained language models. ACM Computing Surveys, 56(3):1–37.
- On the paradox of learning to reason from data. arXiv preprint arXiv:2205.11502.
- Ruiyi Zhang and Tong Yu. 2023. Understanding demonstration-based learning from a causal perspective. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1465–1475.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.