- The paper demonstrates the integration of Chain-of-Thought guided information gain into reinforcement learning to enhance legal reasoning capabilities in LLMs.
- It leverages latent reasoning distillation and differential Q-value analysis to ensure structured and legally specific reasoning outputs.
- Experimental results on datasets like CAIL2018 show a 10% performance boost with improved interpretability and stability on complex legal tasks.
Enhancing Legal Reasoning in LLMs with LegalΔ
Introduction
The paper introduces LegalΔ, a reinforcement learning framework designed to bolster the legal reasoning capabilities of LLMs. Specifically, the framework integrates a novel mechanism called Chain-of-Thought guided Information Gain into the Reinforcement Learning with Verifiable Rewards (RLVR) paradigm. This integration encourages LLMs to generate not only answers but also structured, interpretable reasoning processes that are crucial for handling complex legal scenarios.
Methodology
LegalΔ incorporates a dual-mode input setup—comprising direct answer and reasoning-augmented modes—to maximize information gain. This setup encourages the model to explore diverse reasoning trajectories, fostering the extraction of meaningful reasoning patterns. The core methodology involves two stages:
- Latent Reasoning Distillation: Utilizing a large reasoning model, DeepSeek-R1, the framework distills latent reasoning capabilities into the LLMs.
- Differential Comparison and Multidimensional Reward: The system refines reasoning quality through differential comparisons combined with rewards assessing structural coherence and legal-domain specificity.

Figure 1: Illustration of LegalDelta. We present how chain-of-thought guided information gain works in RLVR.
The reward mechanism is a critical aspect of LegalΔ. It leverages the analogy between model logits and Q-values in reinforcement learning to quantify information gain. This involves evaluating pointwise mutual information and global confidence shifts through:
- Logit Analysis: Monitoring the model's confidence through average logit values during Chain-of-Thought prompting.
- Differential Q-value Analysis: Comparing the differential gain in Q-values from reasoning prompts to measure semantic shifts contributing to reasoning quality.
Experimental Setup
The study evaluates LegalΔ across a range of legal tasks, demonstrating notable improvements over baseline models in both accuracy and interpretability. These tasks, drawn from datasets like CAIL2018 and JEC_QA, include legal article prediction, criminal charge prediction, and case analysis, among others. The framework shows a 10% performance boost across various LLM scales without the need for labeled preference data.
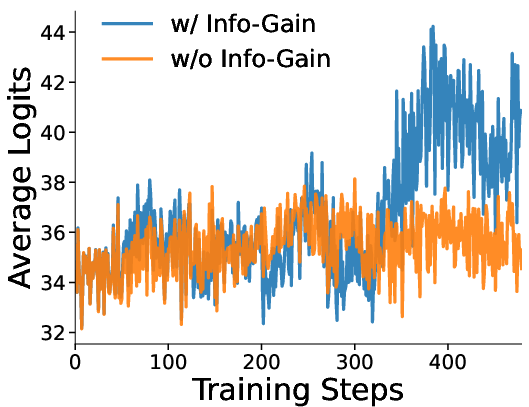
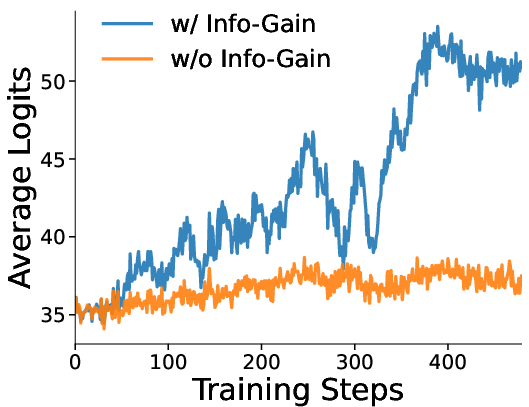
Figure 2: Logit Variations Induced by Information Gain Module During Training Process.
Results and Discussion
LegalΔ consistently outperforms baseline models, exhibiting strong generalization to out-of-domain tasks as well. The information gain module, specifically, contributes significantly to confidence improvements, training efficiency, and stability. The RL component, which utilizes Group Relative Policy Optimization (GRPO), proves effective in distinguishing high-quality reasoning.
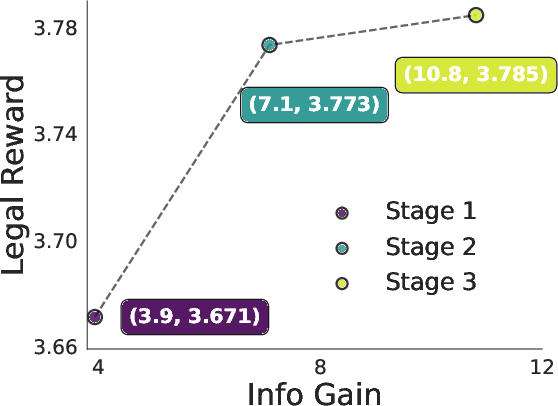
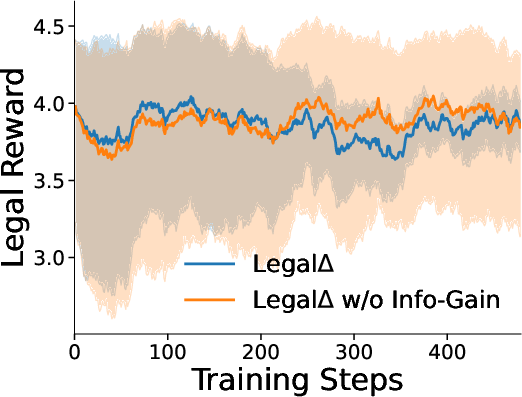
Figure 3: Analysis of Information Gain-Enhanced Reward Modeling Process.
Conclusion
LegalΔ establishes a robust framework for enhancing legal reasoning in LLMs through a sophisticated integration of reinforcement learning and information gain techniques. By fostering an environment where models explore and develop robust reasoning strategies, LegalΔ significantly elevates the capabilities of LLMs in the legal domain. Future research may expand on these techniques to further explore reinforcement learning's role in other domains requiring complex, multi-step reasoning.

