- The paper systematically isolates the effects of normalization, clipping, loss aggregation, and filtering, revealing a minimalist Lite PPO that outperforms complex RL pipelines.
- It demonstrates that combining group-level mean with batch-level standard deviation normalization and token-level loss aggregation stabilizes optimization across varying data difficulties.
- It provides detailed guidelines for practitioners by highlighting distinctions between base and aligned LLMs and advocating context-sensitive technique selection.
Disentangling Reinforcement Learning Techniques for LLM Reasoning: Mechanistic Insights and Practical Guidelines
Introduction
The application of reinforcement learning (RL) to LLM reasoning tasks has led to a proliferation of optimization techniques, each with distinct theoretical motivations and empirical claims. However, the lack of standardized guidelines and the prevalence of contradictory recommendations have created significant barriers to practical adoption. "Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning" (2508.08221) systematically investigates widely used RL techniques for LLM reasoning, providing a unified empirical and mechanistic analysis. The study isolates the effects of normalization, clipping, loss aggregation, and filtering strategies, and introduces a minimalist yet effective combination—Lite PPO—that outperforms more complex RL4LLM pipelines.
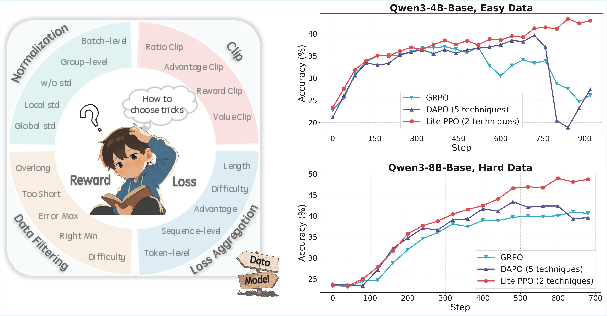
Figure 1: The proliferation of RL optimization techniques and the establishment of detailed application guidelines, culminating in the introduction of Lite PPO.
Experimental Framework and Baseline Analysis
The study employs the ROLL framework for reproducible RL optimization, using Qwen3-4B and Qwen3-8B models (both base and aligned variants) and open-source mathematical reasoning datasets of varying difficulty. The evaluation spans six math benchmarks, ensuring coverage of both short-form and long-tail reasoning.
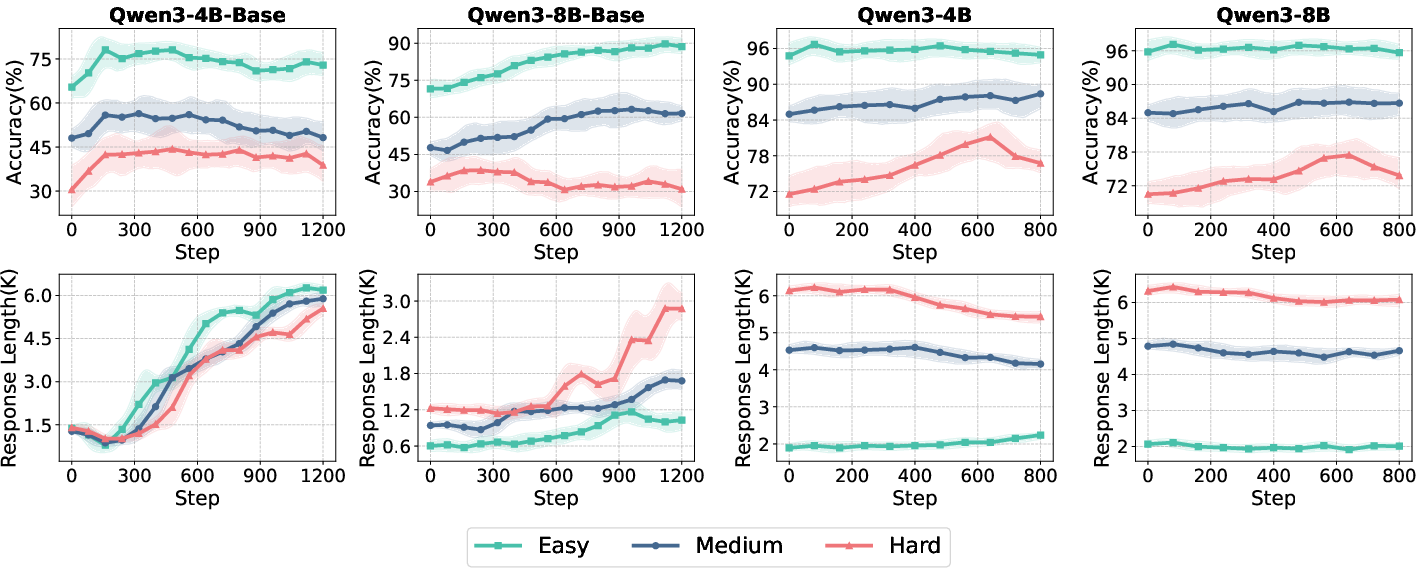
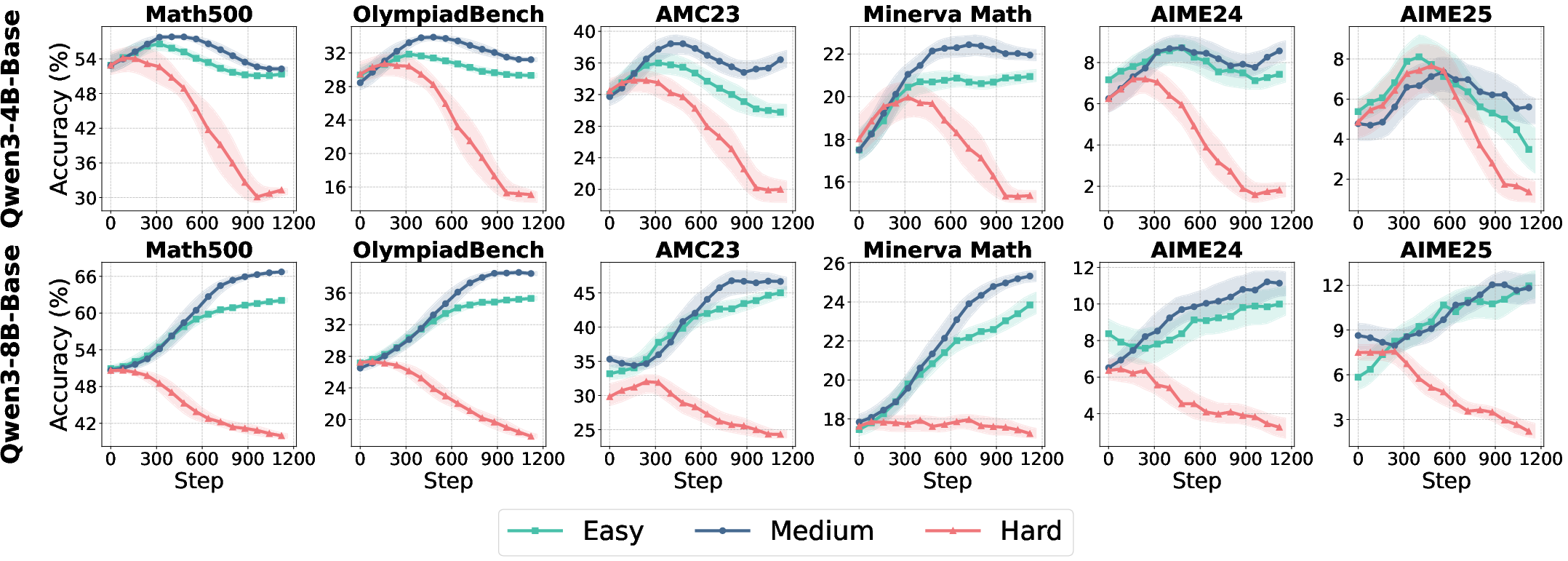
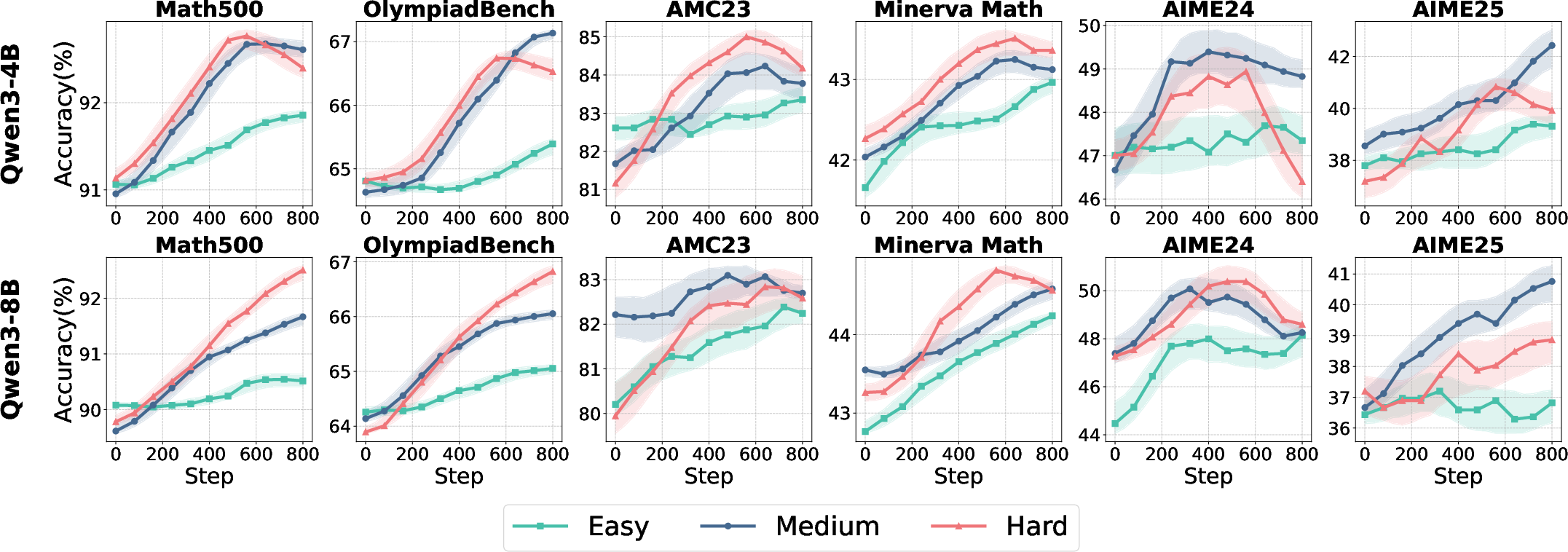
Figure 2: Test accuracy and response length dynamics for Qwen3 model variants across data difficulty and training iterations.
Key findings from baseline experiments include:
- Model performance and convergence trajectories are highly sensitive to data difficulty.
- Aligned models exhibit higher initial accuracy and longer responses but show limited further improvement from RL, with only ~2% accuracy gain.
- Base models benefit more substantially from RL optimization, highlighting the importance of initialization and alignment status in RL4LLM studies.
Mechanistic Dissection of RL Techniques
Advantage Normalization
Advantage normalization is critical for variance reduction and stable policy optimization. The study contrasts group-level normalization (per-prompt) with batch-level normalization (across the rollout batch), revealing strong dependencies on reward scale and data distribution.
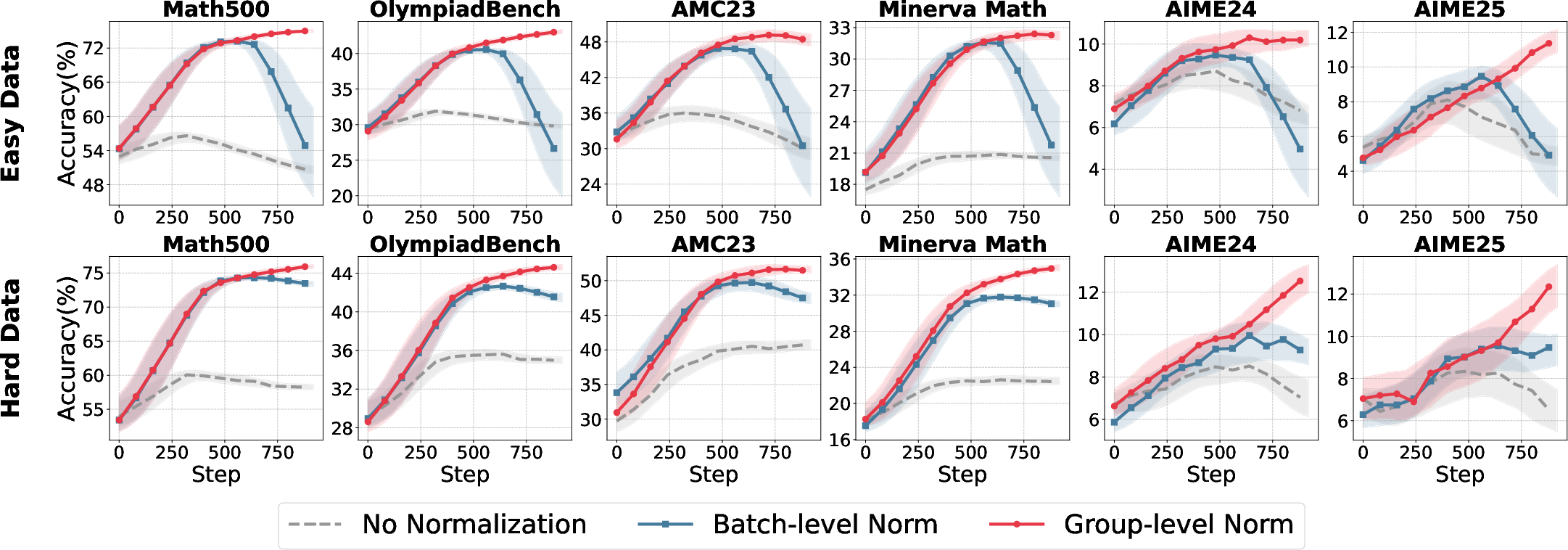
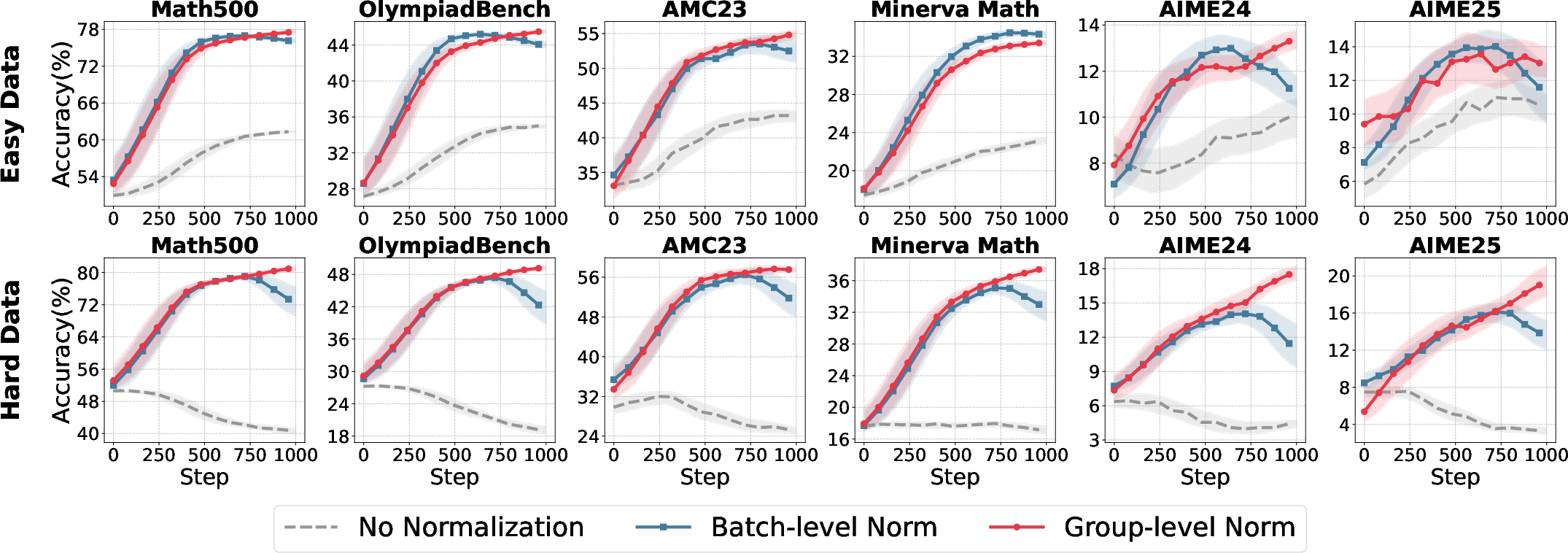
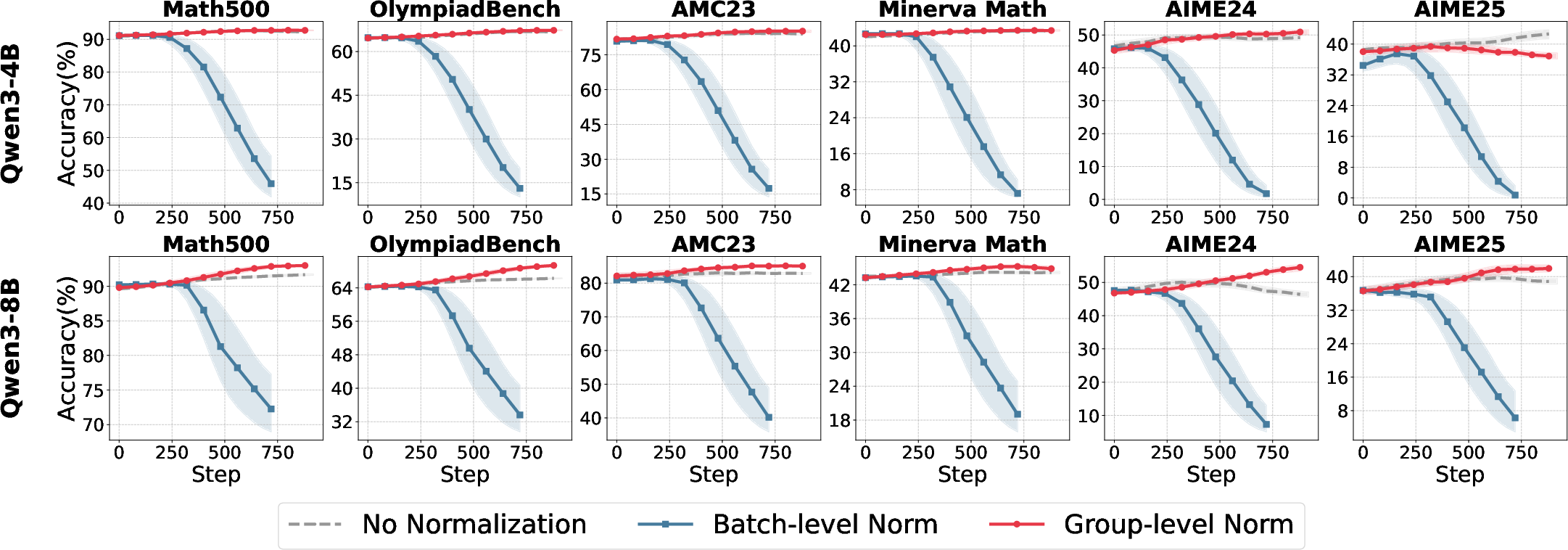
Figure 3: Comparative accuracy trajectories for normalization strategies across model sizes and data difficulty.
- Group-level normalization is robust across reward settings, especially with binary rewards (R∈{0,1}).
- Batch-level normalization is unstable under skewed reward distributions but regains efficacy with larger reward scales (R∈{−1,1}).
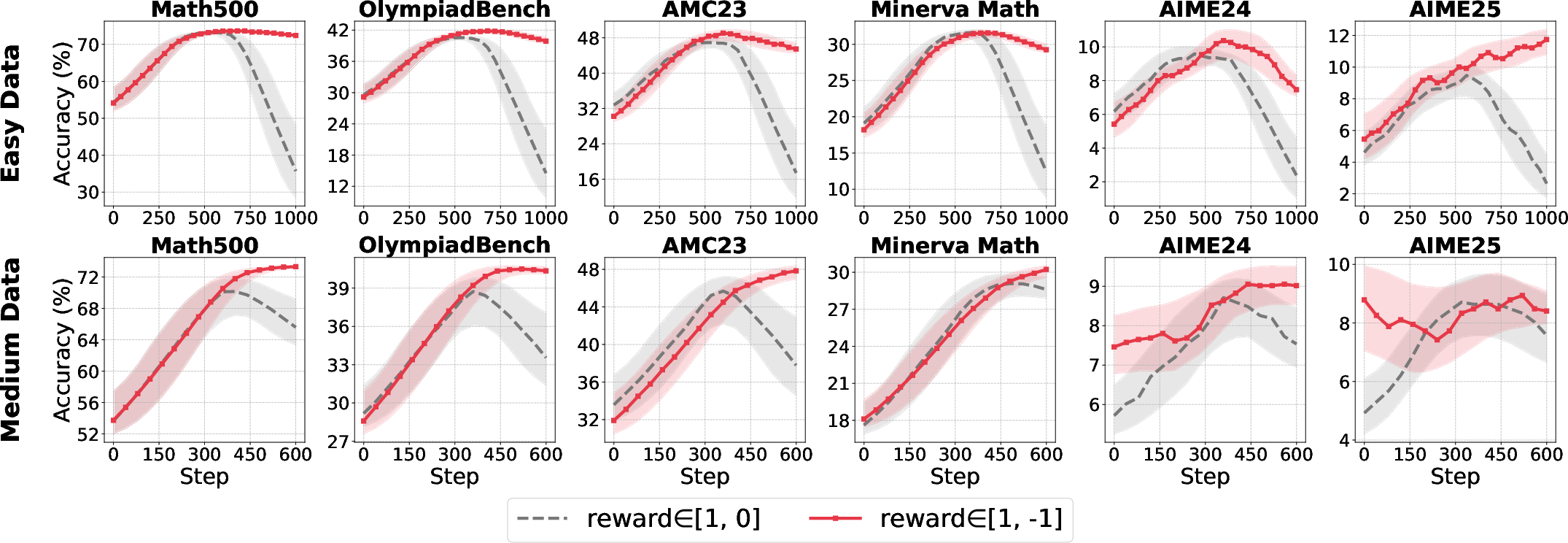
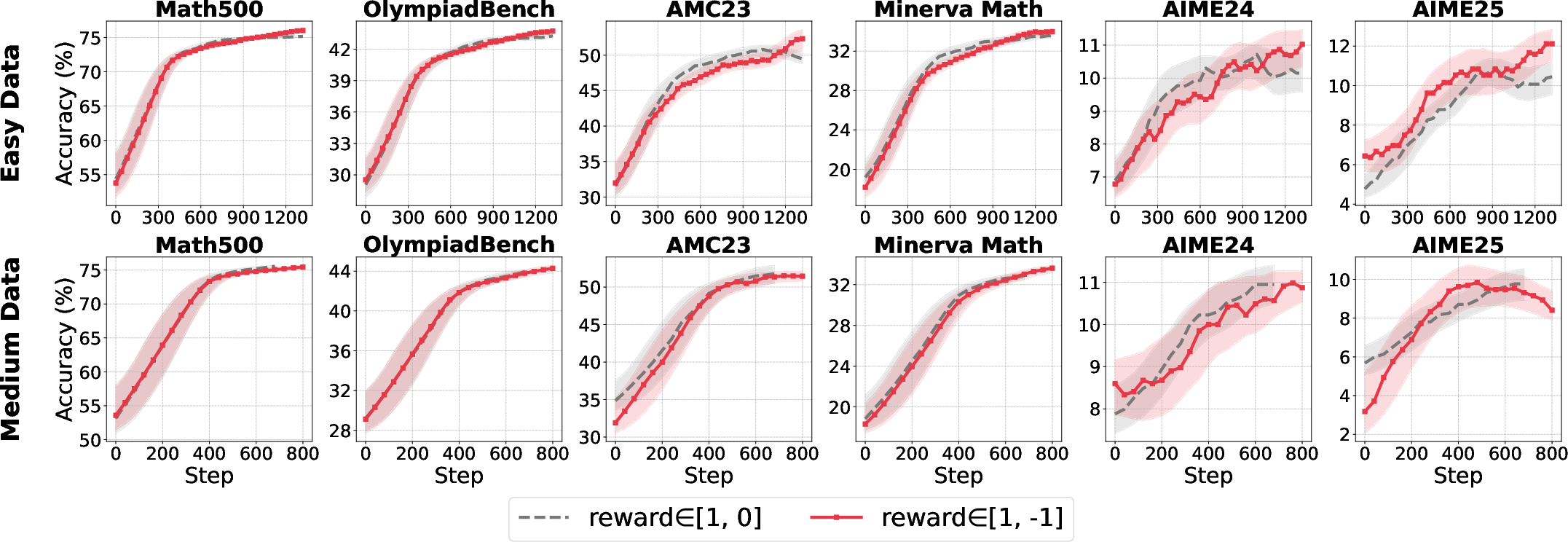
Figure 4: Sensitivity of normalization strategies to reward scale and data difficulty.
Ablation on the standard deviation term demonstrates that omitting it (i.e., mean-only normalization) stabilizes training when reward distributions are highly concentrated, preventing gradient explosion.
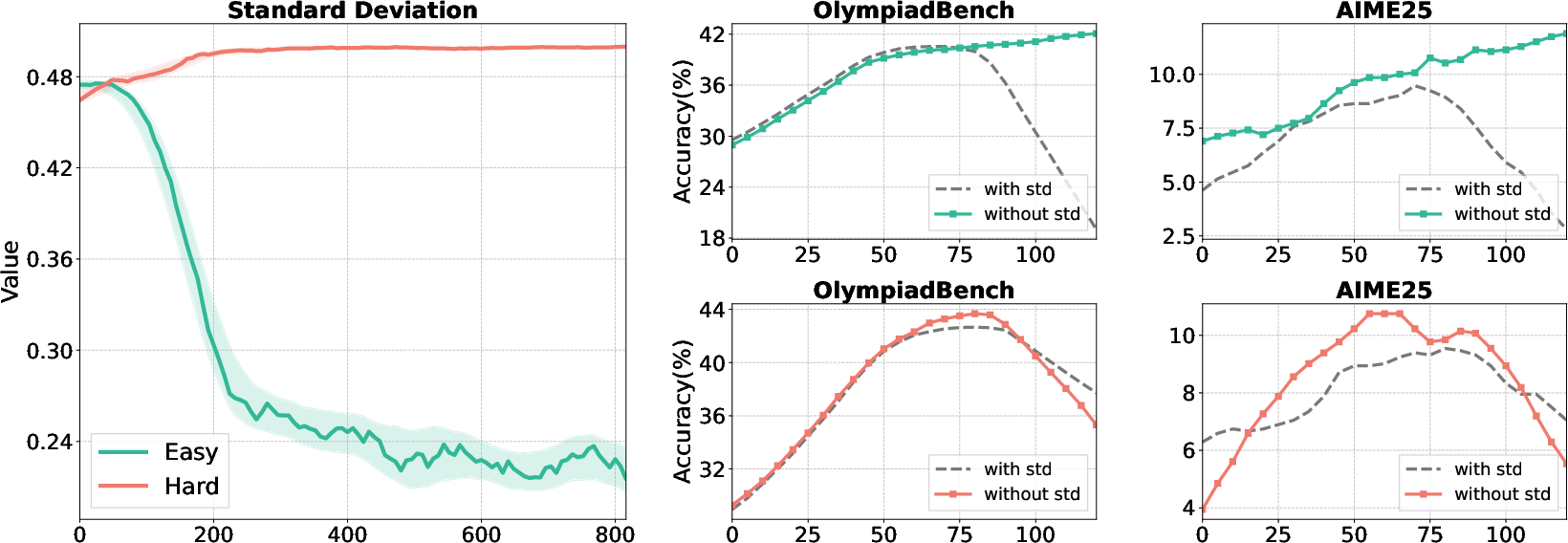
Figure 5: Standard deviation collapse and the impact of removing std in advantage normalization on easy vs. hard data.
A hybrid approach—using group-level mean and batch-level standard deviation—yields the most robust normalization, effectively shaping sparse rewards and preventing overfitting to homogeneous reward signals.
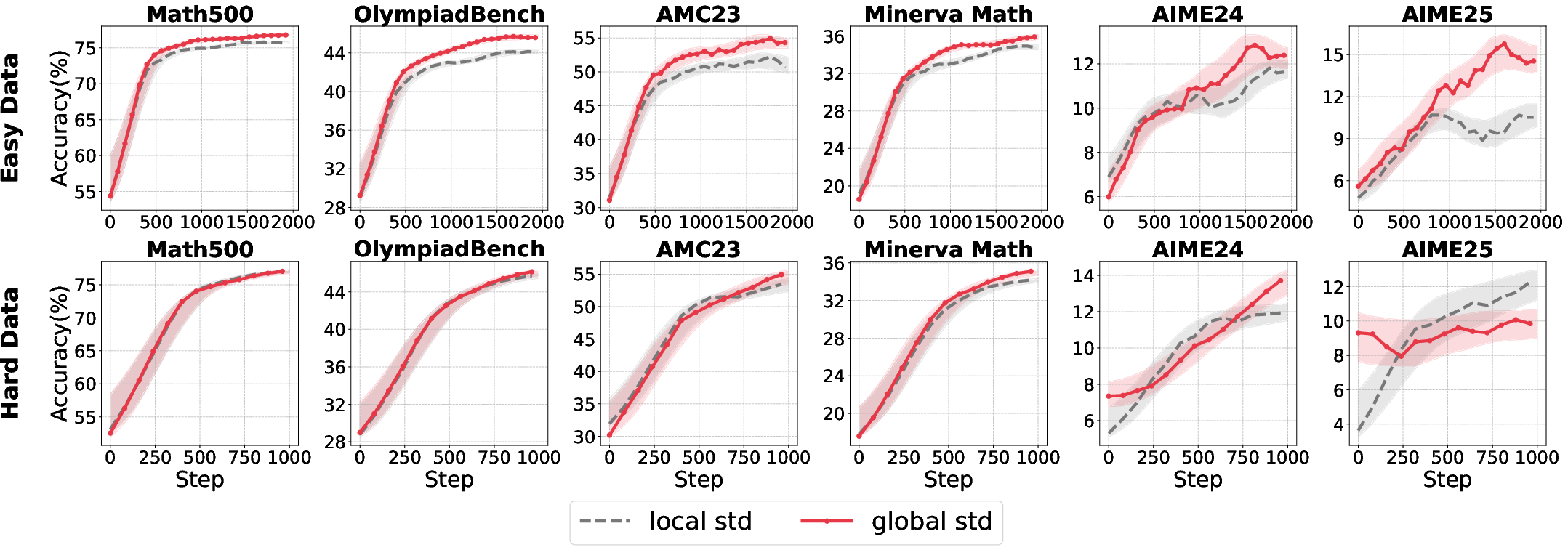
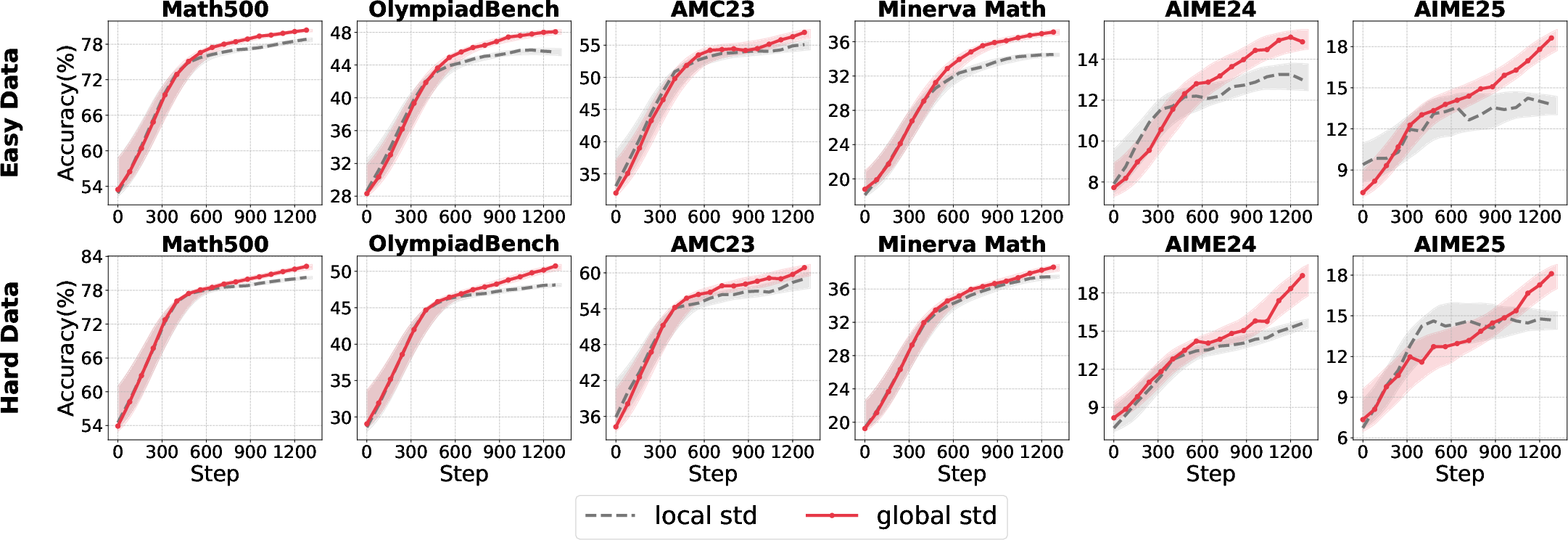
Figure 6: Accuracy comparison for different std calculation strategies across model sizes and data difficulties.
Clipping Strategies: Clip-Higher
The standard PPO clipping mechanism can induce entropy collapse, especially in aligned models, by suppressing low-probability tokens and reducing exploration. The Clip-Higher variant relaxes the upper bound, mitigating this effect.
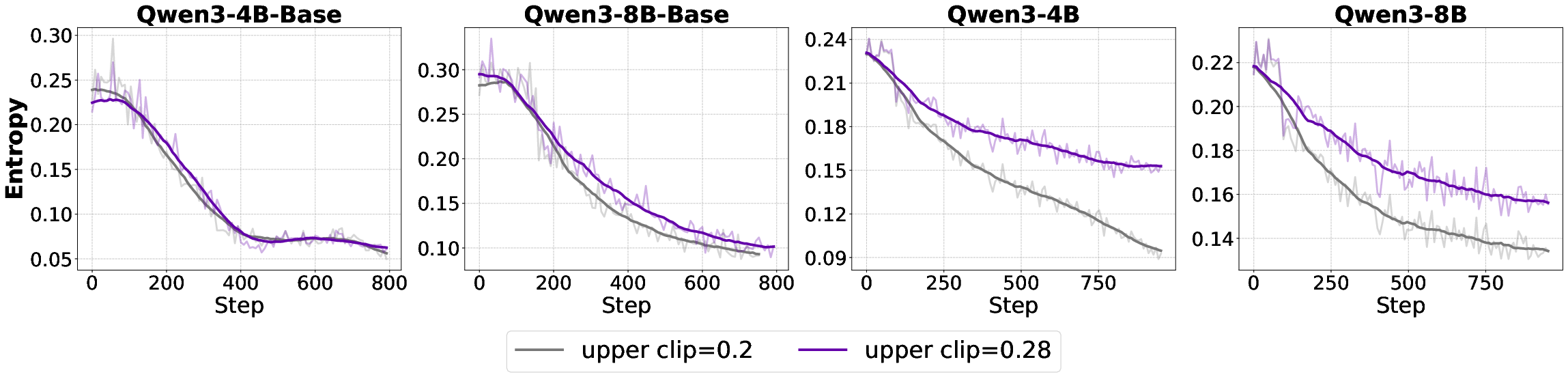
Figure 7: Entropy trajectories under different clip upper bounds, showing mitigation of entropy collapse in aligned models.
- For base models, increasing the clip upper bound has negligible or negative effects.
- For aligned models, higher clip upper bounds slow entropy collapse and improve accuracy, particularly on complex reasoning tasks.
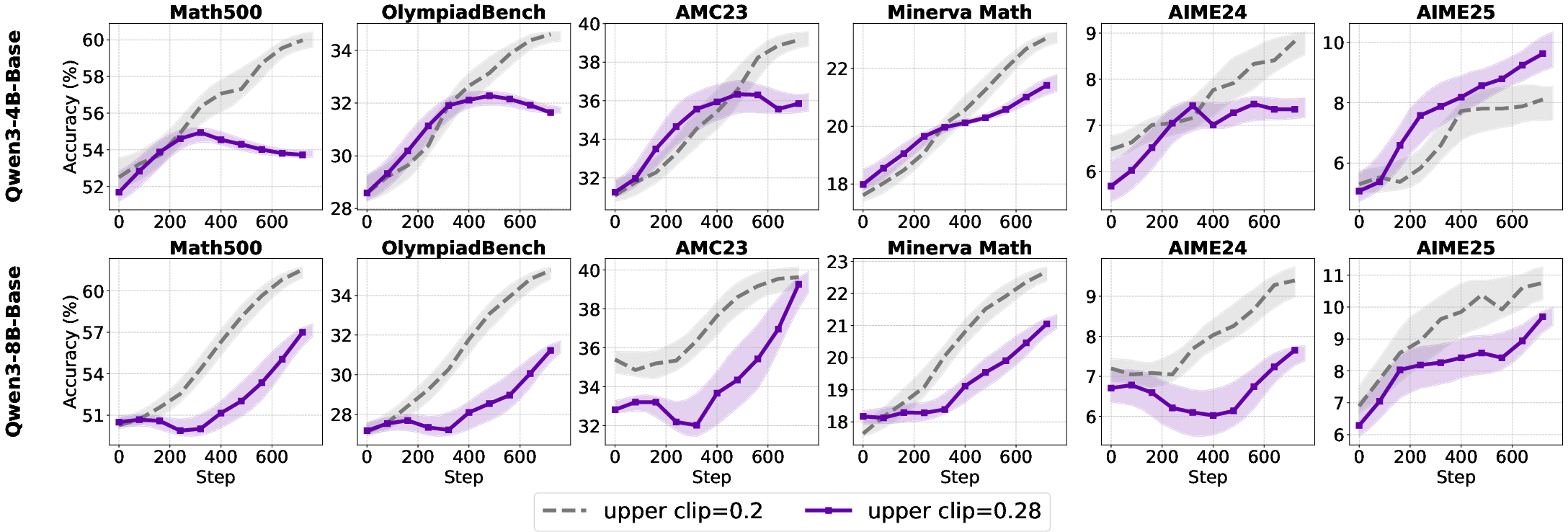
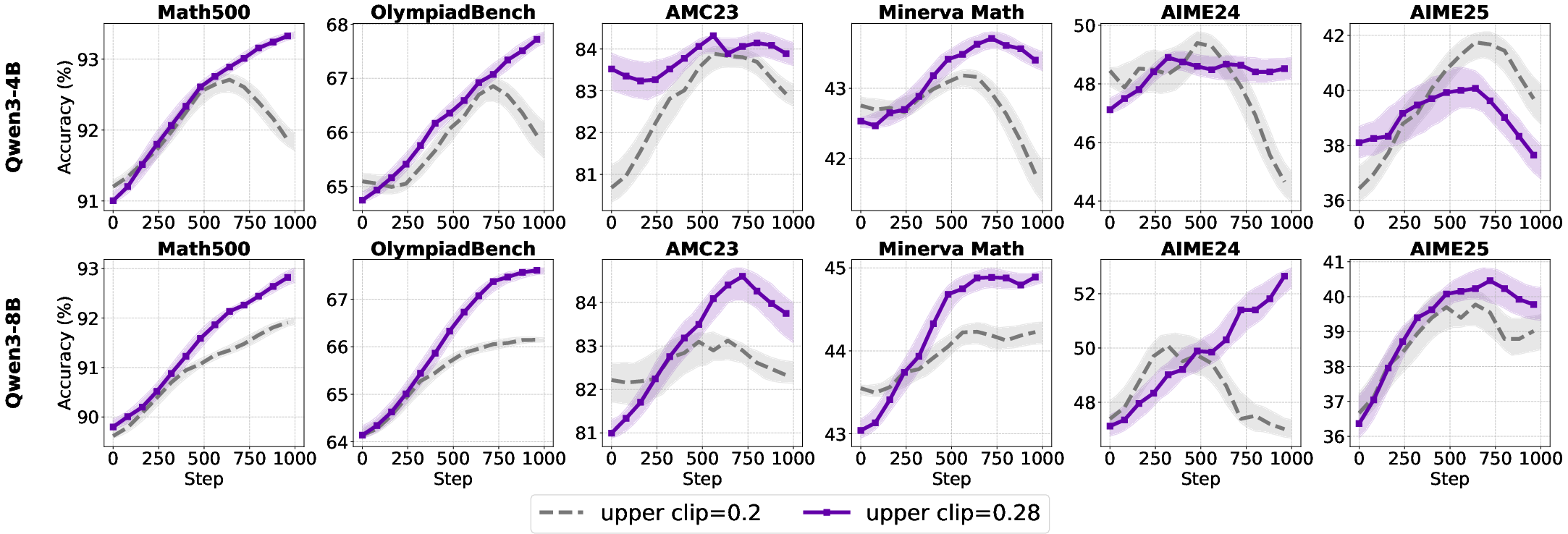
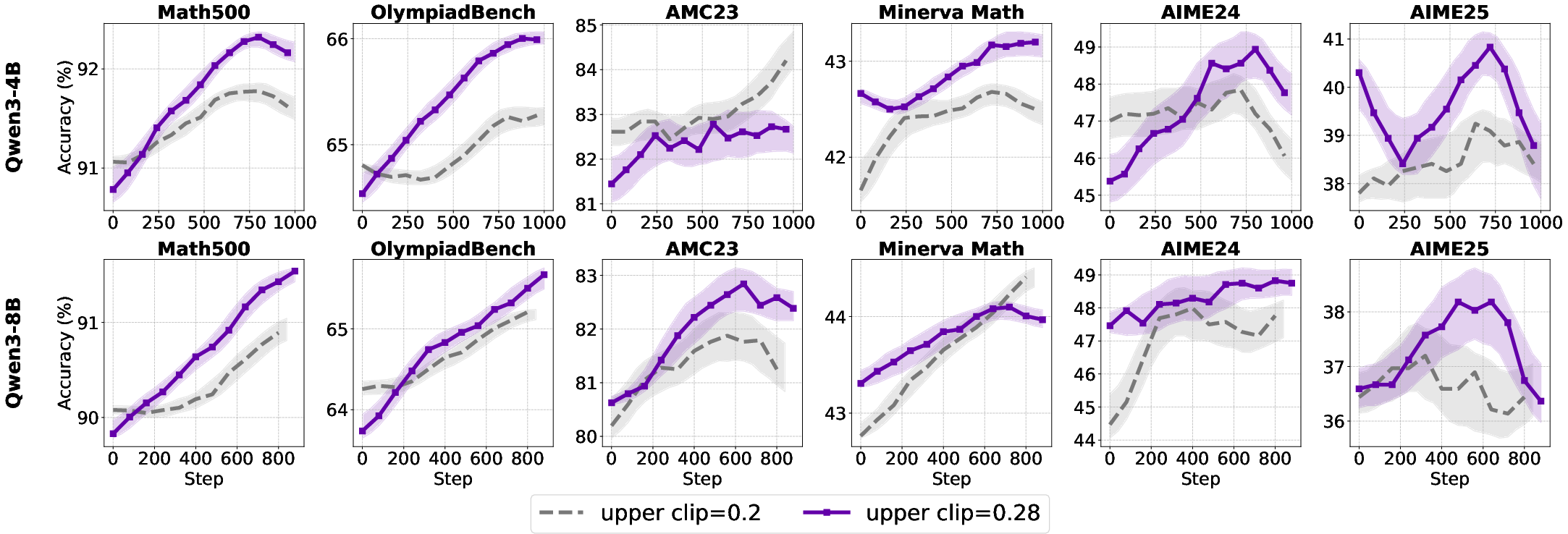
Figure 8: Test accuracy improvements in base and aligned models with higher clipping upper bounds.
Token-level analysis reveals that stricter clipping disproportionately suppresses discourse connectives, limiting the model's ability to generate diverse reasoning structures. Relaxing the upper bound shifts clipping to high-frequency function words, preserving structural stability while enabling more diverse reasoning.
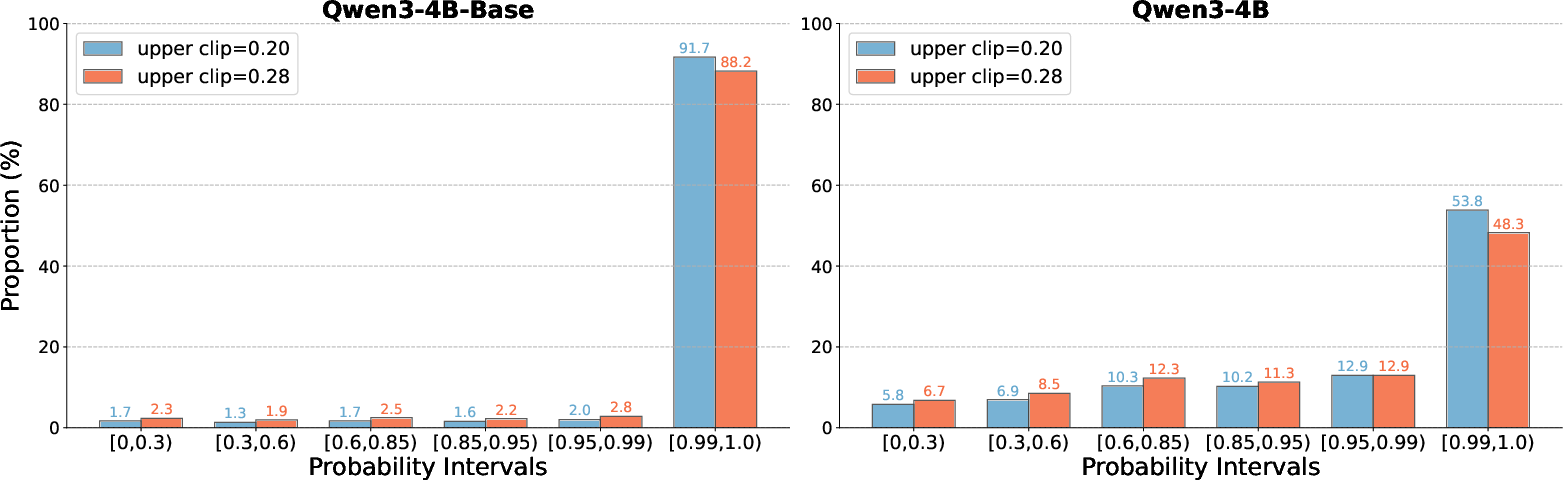
Figure 9: Token probability distributions under different clip upper bounds for base and aligned models.
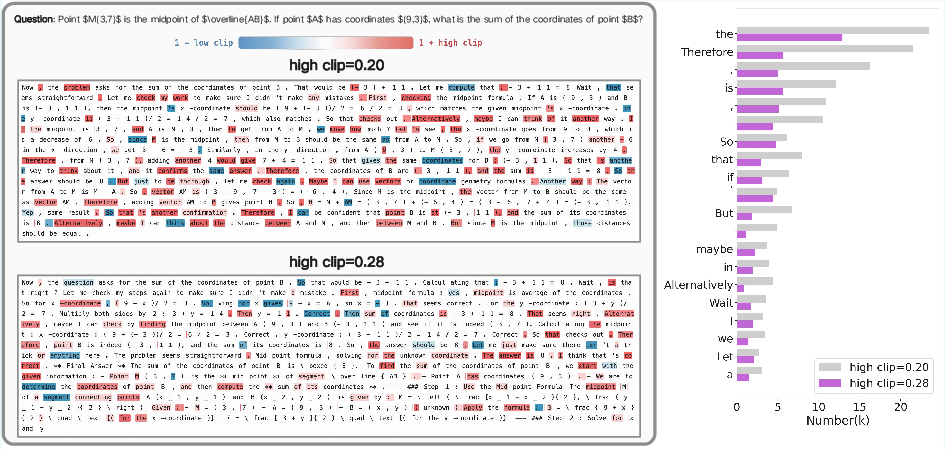
Figure 10: Case study of clipping effects on token selection and discourse structure.
A scaling law is observed for small models: performance improves monotonically with increased clip upper bound, peaking at 0.32. For larger models, the optimal upper bound is 0.28, with no further gains from higher values.
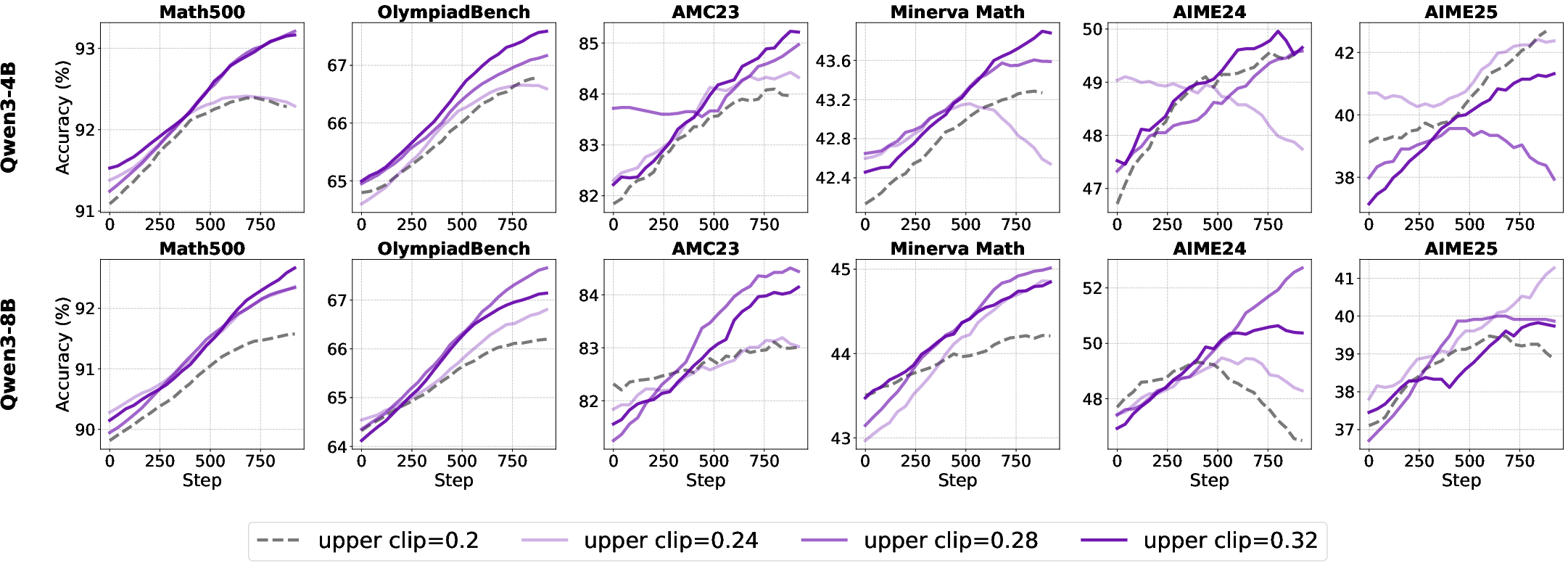
Figure 11: Test accuracy of aligned models under various clip upper bounds, illustrating the scaling law for small models.
Loss Aggregation Granularity
The aggregation strategy for the RL loss—sequence-level vs. token-level—directly affects optimization dynamics and length bias.
- Token-level aggregation ensures equal contribution from each token, improving convergence and robustness for base models, especially on hard datasets.
- Sequence-level aggregation is preferable for aligned models, preserving output structure and consistency.
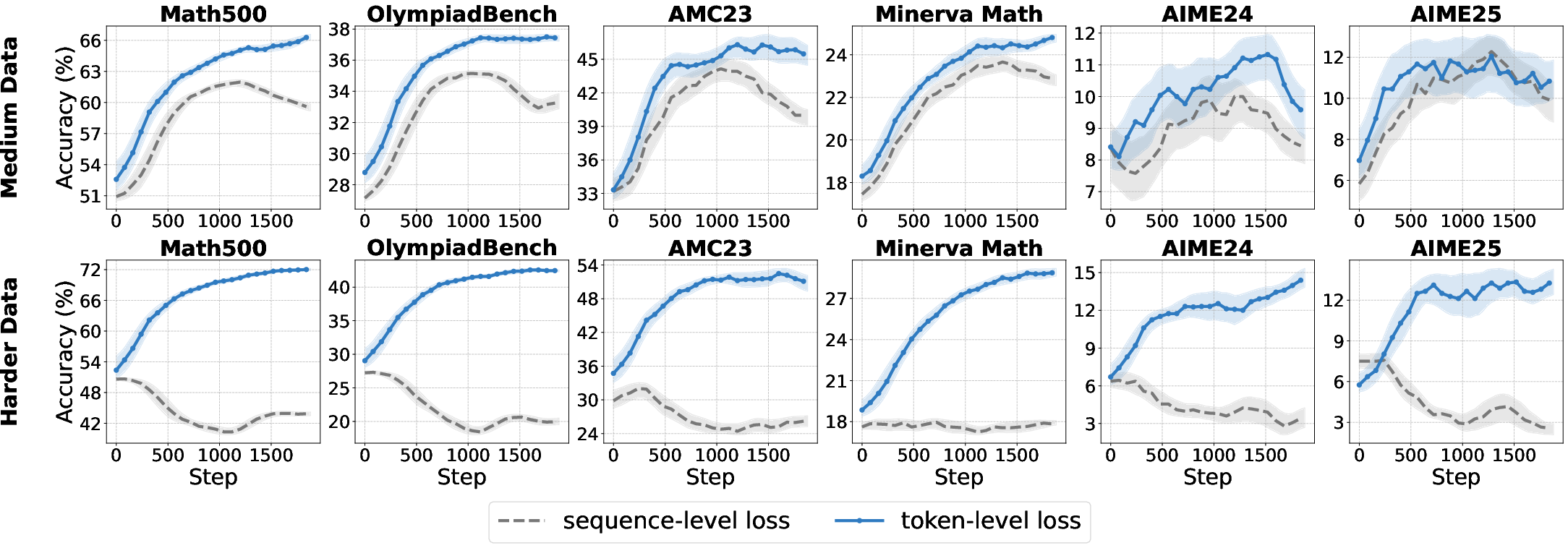
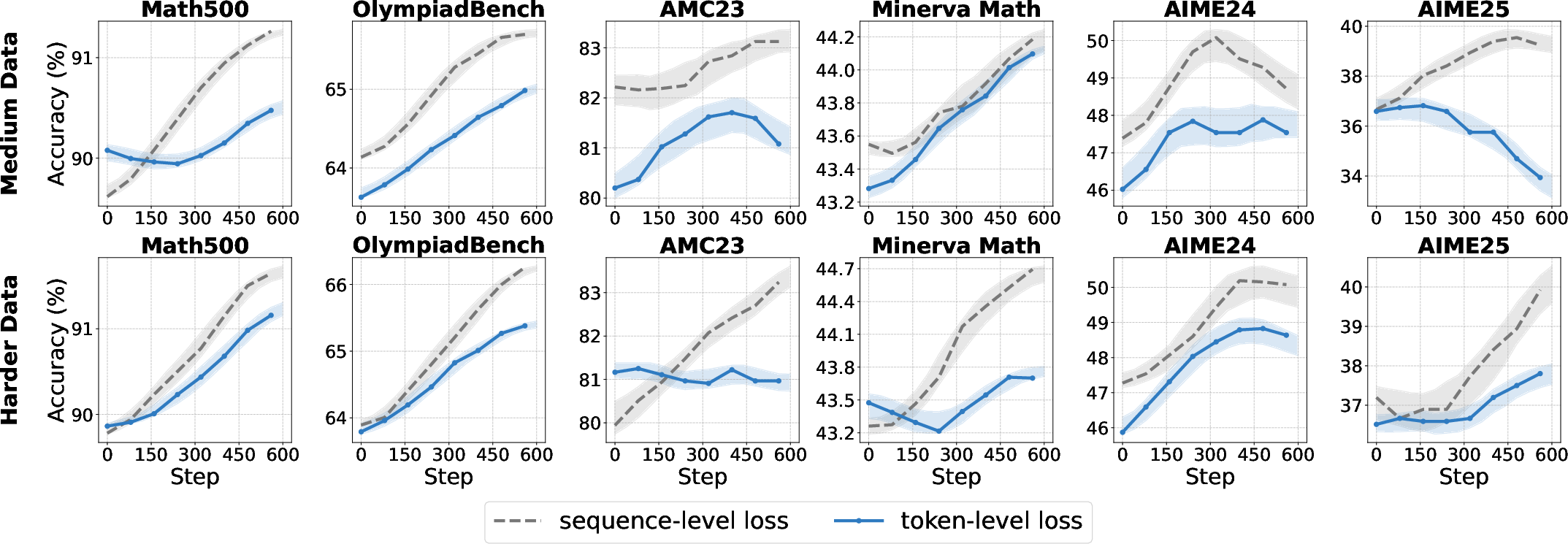
Figure 12: Comparative accuracy for sequence-level and token-level loss aggregation across model types and data difficulties.
Overlong Filtering
Overlong filtering masks the reward signal for excessively long responses, preventing penalization of truncated but otherwise correct reasoning chains.
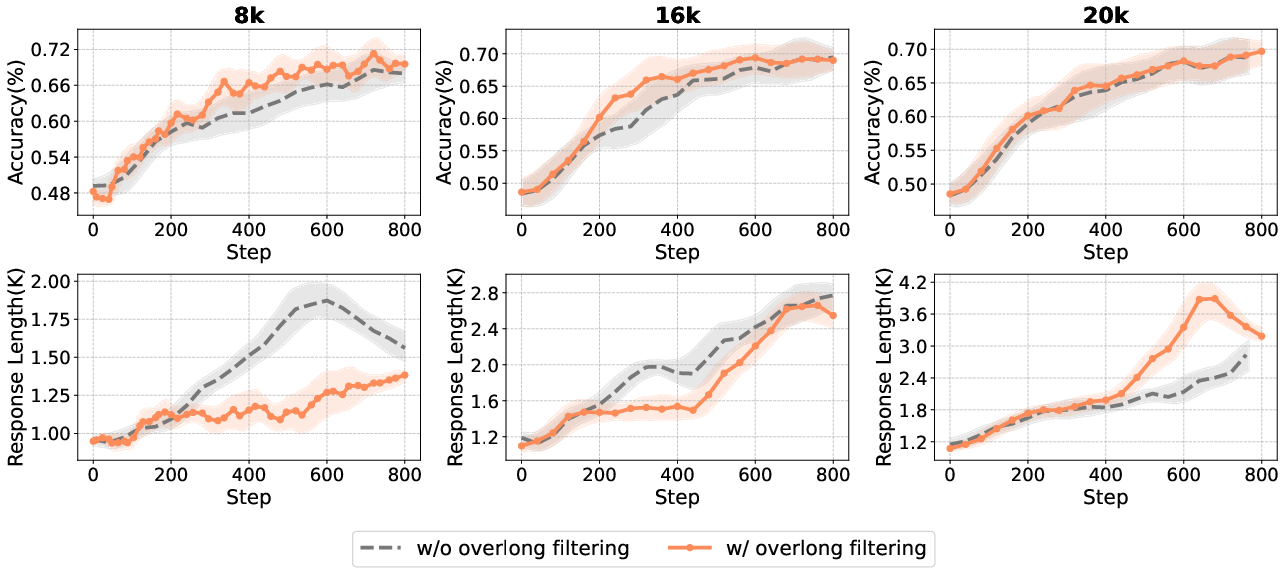
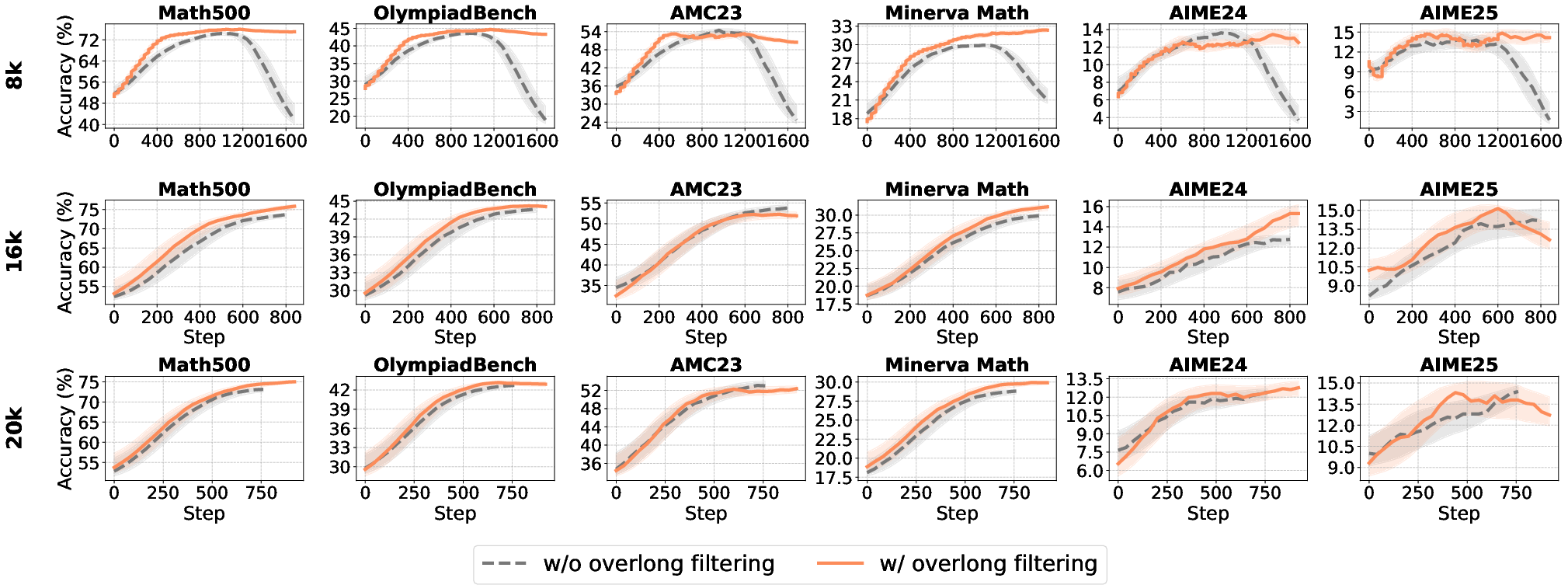

Figure 13: Impact of maximum generation length and overlong filtering on accuracy and response length.
- Overlong filtering is effective for short-to-medium reasoning tasks, improving accuracy and clarity.
- For long-tail reasoning, its benefits diminish, and it may filter out valid but lengthy solutions.
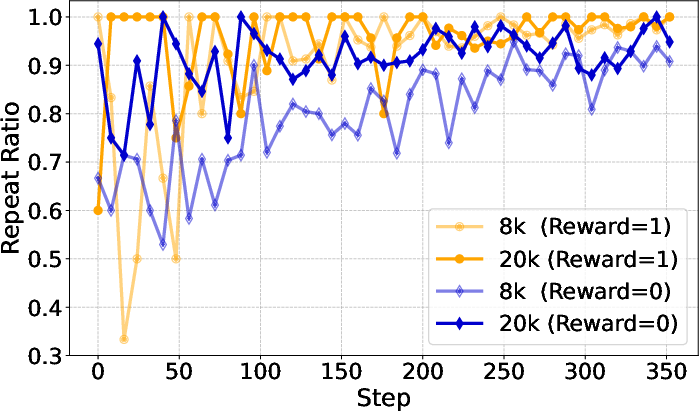
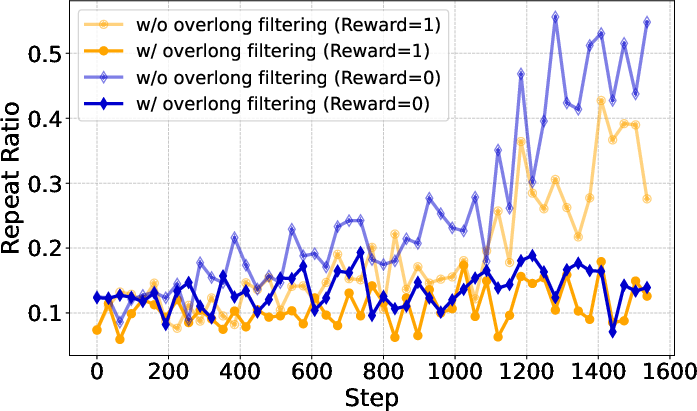
Figure 14: Repeat ratio analysis for different generation lengths and filtering strategies, highlighting the mitigation of degenerate generation.
Lite PPO: Minimalist RL for LLM Reasoning
Synthesizing the mechanistic insights, the study proposes Lite PPO: a critic-free PPO variant using group-level mean and batch-level std normalization, combined with token-level loss aggregation. This minimalist approach consistently outperforms more complex algorithms such as GRPO and DAPO across base model settings.
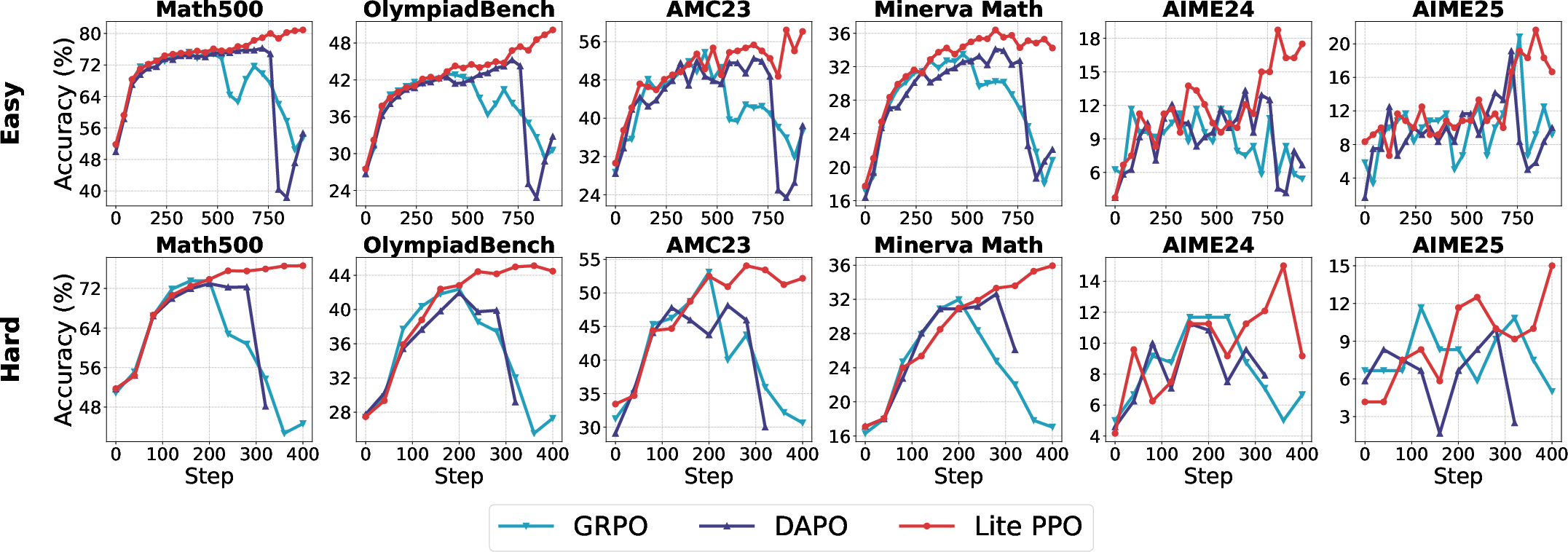
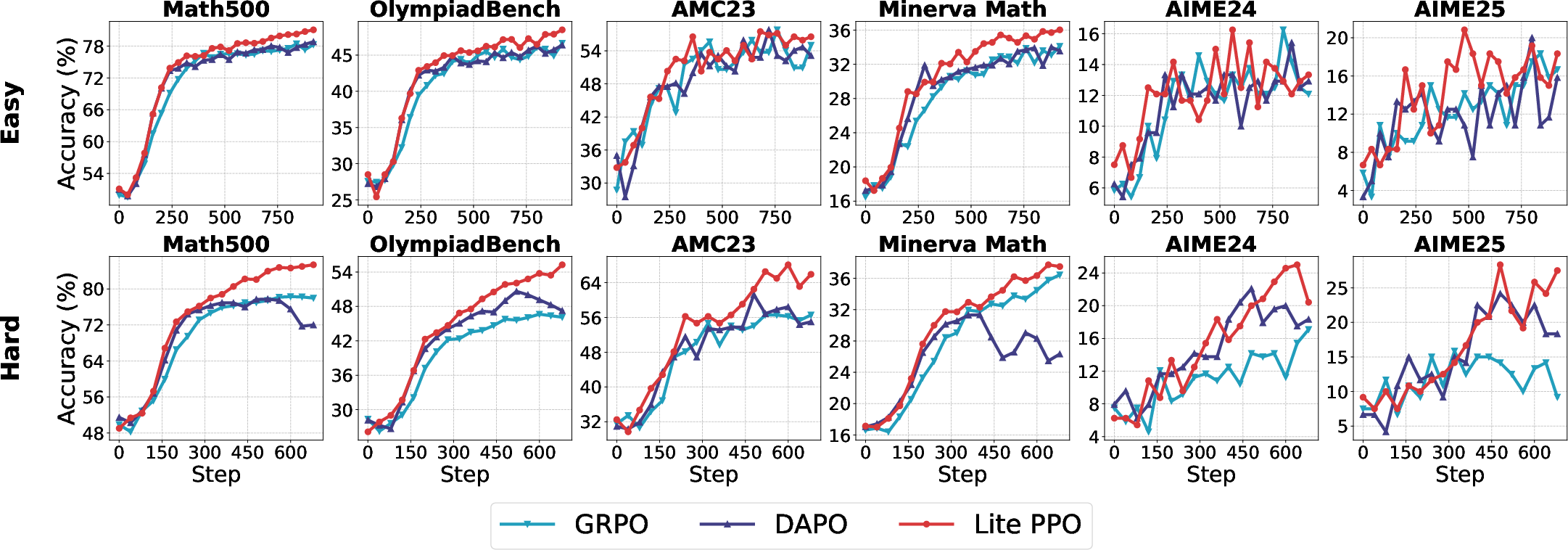
Figure 15: Test accuracy of non-aligned models trained with Lite PPO, GRPO, and DAPO, demonstrating the superiority of the minimalist approach.
Lite PPO's robustness is attributed to its ability to counteract reward distribution homogeneity and avoid overfitting to spurious signals, particularly in low-capacity or non-aligned models.
Implications and Future Directions
This work provides actionable guidelines for RL4LLM practitioners, emphasizing the importance of context-sensitive technique selection over indiscriminate accumulation of optimization tricks. The findings challenge the prevailing trend of over-engineering RL pipelines and advocate for principled, empirically validated minimalism.
Theoretically, the study clarifies the mechanistic underpinnings of normalization, clipping, and aggregation strategies, offering a foundation for future algorithmic innovation. Practically, the results facilitate more reliable and efficient deployment of RL for LLM reasoning, especially in resource-constrained or open-source settings.
Future research should extend these analyses to other LLM families, investigate the interaction of RL techniques with different pre-training regimes, and further develop unified, modular RL frameworks for LLM optimization.
Conclusion
"Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning" delivers a comprehensive, mechanistic evaluation of RL techniques for LLM reasoning, resolving key ambiguities and providing empirically grounded guidelines. The demonstration that a minimalist combination of robust normalization and token-level loss aggregation suffices to unlock strong performance in critic-free PPO settings has significant implications for both research and practice. The work sets a new standard for methodological rigor and transparency in RL4LLM studies, and its recommendations are poised to inform the next generation of scalable, efficient LLM optimization pipelines.