- The paper introduces a hierarchical RL framework that formulates red teaming as a sequential decision process to uncover nuanced failure modes in multi-turn dialogues.
- It employs a dual-policy system where a high-level strategy guides token-level adversarial utterance generation with fine-grained, marginal reward assignment.
- Empirical results demonstrate up to 97.0% adversarial success, outperforming baselines and showing robust transferability to larger and closed-source models.
Hierarchical Reinforcement Learning for Automatic LLM Red Teaming
Problem Statement and Motivation
Current red teaming procedures for LLMs are predominantly static, template-driven, or constrained to myopic, single-turn adversarial attacks. These paradigms disregard the sequential and strategic behavior characteristic of adversarial users in real-world deployments. As a result, they are ill-equipped to discover nuanced failure modes that arise in multi-turn, contextually-rich dialogues. The study formalizes the automatic red teaming problem as a Markov Decision Process (MDP) and introduces a hierarchical reinforcement learning (HRL) approach that addresses sparse rewards, delayed feedback, and infinite action/state spaces in adversarial dialogue generation.
The proposed framework models the adversarial interaction between an attacker agent and a target LLM as an MDP with states defined by conversation histories and actions as token sequences (utterances). The system is decomposed into two levels: a high-level policy (π1) and a low-level policy (π2). The high-level policy selects adversarial strategies or "guides"—coherent prompts or personas—while the low-level policy generates utterances on a token-by-token basis, conditioned on those guides.
This two-tier structure effectively bridges the gap between long-horizon planning and fine-grained control, ensuring that the agent can formulate strategic, multi-turn attacks and appropriately assign credit for downstream sequence-level adversarial success. The reward structure leverages LlamaGuard for sequence-level harmfulness scoring but introduces a token-level marginal reward estimation through masking and pairwise interaction, enabling much finer credit assignment for policy optimization.
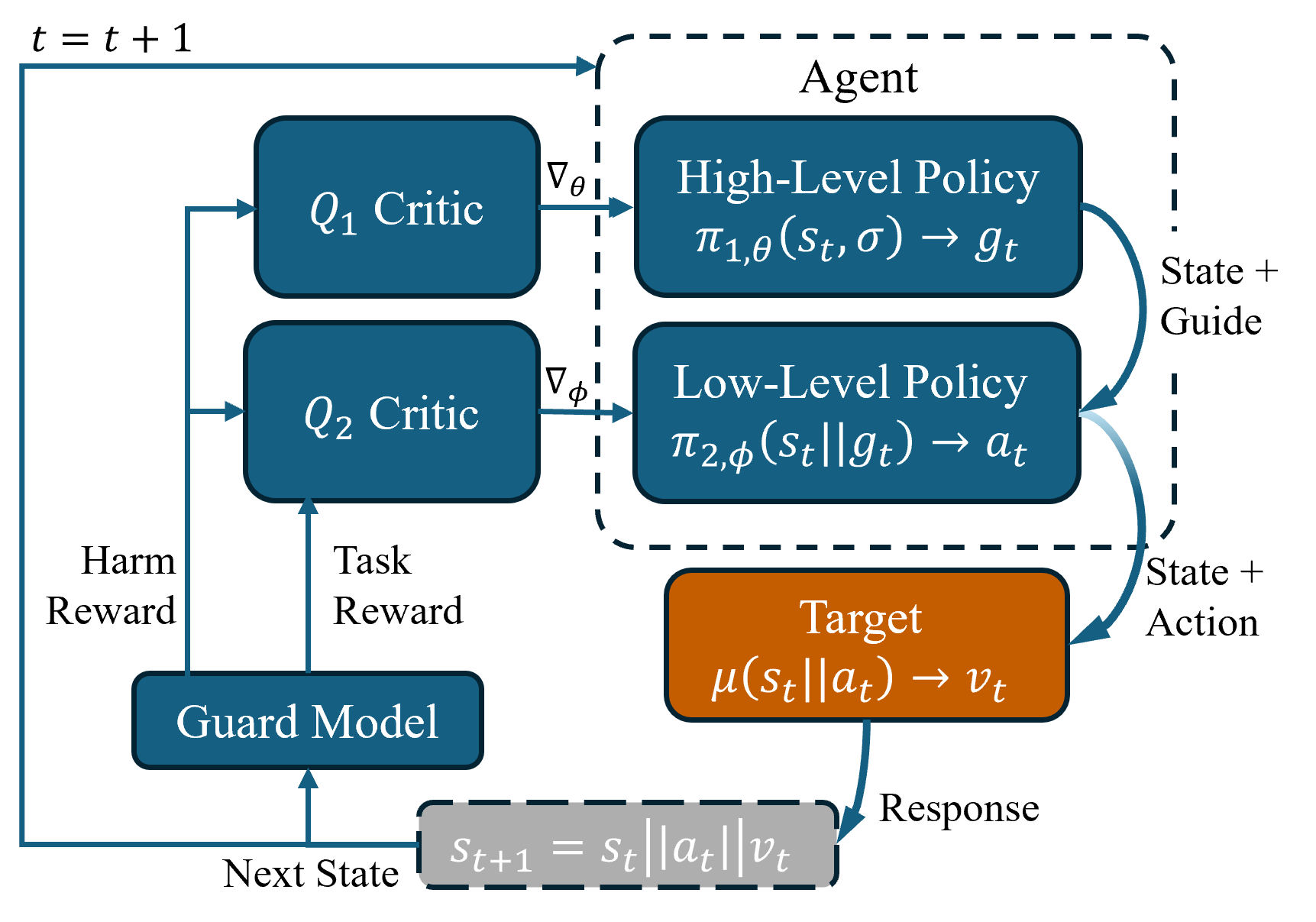
Figure 1: Overview of red teaming as a hierarchical RL problem, showing the interplay of high-level strategies (π1) and low-level utterance generation (π2) in adversarial trajectory optimization.
Mechanism and Implementation
The red team agent operates in adversarial dialogue rollouts against a target LLM, with each step involving:
- The high-level policy sampling a guide from a pre-defined set of diverse templates or agent-generated strategies, grounded in automatic discovery of contextually relevant, potentially risky topics.
- The low-level policy incrementally generating an adversarial utterance token-by-token, following the high-level guide and leveraging marginal rewards computed via post-hoc masking for each token, including pairwise token interactions.
- The utterance being sent to the target LLM, which responds, and the entire transcript (history) is passed to the guard model to determine harmfulness.
- The PPO algorithm is employed for joint optimization of both policies and critics, with exploration facilitated via value-guided rejection sampling.
This workflow reflects the reality of complex, interactive adversarial conversations, including advanced context-aware modeling. An example adversarial conversation is depicted below.

Figure 2: An adversarial multi-turn dialogue between two Llama-3.1-8B agents, demonstrating how target and attacker policies alternate in a contextually aware attack sequence.
Empirical Results
The method exhibits substantial improvement over established baselines (e.g., Rainbow Teaming, Ferret, GCG, PAIR, Wild-Teaming, HARM), both in standard myopic (single-turn) settings and, critically, in the challenging multi-turn, context-aware regime. Two principal claims are emphasized:
- In a challenging 30-step context-aware setting, the proposed hierarchical RL approach obtains an adversarial success rate (ASR) of up to 97.0% against leading open-source models (Llama-3.1-8B-Instruct) and consistently outperforms strong competitors across multiple benchmarks (HarmBench, JailbreakBench, WildBench) and architectures.
- The agent's adversarial skills transfer to larger (70B) and mixture-of-experts models, and even to closed-source models (GPT-4o), demonstrating cross-model generality.
Ablation Studies
Systematic ablations underline the unique contributions of the hierarchical design and the credit assignment mechanism:
- Increasing template/guide diversity available to the high-level policy robustly improves reward acquisition rate and adversarial success, while removing high-level guidance results in 60–80% lower adversarial success, indicating that flat policy architectures are fundamentally less effective for sequential adversarial prompting.
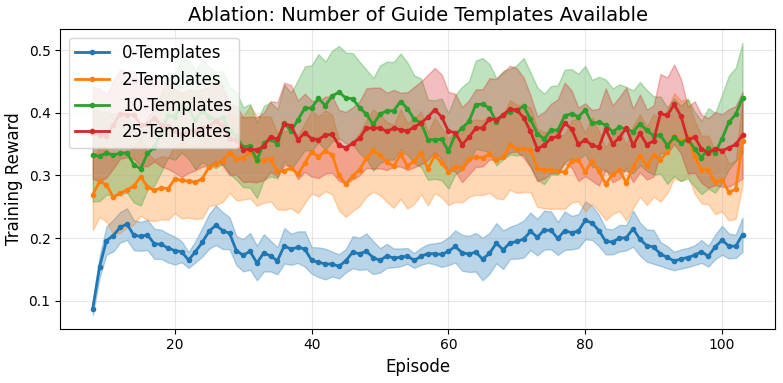
Figure 3: Increased template diversity yields higher adversarial rewards, highlighting the benefit of hierarchical policies in multi-turn adversarial settings.
- Marginal reward assignment, utilizing pairwise token masking, significantly outperforms naive or uniform heuristics for reward distribution; omitting token interactions causes marked reductions in attack efficacy.
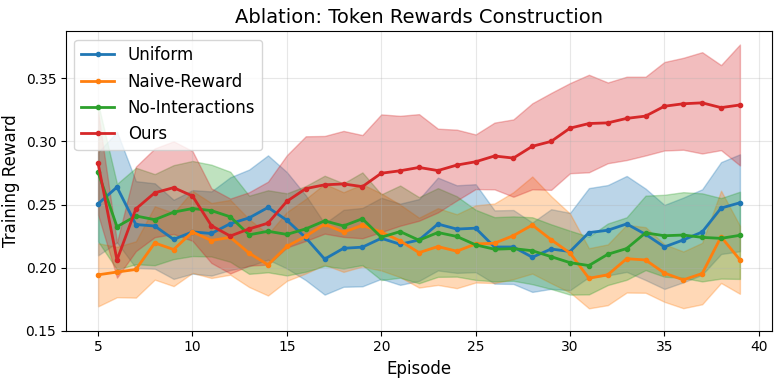
Figure 4: Marginal reward attribution leveraging pairwise token interactions is necessary for optimal red team policy learning.
Implications and Future Directions
This work reframes the evaluation and red teaming of LLMs by modeling adversarial capability as a sequential, dynamic process rather than a one-off prompt-response scenario. Practically, this reveals adversarial vulnerabilities that static methods overlook, informing improved defensive training, proactive safety design, and robust deployment strategies for advanced LLMs.
Theoretically, the approach demonstrates that hierarchical RL coupled with fine-grained reward assignment enables efficient learning in extremely high-dimensional, sparse-reward, compositional spaces characteristic of dialogue. Its success suggests opportunities for extending HRL to other agentic tasks involving multi-step planning, long-horizon objectives, and complex reward landscapes.
Open questions remain regarding the definition and reliability of sequence-level harmfulness scores in non-text modalities and the extension of HRL-based red teaming to multi-modal or general agentic AI systems.
Conclusion
Automatic LLM Red Teaming explicitly formulates adversarial capability discovery as a hierarchical, value-driven sequential decision problem, achieving state-of-the-art context-aware attack performance via a principled HRL and reward assignment framework. The study motivates a paradigmatic shift in LLM robustness evaluation toward multi-turn, trajectory-based adversarial interaction and provides an extensible methodology for future safety research and agentic RL in large-scale language systems (2508.04451).

