- The paper introduces the STIM framework that quantifies token-level memorization by distinguishing local, mid-range, and long-range sources in CoT reasoning.
- It employs Spearman correlation between predicted probabilities and co-occurrence frequencies to attribute errors to specific memorization sources.
- Experiments reveal that under distributional shifts, complex tasks intensify memorization, often triggering cascading reasoning failures.
Diagnosing Token-Level Memorization in Chain-of-Thought Reasoning
Introduction
This paper introduces STIM (Source-aware Token-level Identification of Memorization), a framework for fine-grained analysis of memorization in Chain-of-Thought (CoT) reasoning within LLMs. The motivation stems from the observation that CoT reasoning is highly susceptible to cascading errors, often triggered by a single mis-predicted token influenced by memorized patterns from pretraining data. The study systematically quantifies the influence of local, mid-range, and long-range memorization sources at the token level, providing new insights into the mechanisms underlying reasoning failures and the role of memorization under distributional shift.

Figure 1: Cascading errors in Chain-of-thought (CoT) reasoning can stem from a single mis-predicted token, often influenced by incorrect memorization of pretraining data.
STIM Framework: Source-aware Token-level Identification of Memorization
STIM decomposes token-level memorization into three distinct sources:
- Local Context Memorization: Driven by frequent continuations in the immediate context (n-gram statistics).
- Mid-range Memorization: Influenced by spurious associations within the partially generated output.
- Long-range Memorization: Attributed to salient input tokens that co-occurred with the target token in pretraining.
For each token x in a reasoning chain, STIM computes the Spearman correlation between the model's predicted probabilities for candidate tokens and their corresponding co-occurrence frequencies in the pretraining corpus, separately for each source. The dominant source is identified as the one with the highest score for a given token.
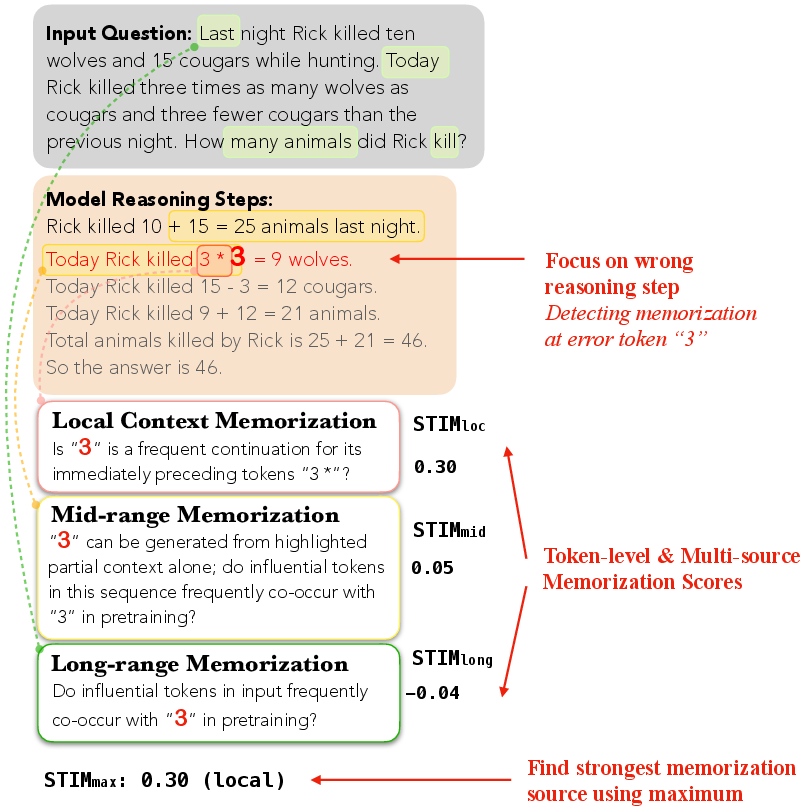
Figure 2: STIM quantifies local, mid-range, and long-range memorization at each token in a faulty reasoning step and identifies the dominant source. STIM is helpful for detecting error tokens.
This multi-source attribution enables precise diagnosis of memorization-driven errors, distinguishing between spurious local completions and global pattern recall.
Experimental Setup and Distributional Shift
The study evaluates OLMo 2 (13B) on four reasoning tasks of varying complexity: Applied Math, Formula Calculation, Counting, and Capitalization. Each task is assessed under both base and long-tail input distributions, with long-tail variants constructed by reducing entity frequency or altering task format (e.g., base-2 arithmetic, rare fruits, atypical capitalization).
Performance metrics reveal a pronounced degradation under long-tail settings, especially in CoT formats, indicating increased reliance on memorization and reduced generalization capacity.
Token-Level Memorization Analysis
STIM is applied to analyze token-level memorization patterns across tasks, distributions, and correctness. Key findings include:
- Complexity Correlates with Memorization: Higher reasoning complexity (Applied Math, Formula Calculation) yields higher token-level memorization scores.
- Distributional Shift Amplifies Memorization: Long-tail inputs induce stronger memorization signals, with models falling back on spurious patterns when faced with unfamiliar contexts.
- Role Reversal Under Shift: In base settings, memorization supports correct reasoning; in long-tail, it more frequently drives errors.
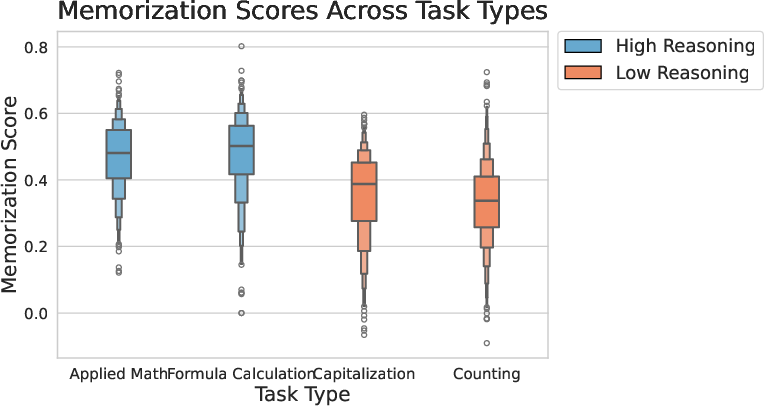

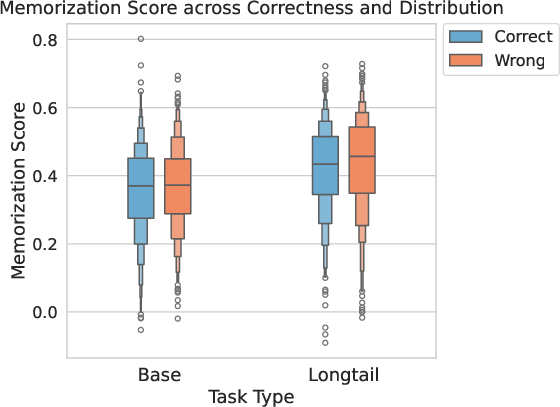
Figure 3: Distribution of STIMmax by task, showing higher memorization scores for complex reasoning tasks.
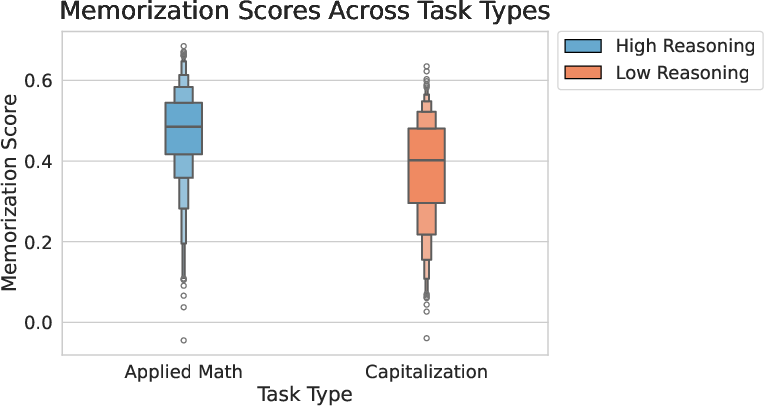
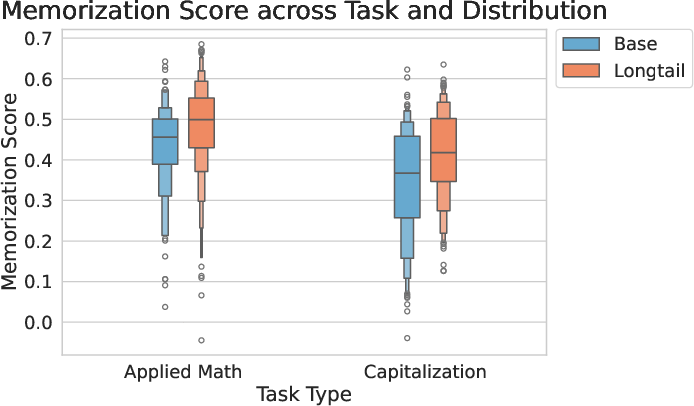
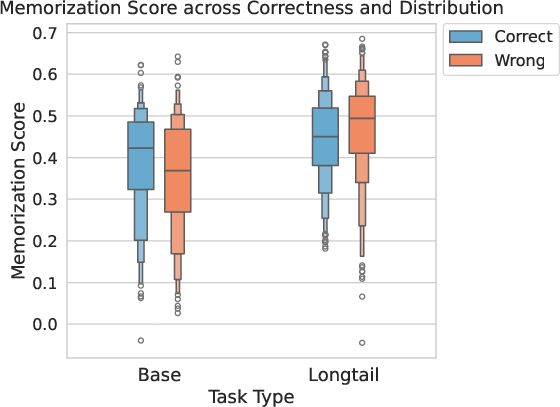
Figure 4: Distribution of STIMmax by distribution, highlighting increased memorization in long-tail settings.
Error Attribution and Predictive Utility
STIM demonstrates strong predictive power for identifying erroneous tokens in flawed reasoning steps. Precision@k and Recall@k metrics are substantially above random baselines, especially for complex tasks. Notably, local memorization is the dominant driver of errors, accounting for up to 67% of wrong tokens. Under distributional shift, the proportion of local memorization-driven errors decreases in high-reasoning tasks, suggesting a shift toward more global reasoning strategies.
The computational complexity of wrong token identification with STIM is O(mn), where m is the number of salient tokens and n is the number of candidate tokens per target.
Implementation Considerations
- Pretraining Data Indexing: STIM requires access to fully indexed pretraining corpora for n-gram and co-occurrence statistics. This currently limits applicability to models such as OLMo and Pythia.
- Token Saliency Methods: The framework is agnostic to the choice of token saliency method, but perturbation-based approaches (LERG) offer favorable compute efficiency. Gradient-based or causal tracing methods may yield finer attribution at higher cost.
- Step Verification: Reliance on Process Reward Models (PRMs) for step-wise error detection introduces some noise; ensemble or stronger verifiers could improve robustness.
Limitations and Risks
The framework's dependence on open, indexed corpora restricts its use to a subset of available models. There is a risk of misuse for tracing proprietary or sensitive information, and the environmental cost of extensive corpus queries is non-negligible.
Implications and Future Directions
STIM provides a principled approach for diagnosing memorization in step-wise reasoning, with direct applications in model auditing, error analysis, and the development of more robust LLMs. The token-level granularity enables targeted interventions, such as regularization or data augmentation, to mitigate memorization-driven failures. Future work may extend STIM to other structured generation tasks (dialogue, summarization) and integrate more advanced attribution and verification techniques.
Conclusion
STIM advances the state of the art in diagnosing memorization in CoT reasoning by attributing errors to specific sources at the token level. The framework reveals that memorization intensifies with task complexity and distributional shift, often leading to cascading reasoning failures. By reliably identifying error-inducing tokens, STIM offers a valuable tool for understanding and improving the reasoning capabilities of LLMs, with broad implications for model reliability and interpretability.

