- The paper evaluates nine LLMs to reveal the trade-off between memorization and discourse quality in generated texts.
- It employs empirical analysis with plagiarism detection and human annotation to quantify factual errors, logical fallacies, and PII.
- The study demonstrates that targeted prompts can effectively reduce memorization, challenging the balance between originality and accuracy.
LLM Output Evaluation: Discourse and Memorization
This paper (2304.08637) presents an empirical evaluation of the outputs from nine widely available LLMs using readily available tools to understand the relationship between memorization of training data and output quality, as measured by discourse coherence and the presence of factual errors, logical fallacies, and PII. The study found that higher-quality discourse often correlates with models that memorize the most, raising questions about the necessity of memorization for factual accuracy and overall text quality.
Experimental Setup
The authors evaluated BLOOM, ChatGPT, Galactica, GPT-3, GPT-4, OPT, OPT-IML, and LLaMA, selected based on media presence, ease of access, and citation rates. For each model, 75 texts were generated using prompts from five domains: scientific papers, blog posts, knowledge retrieval, long-text autocompletion, and common text openers. The generated texts were then evaluated across several categories including the presence of PII, factual errors, logical fallacies, discourse coherence, presence of memorized text, and percentage of original text. Readily available plagiarism detection tools and human annotation were used.
Key Findings
The study yielded several key findings:
- Approximately 80% of the outputs contained some degree of memorization, with an average of 82.3% original text.
- Around 46.4% of the generated texts contained factual errors, 31.3% had discourse flaws, 46.4% contained logical fallacies, and 15.4% generated PII.
- Performance varied significantly across models and categories. For example, the GPT-3 models and ChatGPT had the highest incidence of memorization but also the highest-quality discourse. Galactica had a high incidence of factual errors and logical inconsistencies, particularly when prompted about blog posts.
- Explicitly prompting the models to avoid outputting memorized content mitigated the amount of content flagged by plagiarism detection tools.
- A strong anticorrelation was found between factual errors and memorized text for several models.
- The study confirmed the relationship between text uniqueness and memorization, extending these results to overall discourse quality.
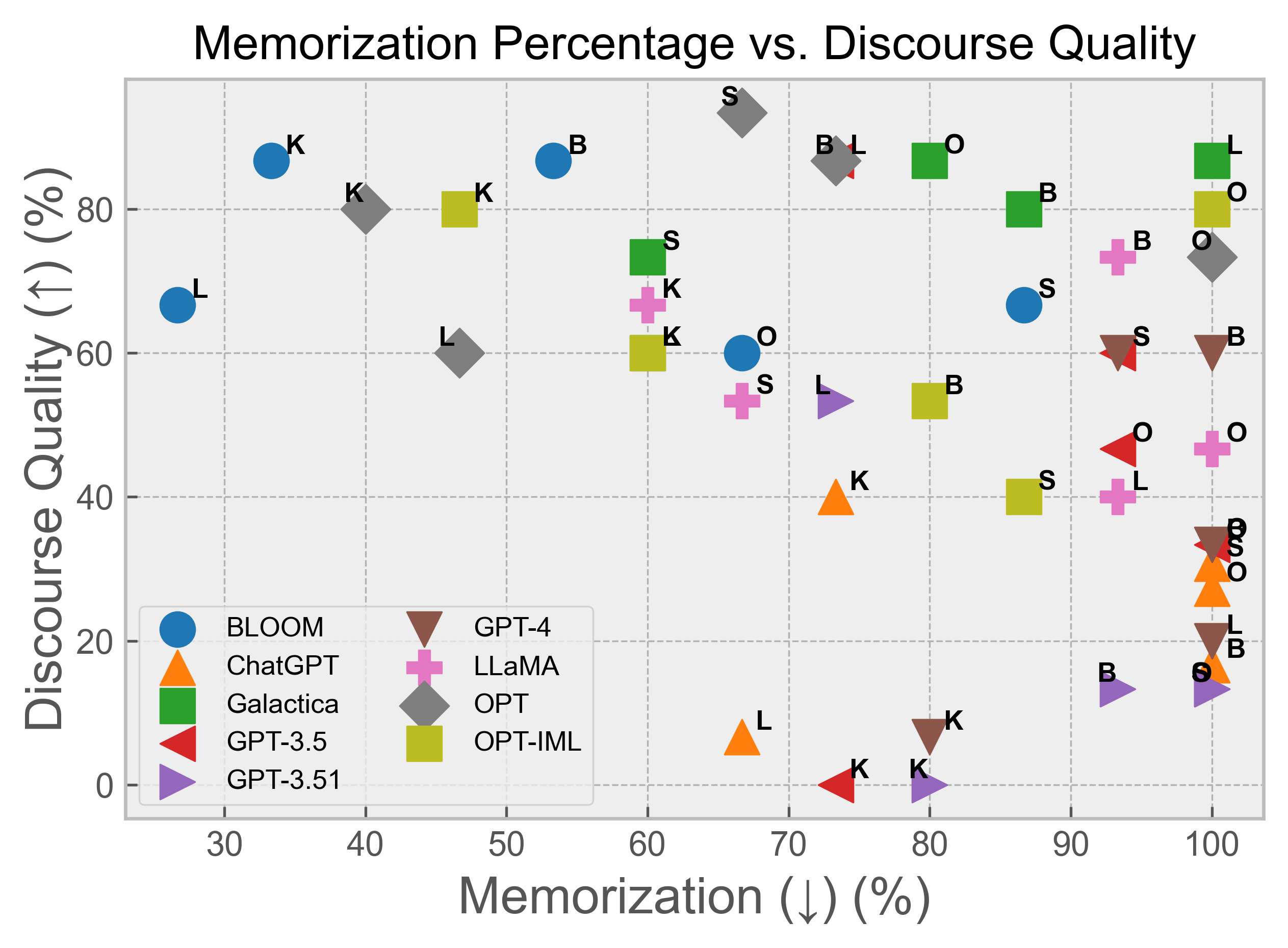
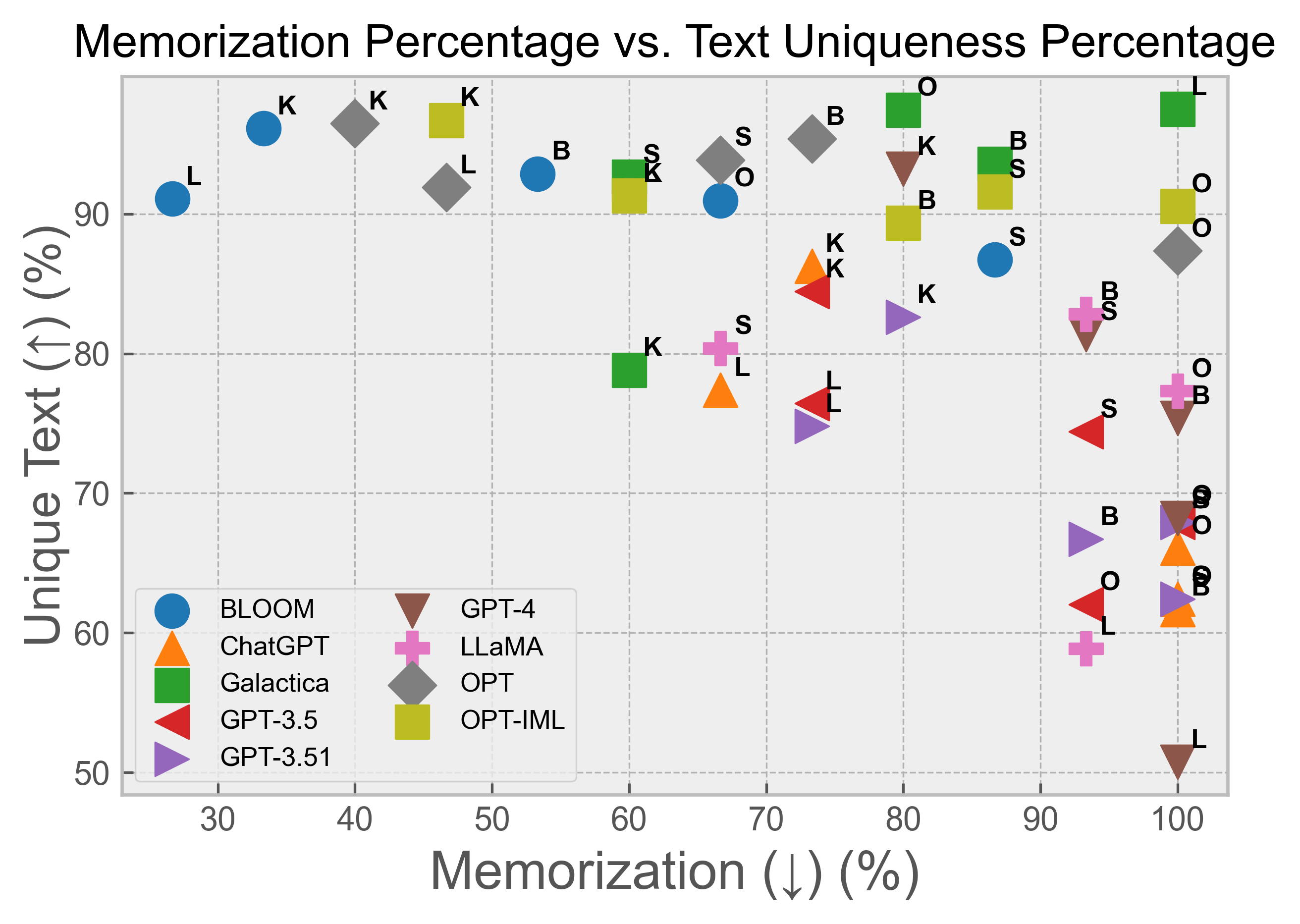
Figure 1: Discourse quality as a function of the percentage of memorized text.
Correlation Analysis
The correlation between memorized text and other variables was analyzed using Pearson's ρ correlation coefficient. A weak anti-correlation (ρ=−0.40) was found between output text quality and the percentage of memorization. The amount of unique text being output was more strongly anti-correlated with memorized text (ρ=−0.61) and discourse quality (ρ=−0.63). The correlation between factuality and memorized text was also examined, revealing considerable variability across models. For example, the quality of the output was very strongly correlated with text uniqueness for Galactica (ρ=0.97) but not for GPT-3.51 (ρ=0.0).
Prompt Length and Memorization
The study compared prompt length with the amount of memorization. Shorter prompts, excluding baseline prompts, were associated with higher proportions of memorization, a trend consistently observed across the models (Figure 2). This suggests that the tendency to output memorized text is a general characteristic of the LLMs evaluated.
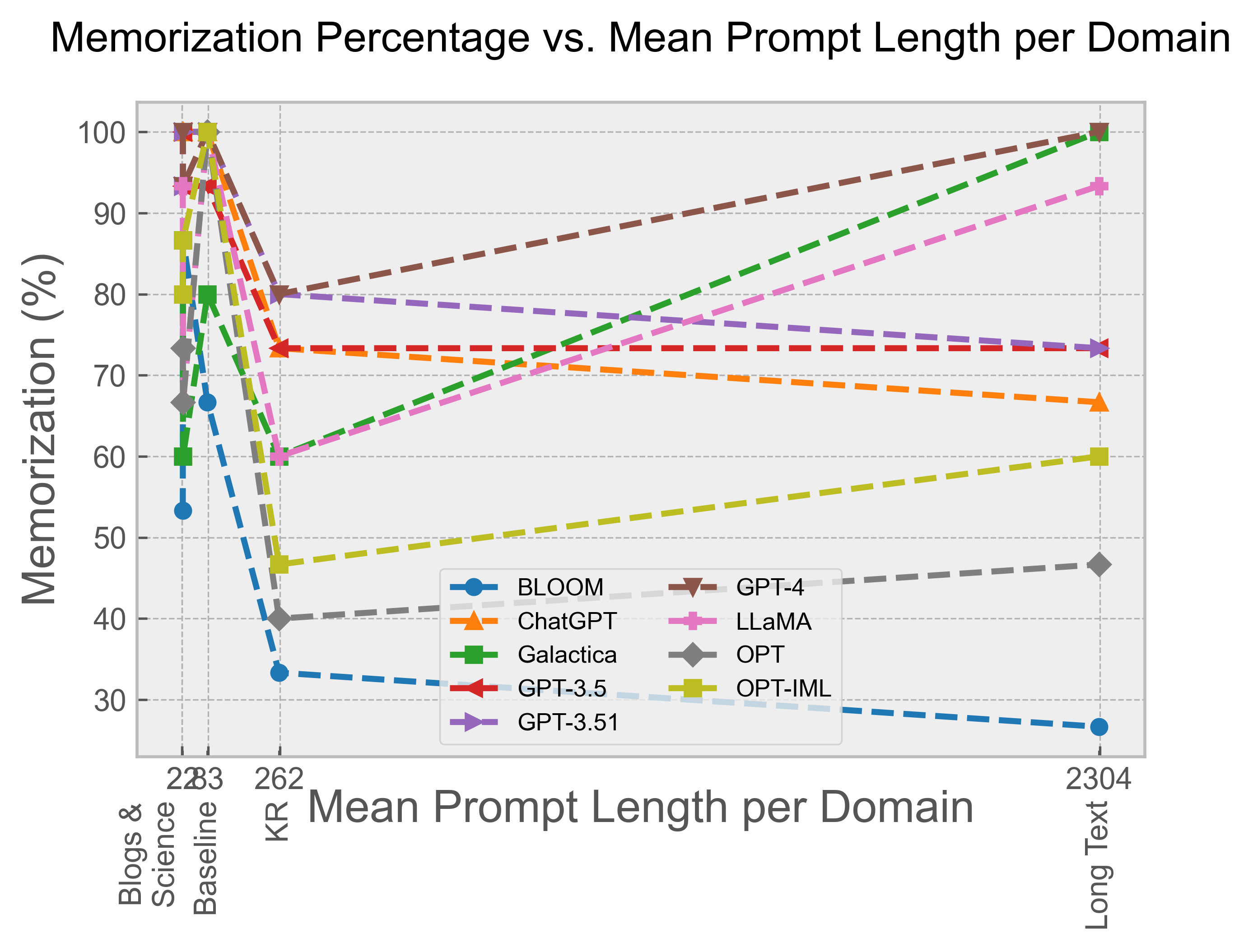
Figure 2: Memorization percentage as a function of the length of the prompt (in characters), per domain.
Mitigation Strategies
The paper explored mitigation strategies for reducing memorization by prompting the models to avoid outputting pre-existing content. Results showed that models were generally receptive to this prompting strategy, with ChatGPT showing an average increase of +29% in original text and GPT-4 decreasing in its memorization incidence by -40%.
Implications and Future Directions
The findings suggest that a considerable amount of discourse quality was contributed by biased prompts and memorized text. The study raises critical questions about the trade-offs between memorization, factuality, and text uniqueness in LLMs. Future research could explore the extent to which memorization is necessary for factually correct output and the amount of memorization needed to perform statistical learning. Additionally, further work could focus on developing methods for automating the evaluation of model performance, particularly in terms of argumentative and reasoning capabilities.
Conclusion
The study highlights the complex relationship between discourse quality and memorization in LLMs (2304.08637). While some models generate high-quality text but are often flagged as memorized, others show a lower incidence of memorization at the expense of output quality. These findings have implications for how the scientific community evaluates model performance and how LLMs are used safely and responsibly.