- The paper introduces a novel methodology to identify key reasoning sentences—thought anchors—that significantly affect LLM outputs.
- It employs three attribution methods: black-box resampling, white-box attention aggregation, and causal attention suppression to assess sentence importance.
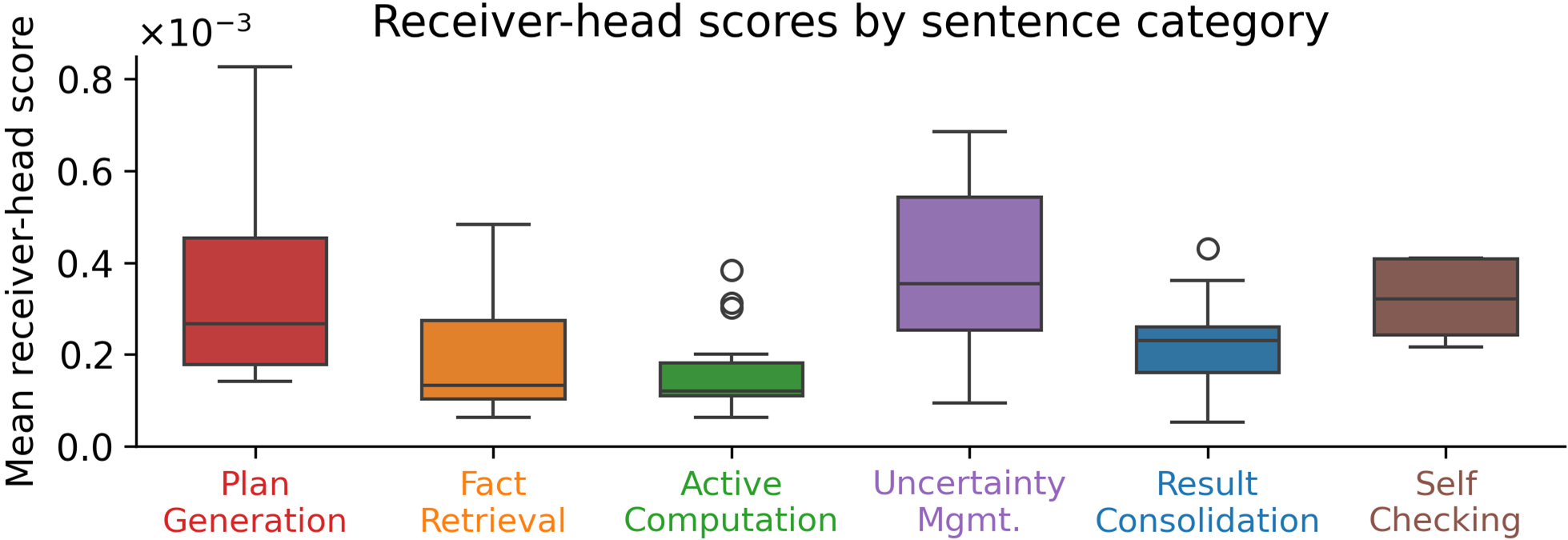
- Findings reveal that planning and uncertainty management sentences are critical anchors, providing actionable insights for debugging and enhancing LLM reliability.
Thought Anchors: Identifying Key Reasoning Steps in LLMs
This paper introduces a methodology for dissecting the reasoning processes of LLMs, shifting the focus from token-level analysis to a more abstract, sentence-level understanding. The core argument posits that not all sentences within a chain-of-thought reasoning trace are created equal; rather, certain "thought anchors" exert disproportionate influence on the model's final answer and subsequent reasoning steps. To identify these critical sentences, the authors propose three complementary attribution methods: black-box resampling, white-box attention aggregation, and causal attention suppression. These methods are applied to the DeepSeek R1-Distill Qwen-14B model, with supplementary analysis on R1-Distill-Llama-8B, using the MATH dataset.
Methodological Framework
The authors present a multi-faceted approach to identify and characterize thought anchors within LLM reasoning traces. (Figure 1) summarizes these methods.

Figure 1: Summary of our three methods for principled attribution to important sentences in reasoning traces. A. An example reasoning trace with sentences labeled per our taxonomy. B. Our proposed methods are: black-box resampling, receiver heads, and attention suppression. C. A directed acyclic graph among sentences prepared by one of our techniques, made available open source.
Black-Box Resampling
This method measures the counterfactual importance of a sentence by comparing the model's final answers across multiple rollouts. The key idea is to resample reasoning traces from the start of each sentence, effectively creating variations of the original thought process. By quantifying the impact of each sentence on the likelihood of different final answers, the authors can identify sentences that significantly alter the model's conclusions. Furthermore, the method distinguishes between "planning" sentences that initiate computations and "necessary" sentences that perform computations but are predetermined by earlier steps.
White-Box Attention Aggregation
This approach leverages the internal attention mechanisms of the LLM to identify important sentences. The authors analyze attention patterns between pairs of sentences, revealing "receiver" heads that focus attention on specific past "broadcasting" sentences. By identifying these receiver heads and evaluating sentences based on the extent to which they are broadcast, the method provides a mechanistic measure of importance.
Causal Attention Suppression
This method measures the causal dependency between pairs of sentences by selectively suppressing attention toward one sentence and measuring the effect on subsequent token logits. By averaging token effects at the sentence level, this strategy quantifies each sentence's direct causal effect on subsequent sentences.
Sentence Taxonomy and Experimental Setup
To facilitate a structured analysis, the authors adopt a sentence taxonomy based on distinct reasoning functions. These include problem setup, plan generation, fact retrieval, active computation, uncertainty management, result consolidation, self-checking, and final answer emission. Each sentence in the reasoning trace is assigned to one of these categories using an LLM-based auto-labeling approach. (Figure 2) shows the frequency of each sentence category.
The experiments are conducted using the DeepSeek R1-Distill Qwen-14B model and the MATH dataset. The authors focus on challenging mathematics questions that the model solves correctly 25-75% of the time, generating both correct and incorrect reasoning traces for each problem.
Results and Observations
The application of the three attribution methods reveals several key findings:
The authors present a detailed case study to illustrate the utility and complementary nature of the three techniques. By applying these methods to a specific problem, they demonstrate how thought anchors can be identified and how they contribute to the overall reasoning process.
Implications and Future Directions
This research has significant implications for understanding and improving the reasoning capabilities of LLMs. By identifying thought anchors, the authors provide a framework for more precise debugging of reasoning failures, identification of sources of unreliability, and development of techniques to enhance the reliability of reasoning models.
The authors acknowledge several limitations of their work, including the need for refinement in handling overdetermined sentences and the limited examination of error correction. They also note that the receiver-head analyses are confounded by sentence position and that the attention-suppression method requires the model to process out-of-distribution information.
Despite these limitations, the authors believe that their work represents a significant step toward a principled decomposition of reasoning traces and that the surprising degree of shared structure found across the three methods illustrates the potential value of future research in this area.
Conclusion
This paper offers a valuable contribution to the field of LLM interpretability by introducing a novel approach to analyzing reasoning traces at the sentence level. The proposed methods provide a powerful tool for identifying thought anchors and understanding their role in the reasoning process. By focusing on these critical sentences, researchers can gain deeper insights into the inner workings of LLMs and develop more effective strategies for improving their reasoning capabilities.