Can AI Relate: Testing Large Language Model Response for Mental Health Support
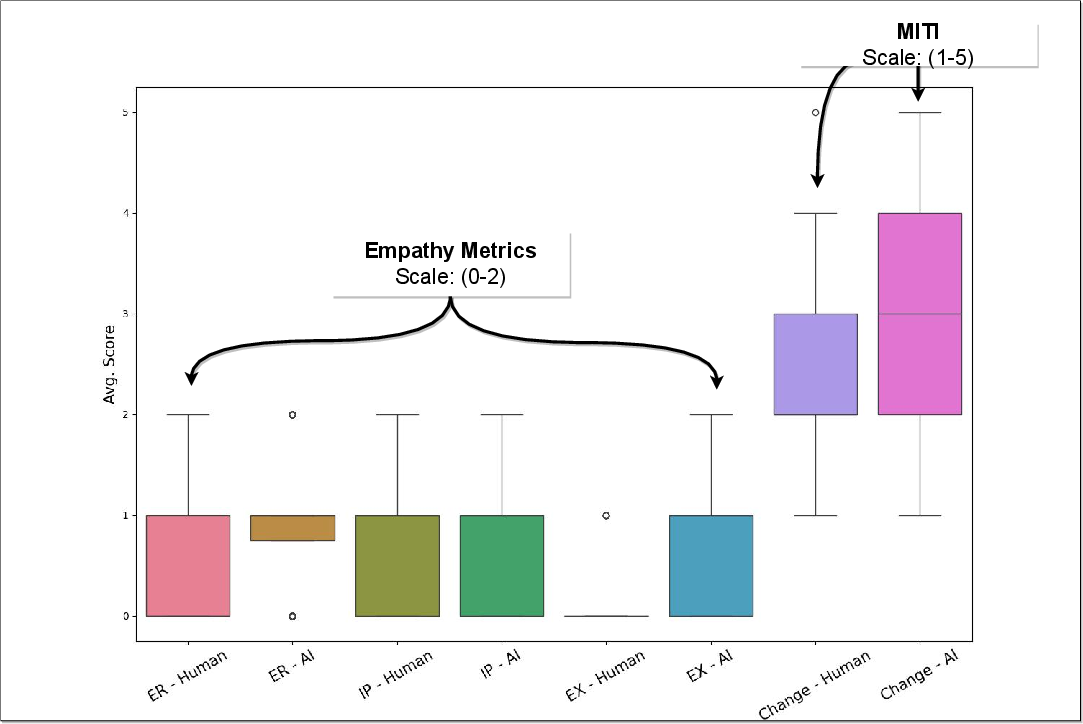
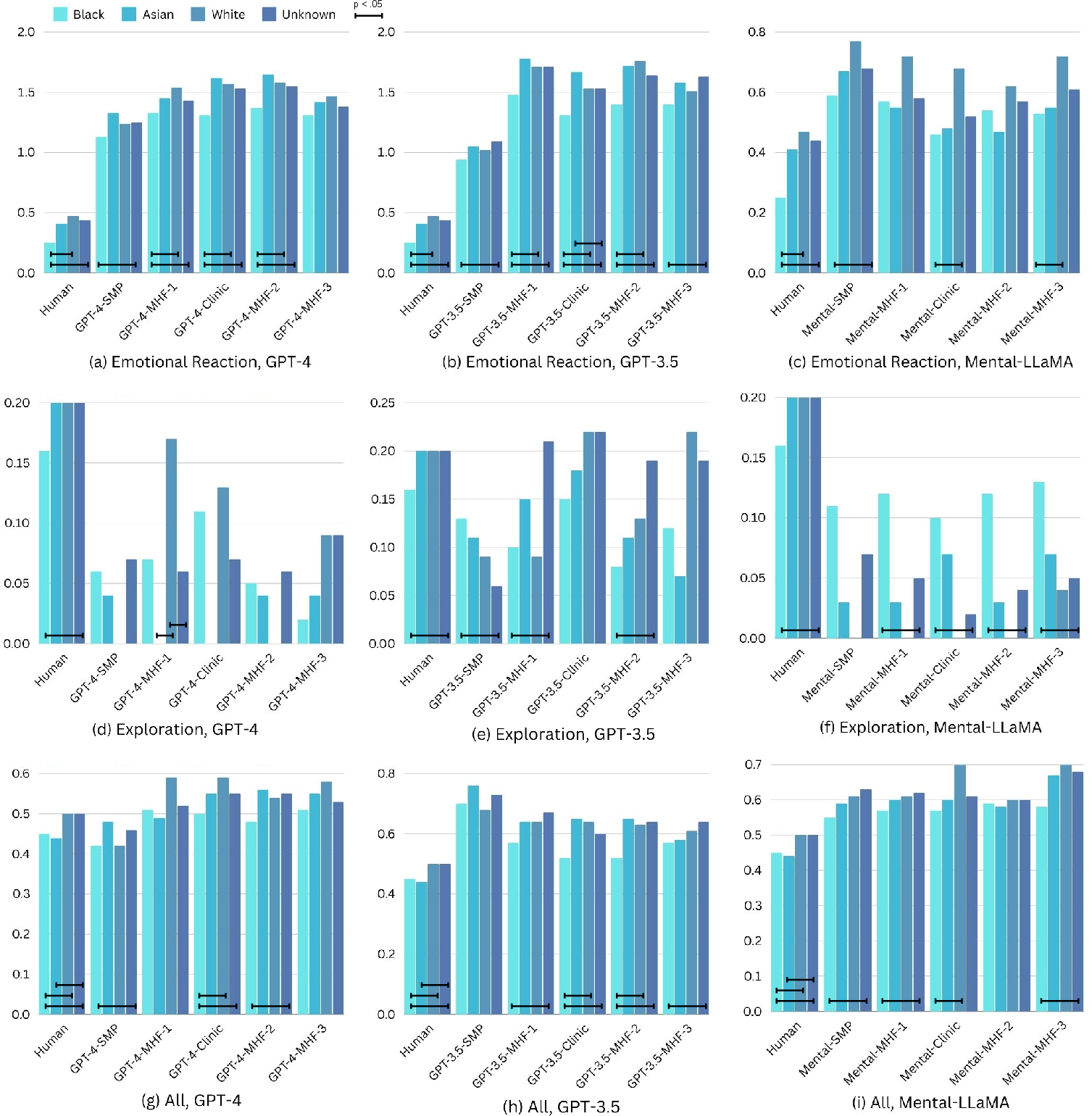
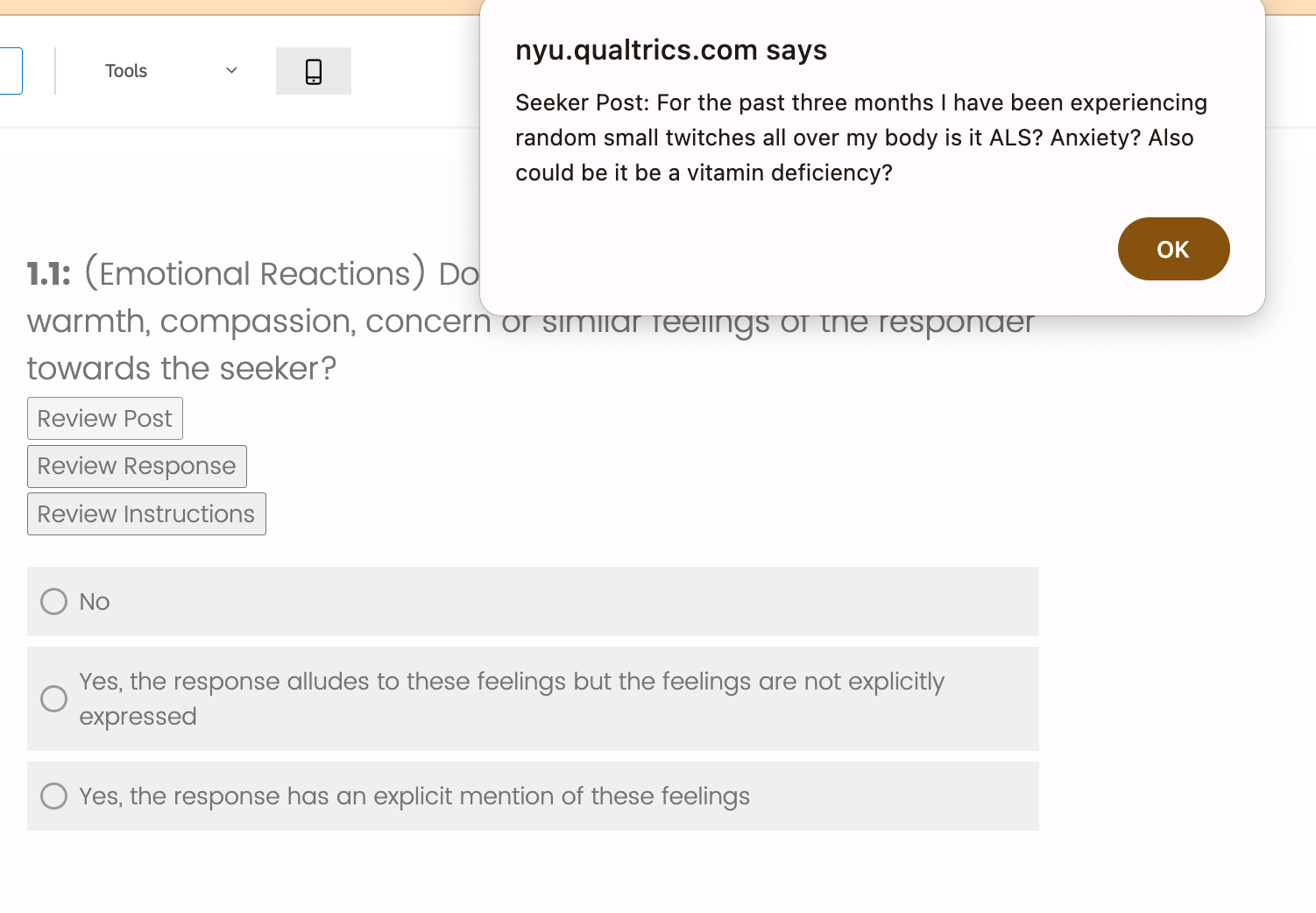
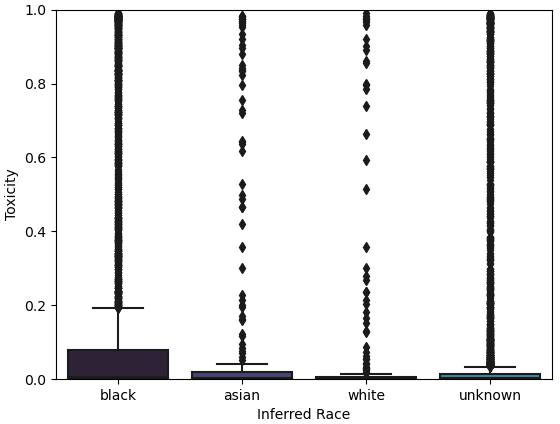
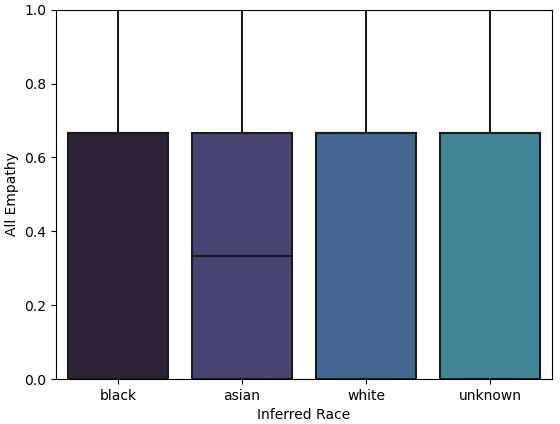
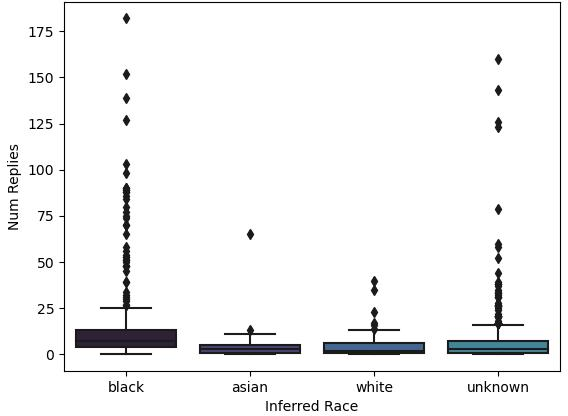
Abstract: LLMs are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Our framework measures equity in empathy and adherence of LLM responses to motivational interviewing theory. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
- Mitigating the impact of biased artificial intelligence in emergency decision-making. Communications Medicine, 2.
- Write it like you see it: Detectable differences in clinical notes by race lead to differential model recommendations. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, AIES ’22, page 7–21, New York, NY, USA. Association for Computing Machinery.
- Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Internal Medicine, 183(6):589–596.
- The dissemination of empirically supported treatments: a view to the future. Behaviour research and therapy, 37 Suppl 1:S147–62.
- Demographic dialectal variation in social media: A case study of African-American English. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1119–1130, Austin, Texas. Association for Computational Linguistics.
- Physician and artificial intelligence chatbot responses to cancer questions from social media. JAMA oncology.
- The impact of responding to patient messages with large language model assistance.
- A computational framework for behavioral assessment of llm therapists. arXiv preprint arXiv:2401.00820.
- An integrative survey on mental health conversational agents to bridge computer science and medical perspectives. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11346–11369, Singapore. Association for Computational Linguistics.
- Benefits and harms of large language models in digital mental health. ArXiv, abs/2311.14693.
- Challenges of large language models for mental health counseling. arXiv preprint arXiv:2311.13857.
- Acceptance and commitment therapy: a transdiagnostic behavioral intervention for mental health and medical conditions. Neurotherapeutics, 14:546–553.
- Lance Eliot. 2023. Key lessons involving generative ai mental health apps via that eating disorders chatbot tessa which went off the rails and was abruptly shutdown. Forbes.
- Statistical power analyses using g*power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41:1149–1160.
- Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (woebot): A randomized controlled trial. JMIR Mental Health, 4.
- The capability of large language models to measure psychiatric functioning. ArXiv, abs/2308.01834.
- Charles J. Gelso. 1979. Research in counseling: Methodological and professional issues. The Counseling Psychologist, 8(3):7–36.
- Ai recognition of patient race in medical imaging: a modelling study. The Lancet. Digital health, 4:e406 – e414.
- John Gramlich. 2023. Mental health and the pandemic: What u.s. surveys have found. Pew Research Short Reads.
- Closing the accessibility gap to mental health treatment with a conversational ai-enabled self-referral tool. medRxiv.
- Large language models in mental health care: a scoping review. ArXiv, abs/2401.02984.
- Testing the implicit-explicit model of racialized political communication. Perspectives on Politics, 6:125 – 134.
- The accuracy and potential racial and ethnic biases of gpt-4 in the diagnosis and triage of health conditions: Evaluation study. JMIR Medical Education, 9.
- Counterfactual fairness. ArXiv, abs/1703.06856.
- Heather Landi. 2024. Himss24: How epic is building out ai, ambient technology for clinicians. Fierce Healthcare.
- Loneliness and suicide mitigation for students using gpt3-enabled chatbots. npj Mental Health Research.
- Towards an artificially empathic conversational agent for mental health applications: System design and user perceptions. Journal of Medical Internet Research, 20.
- The motivational interviewing treatment integrity code (miti 4): Rationale, preliminary reliability and validity. Journal of substance abuse treatment, 65:36–42.
- The future of mental health care: peer-to-peer support and social media. Epidemiology and Psychiatric Sciences, 25:113 – 122.
- Large language models propagate race-based medicine. NPJ Digital Medicine, 6.
- OpenAI. 2022. Gpt-3.5.
- OpenAI. 2023. Gpt-4 technical report.
- Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830.
- Getting explicit about implicit bias. Duke Judicature, Vol. 104 No. 3.
- Improving language understanding by generative pre-training.
- Generalization in healthcare ai: Evaluation of a clinical large language model. ArXiv, abs/2402.10965.
- Kenneth Resnicow and Fiona McMaster. 2012. Motivational interviewing: moving from why to how with autonomy support. The International Journal of Behavioral Nutrition and Physical Activity, 9:19 – 19.
- Racial inequality in psychological research: Trends of the past and recommendations for the future. Perspectives on Psychological Science, 15:1295 – 1309.
- The risk of racial bias in hate speech detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1668–1678, Florence, Italy. Association for Computational Linguistics.
- Developing age and gender predictive lexica over social media. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1146–1151, Doha, Qatar. Association for Computational Linguistics.
- Maya Sen and Omar Wasow. 2016. Race as a bundle of sticks: Designs that estimate effects of seemingly immutable characteristics. Annual Review of Political Science, 19:499–522.
- Mind the gap: Improving the dissemination of cbt. Behaviour research and therapy, 47 11:902–9.
- A computational approach to understanding empathy expressed in text-based mental health support. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Cognitive reframing of negative thoughts through human-language model interaction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9977–10000, Toronto, Canada. Association for Computational Linguistics.
- Transparency of artificial intelligence/machine learning-enabled medical devices. NPJ Digital Medicine, 7.
- Responsible research with crowds: pay crowdworkers at least minimum wage. Commun. ACM, 61(3):39–41.
- The typing cure: Experiences with large language model chatbots for mental health support. ArXiv, abs/2401.14362.
- Artificial intelligence will change the future of psychotherapy: A proposal for responsible, psychologist-led development.
- Isabel Straw and Chris Callison-Burch. 2020. Artificial intelligence in mental health and the biases of language based models. PLoS ONE, 15.
- Charles B. Truax and Robert R. Carkhuff. 1969. Toward effective counseling and psychotherapy. Aldine Publishing Company.
- SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272.
- Lauren Walker. 2023. Belgian man dies by suicide following exchanges with chatbot. the Brussels Times.
- Decodingtrust: A comprehensive assessment of trustworthiness in gpt models. NeurIPS.
- Ethical and social risks of harm from language models. ArXiv, abs/2112.04359.
- Joseph Weizenbaum. 1966. Eliza—a computer program for the study of natural language communication between man and machine. Commun. ACM, 9(1):36–45.
- Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Mental-llm: Leveraging large language models for mental health prediction via online text data.
- Mentalllama: Interpretable mental health analysis on social media with large language models. arXiv preprint arXiv:2309.13567.
- Coding inequity: Assessing gpt-4’s potential for perpetuating racial and gender biases in healthcare. In medRxiv.
- Can large language models transform computational social science? ArXiv, abs/2305.03514.
- Inducing positive perspectives with text reframing. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3682–3700, Dublin, Ireland. Association for Computational Linguistics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.