AI Wizards at CheckThat! 2025: Enhancing Transformer-Based Embeddings with Sentiment for Subjectivity Detection in News Articles
Abstract: This paper presents AI Wizards' participation in the CLEF 2025 CheckThat! Lab Task 1: Subjectivity Detection in News Articles, classifying sentences as subjective/objective in monolingual, multilingual, and zero-shot settings. Training/development datasets were provided for Arabic, German, English, Italian, and Bulgarian; final evaluation included additional unseen languages (e.g., Greek, Romanian, Polish, Ukrainian) to assess generalization. Our primary strategy enhanced transformer-based classifiers by integrating sentiment scores, derived from an auxiliary model, with sentence representations, aiming to improve upon standard fine-tuning. We explored this sentiment-augmented architecture with mDeBERTaV3-base, ModernBERT-base (English), and Llama3.2-1B. To address class imbalance, prevalent across languages, we employed decision threshold calibration optimized on the development set. Our experiments show sentiment feature integration significantly boosts performance, especially subjective F1 score. This framework led to high rankings, notably 1st for Greek (Macro F1 = 0.51).

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI to tell the difference between opinion and fact in news articles. The team built systems that read a single sentence and decide if it’s subjective (an opinion, feelings, or biased language) or objective (plain facts). They tested their systems in multiple languages and even on new languages the system hadn’t seen before.
Key Questions
The research tries to answer simple, practical questions:
- Can AI spot subjective sentences in news reliably, even when it only sees one sentence and not the full article?
- Does adding “sentiment” (how positive, negative, or neutral a sentence sounds) help the AI detect subjectivity?
- How can we handle the fact that most sentences in the datasets are objective, making it harder to catch the fewer subjective ones?
- Will the system work well across different languages, including languages it wasn’t trained on?
Methods and Approach
To explain the approach, think of the AI as a careful reader with two tools:
- A “language understanding machine” that turns sentences into numbers the computer can understand.
- A “feeling meter” that guesses whether a sentence sounds positive, neutral, or negative.
Here’s how the team put this together:
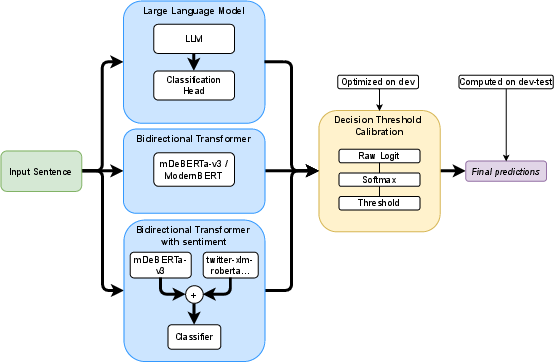
- They used transformer models (like mDeBERTaV3, ModernBERT, and a small Llama model). Transformers are powerful AI readers trained on lots of text. These models create a numerical summary of a sentence (an “embedding”) that captures its meaning.
- They added sentiment scores to that summary. Imagine the sentence’s meaning as a long barcode of numbers. The team stuck three extra numbers onto it: the chances that the sentence is positive, neutral, or negative. This is called “sentiment augmentation.”
- They then trained the model to classify each sentence as subjective or objective. Training means showing the model many labeled examples so it can learn patterns.
- Because the datasets had more objective sentences than subjective ones (class imbalance), the model could become biased toward predicting “objective.” To help with that, they tuned the “decision threshold”—the cut-off where the model says “this looks subjective.” Think of it like adjusting a dial to catch more of the rare subjective sentences without making too many mistakes.
- They tested the system in three settings:
- Monolingual: Train and test in the same language (like only German).
- Multilingual: Train on all available languages mixed together.
- Zero-shot: Train on some languages and test on new, unseen languages (like Greek), to see if the AI can generalize.
Main Findings
The team’s results showed clear patterns:
- Adding sentiment really helped, especially for finding subjective sentences. In English and Italian, performance improved noticeably when the “feeling meter” was included.
- Calibrating the decision threshold boosted results when one class (usually objective) was much more common. This made the system better at catching the fewer subjective sentences.
- mDeBERTaV3 (a strong multilingual transformer) was the most reliable overall. ModernBERT was competitive for English. The small Llama model didn’t do as well for this specific task and setup.
- Arabic was challenging across the board. The team even tried translating Arabic sentences into English before training, but that didn’t help—likely because translation can lose subtle meanings and cultural cues that matter for subjectivity.
- In the challenge, their approach ranked highly in several settings, including 1st place for Greek in the zero-shot test (Macro F1 = 0.51). This shows their method can generalize to new languages fairly well.
What do these scores mean?
- F1 score is a measure of how well the model balances catching the right sentences while avoiding mistakes. “Macro F1” gives equal importance to subjective and objective classes. “Subjective F1” focuses only on how well the system detects subjective sentences (which are the trickier ones).
- Improvements in Subjective F1 are especially important because subjective sentences are rarer and more crucial for tasks like fact-checking.
Why It Matters
Being able to separate opinions from facts in news helps:
- Fact-checkers focus on claims that can be verified and set aside opinions that can’t be fact-checked the same way.
- Readers and platforms spot potentially biased or emotionally charged content more easily.
- Multilingual tools serve people in many languages and can even handle new languages without retraining from scratch.
The big takeaway is simple: combining a strong LLM with a clear “feeling” signal, and then carefully adjusting the decision dial, makes AI better at spotting subjective sentences. This blend of smart modeling (transformers), helpful side information (sentiment), and practical tuning (threshold calibration) is a promising recipe for building better tools to fight misinformation and support trustworthy news analysis.
Knowledge Gaps
Knowledge gaps and open questions
The paper advances sentiment-augmented transformer models for subjectivity detection but leaves several concrete gaps and open questions:
- Domain shift of auxiliary sentiment model: quantify how using a Twitter-trained sentiment model affects performance on news domains per language and topic; compare against news-specific sentiment/emotion models.
- Alternative sentiment sources: benchmark multiple multilingual sentiment/emotion models (e.g., XLM-R variants, emotion classifiers, irony/sarcasm detectors) and assess which signals (polarity vs. emotions like anger, contempt, irony) most improve SUBJ F1.
- Fusion strategies: systematically compare late concatenation to attention-based fusion, gating, cross-attention, FiLM conditioning, and prompt-based conditioning; include ablations on feature dimensionality and position of fusion (encoder vs. classifier head).
- Joint learning vs. post-hoc features: evaluate multi-task learning (subjectivity + sentiment/emotion) and end-to-end differentiable auxiliary heads vs. fixed external scores; measure whether joint training mitigates error propagation from the sentiment model.
- Probability calibration: analyze calibration quality (ECE/Brier score) and test temperature scaling or isotonic regression; assess impact on thresholding and cross-language transfer.
- Thresholding strategy robustness: compare per-language vs. global thresholds; evaluate stability across runs and sensitivity to dev-set size; test alternative metrics (Youden’s J, cost-sensitive thresholds) and dynamic thresholds for zero-shot settings without target-language dev data.
- Class imbalance methods: provide empirical comparisons with focal loss (briefly mentioned), re-weighting schemes, class-balanced loss, oversampling/undersampling, and mixup; report precision–recall trade-offs and per-class calibration under each.
- Multilingual sampling: investigate language-balanced or temperature-based sampling vs. plain concatenation to prevent dominance by larger languages; quantify effects on low-resource languages.
- Context utilization: test adding local context (preceding/following sentences) and document cues (section headings, quotes) to mitigate sentence-level ambiguity; assess whether discourse markers or quotation detection reduce errors.
- Arabic underperformance: perform deeper diagnostics (tokenization coverage, morphological segmentation, diacritics, dialectal variation, script normalization, named entity frequencies); compare Arabic-specific encoders (AraBERT, CAMeLBERT) and segmenters; examine annotation consistency and sentiment-label correlation shifts in Arabic data.
- Machine translation approaches: revisit Arabic translation with higher-quality NMT (e.g., NLLB-3.3B), pivot or round-trip translation, and translationese controls; compare translating all languages into a pivot vs. only Arabic; evaluate sentiment preservation across translation.
- Zero-shot generalization: systematically study the role of language similarity/typological distance and script differences on transfer; include LASER/LaBSE-based similarity features to design training mixtures; analyze per-language error profiles for unseen languages beyond headline metrics.
- Larger LLMs and PEFT: explore 7B+ LLMs with diverse PEFT configs (LoRA rank, target layers, adapters) and instruction tuning vs. vanilla fine-tuning; quantify compute–performance trade-offs and data efficiency.
- Pooling and representation choices: compare [CLS] vs. mean/max pooling and sentence embedding methods (e.g., Sentence-BERT); test layer-wise weighted pooling and prompt-based classification for LLMs.
- Variance and significance: report multiple runs, random seeds, confidence intervals, and statistical significance to establish robustness given small dev/dev-test sizes (especially for Bulgarian).
- Error taxonomy: build a fine-grained error analysis (e.g., quotes/reported speech, hedging/modality, rhetorical questions, sarcasm/irony, stance) to identify systematic failure modes and guide feature/model design.
- Topic/domain robustness: evaluate performance across topics, outlets, and publication styles; test out-of-distribution generalization and domain adaptation methods (adversarial alignment, CORAL).
- Probability-to-decision pipeline: assess whether threshold tuning on dev overfits to that distribution; explore cross-validation for threshold selection and meta-calibration that transfers across languages.
- Granularity of subjectivity: experiment with regression/ordinal labels or multi-level subjectivity (as noted in related work) and test whether fine-grained training improves binary classification.
- Neutral and mixed cases: examine how neutral sentiment interacts with subjective labels (e.g., persuasive but affect-neutral sentences); add features for subjectivity cues beyond sentiment (modality, epistemic markers, intensifiers, discourse connectives).
- Interpretation and feature attribution: apply SHAP/LIME/attention analyses to understand when sentiment helps or harms and whether models rely on spurious cues (e.g., punctuation, proper nouns).
- Data quality and cross-lingual consistency: audit annotation agreement across languages, guidelines adherence, and potential label noise; measure how inconsistencies impact training and transfer.
- Training efficiency and latency: profile training/inference costs for sentiments-augmented vs. baseline models; evaluate whether the added pipeline overhead justifies the gains in production settings.
- Thresholding in zero-shot targets: define principled threshold selection when no target-language dev set exists (e.g., unsupervised calibration, temperature scaling from source languages, confidence-based criteria).
- Ensembling: test ensembles across base encoders, with/without sentiment, or across seeds to improve stability and zero-shot performance.
- Sentence length and truncation: quantify performance as a function of length; validate that 256-token truncation does not disproportionately harm specific languages or subjective constructions.
- Quote and reported speech handling: add explicit quote detection and speaker attribution; examine whether distinguishing reported third-party opinions (labeled objective in the guidelines) reduces false positives.
- Fairness and bias: investigate performance disparities across languages, dialects, and topics (e.g., political vs. non-political); assess potential biases introduced by the Twitter-trained sentiment model.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with the paper’s current models, code, and workflow (sentiment-augmented transformer fine-tuning + decision-threshold calibration).
- Subjectivity-aware fact-checking triage
- Sectors: media, software, public policy
- What this enables: Automatically flags objective sentences from news streams to feed into claim extraction and verification pipelines; routes subjective content for opinion/bias workflows.
- Tools/products/workflows: API or microservice that ingests article sentences, returns SUBJ/OBJ labels with calibrated thresholds; integration into existing fact-checking CMS or claim-matching pipelines.
- Assumptions/dependencies: Availability of a development set to calibrate thresholds per language/domain; performance varies by language (Arabic notably weaker); news domain mismatch of the sentiment model can slightly reduce precision.
- Newsroom CMS assistance for objectivity
- Sectors: media, enterprise software
- What this enables: Real-time, sentence-level guidance for journalists and editors to identify subjective phrasing; “objectivity score” for drafts and post-publication audits.
- Tools/products/workflows: WordPress/Drupal plugins; newsroom editorial dashboards highlighting subjective sentences and offering rewrites; per-article “subjectivity ratio.”
- Assumptions/dependencies: Editorial buy-in; latency budget to run base model + sentiment pass; clear UX to avoid over-penalizing legitimate opinion sections.
- RAG pre-filtering for higher factuality
- Sectors: software, enterprise AI
- What this enables: Improve retrieval-augmented generation by filtering out subjective sentences before indexing or answering, reducing hallucinations and opinion bleed in summaries and Q&A.
- Tools/products/workflows: A pre-index filter in vector pipelines; sentence-level SUBJ/OBJ flags stored as metadata; threshold tuning per corpus.
- Assumptions/dependencies: The task is sentence-level without broader context; some subjective sentences may contain verifiable facts (risk of over-filtering).
- Social listening and PR analytics
- Sectors: marketing, finance, media intelligence
- What this enables: Differentiate subjective commentary from objective reporting in news and social/newswire blends; track spikes in subjective sentiment-bearing narratives around brands, sectors, or leaders.
- Tools/products/workflows: Dashboards correlating SUBJ rates with sentiment polarity; alerts on sudden increases in subjective coverage; feed prioritization.
- Assumptions/dependencies: Sentiment model is trained on Twitter; domain adaptation to news may improve accuracy; language-specific calibration recommended.
- Brand safety and ad placement quality control
- Sectors: adtech, media
- What this enables: Down-rank highly subjective/news-opinion content for certain campaigns seeking neutral contexts; enforce inventory quality policies.
- Tools/products/workflows: Pre-bid or pre-placement classifier returning a subjectivity score; policy-based rules in ad servers.
- Assumptions/dependencies: Policy definitions of “safe” subjectivity differ by advertiser; local regulations and publisher policies apply.
- Financial news filters for risk signals
- Sectors: finance, fintech
- What this enables: Flag subjective statements in company or macroeconomic coverage to help analysts separate opinion from fact; use “subjectivity ratio” as a covariate in risk or volatility models.
- Tools/products/workflows: Terminals/plugins labeling news sentences; backtests correlating SUBJ share with volatility around events.
- Assumptions/dependencies: Requires careful threshold calibration to limit false positives; backtesting to validate predictive value; compliance sign-off.
- Academic annotation accelerators
- Sectors: academia, research software
- What this enables: Human-in-the-loop pre-annotation for subjectivity to reduce labeling cost; active learning loops using calibrated thresholds.
- Tools/products/workflows: Annotation tool plugins (e.g., Prodigy, Label Studio) with prelabels; confidence-based sampling.
- Assumptions/dependencies: Domain and language shift may affect prelabel quality; calibrate on a small in-domain dev set.
- Cross-lingual monitoring with zero-shot deployment
- Sectors: media intelligence, public policy, NGOs
- What this enables: Rapid rollout of subjectivity detection in new languages (e.g., Greek, Romanian, Ukrainian) without new labeled data; early situational awareness.
- Tools/products/workflows: Unified multilingual model with language tags; per-language threshold calibration if a small dev set becomes available; fallback to default thresholds when not.
- Assumptions/dependencies: Zero-shot performance is uneven across languages; Arabic remains challenging; domain adaptation advisable.
- Browser extension for media literacy
- Sectors: education, consumer software
- What this enables: Highlight subjective sentences while reading news to train critical reading habits; toggle to view objective-only summaries.
- Tools/products/workflows: Lightweight client calling a hosted inference API; per-site caching; opt-in privacy controls.
- Assumptions/dependencies: Latency and privacy constraints; disclaimers on classifier limits and language coverage.
- E-discovery and compliance review
- Sectors: legal, compliance
- What this enables: Prioritize objective statements for evidence gathering; distinguish opinion from fact in regulatory filings, press releases, and internal communications.
- Tools/products/workflows: Document review platforms with sentence-level SUBJ/OBJ flags; filters for “factual assertions.”
- Assumptions/dependencies: Legal definitions may require human validation; domain adaptation improves reliability.
- Trust and safety triage for civic discourse
- Sectors: platforms, public policy
- What this enables: Identify highly subjective political narratives in news-sharing contexts for prioritization, not suppression; enable targeted counterspeech and literacy prompts.
- Tools/products/workflows: Queue prioritization based on subjectivity and sentiment; policy rules for escalation.
- Assumptions/dependencies: Must not be used as a proxy for truth; fairness audits for language and culture.
- Lightweight English-only deployments
- Sectors: software, SMBs
- What this enables: Efficient English subjectivity detection using ModernBERT for on-prem or edge deployments where resources are limited.
- Tools/products/workflows: Containerized ModernBERT service; CPU-friendly inference with quantization.
- Assumptions/dependencies: English-only; performance trade-offs vs. mDeBERTa; threshold tuning still recommended.
Long-Term Applications
These use cases are feasible but require further research, scaling, or development (e.g., domain-adapted sentiment/emotion models, improved cross-lingual robustness, policy/standards work).
- Domain-adapted sentiment and emotion fusion for news
- Sectors: media, software, academia
- What this could enable: Stronger subjectivity detection by replacing Twitter-trained sentiment with news-trained sentiment/emotion (e.g., anger, irony, sarcasm); better handling of culturally specific expressions.
- Dependencies: Curating multilingual news sentiment/emotion datasets; multi-task training; careful fairness evaluation.
- Early-fusion pretraining and multi-task learning
- Sectors: software, academia
- What this could enable: Jointly learning subjectivity with sentiment/emotion cues during pretraining to improve generalization; attention-based fusion architectures for better feature use.
- Dependencies: Significant compute; new pretraining corpora; rigorous calibration methods.
- Robust Arabic and low-resource language support
- Sectors: media, NGOs, public policy
- What this could enable: High-quality subjectivity detection in Arabic and other low-resource languages via language-specific adapters, better tokenization, or targeted data collection.
- Dependencies: New labeled corpora; culturally informed annotation; dedicated evaluation protocols.
- Standards for subjectivity “nutrition labels” in news
- Sectors: media, policy, platforms
- What this could enable: Consistent, machine-readable labels indicating per-article subjectivity ratios and sentence-level flags; platform-level transparency and consumer choice.
- Dependencies: Industry consensus (newsrooms, aggregators, platforms); regulatory guidance; third-party audits.
- Factuality-aware LLM workflows
- Sectors: software, enterprise AI
- What this could enable: LLMs that explicitly condition on objective-only inputs for summarization and QA; LLM critique pipelines that differentiate subjective claims from factual premises.
- Dependencies: Tight RAG integration; instruction-tuned models respecting SUBJ/OBJ signals; evaluation suites for faithfulness.
- Bias, stance, and propaganda detection stacks
- Sectors: media intelligence, academia, policy
- What this could enable: Subjectivity features as inputs to richer models for bias, stance, and propaganda; cross-task transfer to improve explainability and auditability.
- Dependencies: Multi-task corpora; interpretable modeling; governance frameworks avoiding misuse.
- Editorial compliance and ethics scoring
- Sectors: media, adtech
- What this could enable: Automated audits aligned to newsroom style guides and regulatory codes; content labeling for monetization and compliance.
- Dependencies: Custom rule layers per publisher/regulator; appeal/override workflows; human-in-the-loop assurance.
- Mobile/on-device subjectivity detection
- Sectors: consumer apps, education
- What this could enable: Private, low-latency subjectivity highlighting in reader apps without cloud calls.
- Dependencies: Distilled/quantized multilingual models; hardware acceleration; language packs.
- Adaptive thresholding at scale
- Sectors: software, platforms
- What this could enable: Continual calibration to evolving news cycles and class distributions, with automatic per-source or per-topic thresholds.
- Dependencies: Online evaluation streams; drift detection; guardrails against overfitting or instability.
- Evaluation toolkits and benchmarks
- Sectors: academia, industry consortia
- What this could enable: Shared, multilingual, domain-robust benchmarks for subjectivity detection; standardized calibration and fairness metrics.
- Dependencies: Community coordination; data sharing agreements; multilingual annotation capacity.
Notes on core assumptions and dependencies across applications
- Model performance is language- and domain-dependent; Arabic and some low-resource languages require targeted improvement.
- The sentiment auxiliary model is trained on social media; domain-adapted or news-specific sentiment/emotion models would improve precision.
- Decision threshold calibration materially impacts outcomes and requires a small, representative development set per language/domain.
- Sentence-level classification ignores broader article context; downstream systems should avoid treating SUBJ/OBJ as a proxy for truthfulness.
- Resource constraints (latency, GPU/CPU availability) and privacy requirements influence deployment choices (cloud vs on-device).
- Fairness and cultural variance must be audited, especially in multilingual settings and sensitive domains (politics, health).
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates to improve training stability and generalization. "Models are fine-tuned using the AdamW optimizer with a linear learning rate scheduler and warmup"
- attention-based fusion: A feature-integration approach where attention mechanisms dynamically weight multiple information sources (e.g., semantics and sentiment) before prediction. "Techniques such as attention-based fusion, which would allow the model to dynamically weigh the importance of semantic content versus sentiment signals, warrant investigation."
- auxiliary model: A secondary model used to generate supportive signals or features (e.g., sentiment probabilities) for the main task. "enhanced transformer-based classifiers by integrating sentiment scores, derived from an auxiliary model, with sentence representations"
- [CLS] token: A special token in transformer models whose final hidden state is used as a summary representation for classification tasks. "For all models, a standard classification head (a simple feed-forward neural network) is added on top of the [CLS] token representation (or the equivalent final hidden state for Llama)."
- class imbalance: A skewed distribution of labels where one class is significantly more frequent than another, complicating training and evaluation. "reveals a notable class imbalance across all languages"
- class weights: Weights applied to classes in the loss function to counteract imbalance by penalizing misclassification of minority classes more heavily. "employing Cross-Entropy Loss with class weights to initially mitigate class imbalance."
- classification head: The task-specific layers (often feed-forward) added on top of a pre-trained encoder to produce final predictions. "For all models, a standard classification head (a simple feed-forward neural network) is added on top of the [CLS] token representation (or the equivalent final hidden state for Llama)."
- cost-sensitive learning: Training methods that incorporate different misclassification costs for classes, aiming to improve performance on underrepresented classes. "algorithmic approaches like cost-sensitive learning or threshold adjustment"
- Cross-Entropy Loss: A standard classification loss that measures the difference between predicted probabilities and true labels. "employing Cross-Entropy Loss with class weights to initially mitigate class imbalance."
- cross-lingual transfer: The ability of models trained on some languages to generalize to other languages by leveraging shared multilingual representations. "While models like mBERT or XLM-R provide strong cross-lingual transfer baselines, their performance varies across language pairs and task specificities."
- decision threshold calibration: Post-hoc adjustment of the classification threshold to optimize a metric (e.g., F1) on a validation set, especially under class imbalance. "To address class imbalance, prevalent across languages, we employed decision threshold calibration optimized on the development set."
- disentangled attention mechanism: An attention design (in DeBERTa) that separates content and position information to improve representation learning. "mDeBERTaV3, with its disentangled attention mechanism, has shown strong performance on NLU benchmarks, making it suitable here."
- F1 score: The harmonic mean of precision and recall, commonly used to evaluate classification performance, especially under imbalance. "focusing on improving the F1 score for the subjective class."
- feature engineering: The process of designing and integrating informative features (e.g., sentiment scores) to enhance model performance. "The systematic integration of sentiment scores as a key feature engineering step, demonstrating its impact on improving subjective content classification."
- Focal Loss: A loss function that down-weights easy examples and focuses learning on hard, often minority-class examples. "An alternative, Focal Loss, is discussed in Appendix~\ref{sec:focal-loss}."
- grid search: A systematic search over a predefined set of hyperparameter values to find the best-performing configuration. "an optimal decision threshold is determined by conducting a grid search over values ranging from $0.1$ to $0.9$ ($0.01$ increment)"
- LLM: A transformer-based model with a large number of parameters trained on vast corpora to perform a wide range of language tasks. "Llama3.2-1B: A smaller-scale LLM."
- late fusion: Combining external features (e.g., sentiment probabilities) with learned representations at a later stage (e.g., before the classifier). "While our simple concatenation (late fusion) of sentiment scores proved effective, more sophisticated fusion mechanisms could yield better performance."
- linear learning rate scheduler: A schedule that adjusts the learning rate linearly during training, often paired with warmup. "Models are fine-tuned using the AdamW optimizer with a linear learning rate scheduler and warmup"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects trainable low-rank adapters into pre-trained weights. "Due to resource constraints on the environment, this model was fine-tuned using 8-bit quantization with LoRA as to fit inside a single P100 GPU."
- macro-average F1: The average F1 score computed independently for each class and then averaged, treating all classes equally. "Evaluation primarily focuses on macro-average F1 and SUBJ F1 scores, given the latter's importance amidst class imbalance."
- mBERT: Multilingual BERT; a transformer pre-trained on multiple languages enabling cross-lingual transfer. "While models like mBERT or XLM-R provide strong cross-lingual transfer baselines, their performance varies across language pairs and task specificities."
- mDeBERTaV3-base: A multilingual variant of DeBERTaV3 featuring disentangled attention and strong cross-lingual performance. "mDeBERTaV3-base: A powerful multilingual model chosen for its strong cross-lingual generalization capabilities, essential for handling the diverse languages in the task."
- ModernBERT-base: An efficient, English-centric transformer aiming for fast, memory-efficient fine-tuning and inference. "ModernBERT-base: A more recent English-centric model designed for efficiency and performance."
- parameter-efficient fine-tuning (PEFT): Techniques that adapt large models by training a small number of additional parameters rather than all weights. "through more advanced parameter-efficient fine-tuning (PEFT) techniques"
- quantization (8-bit): Reducing numerical precision (e.g., to 8-bit) to shrink memory footprint and speed up inference/training. "this model was fine-tuned using 8-bit quantization with LoRA as to fit inside a single P100 GPU."
- sentiment-based features: Explicit sentiment signals (e.g., positive/neutral/negative probabilities) used as input features for another task. "sentiment-based features"
- softmax: A function that converts logits into probabilities over classes for classification. "this optimized threshold is applied to the model's softmax outputs for classification on the test set."
- tokenizer: The component that segments text into tokens compatible with a model’s vocabulary and input constraints. "Sentences are tokenized using the specific tokenizer associated with each pre-trained model (mDeBERTa, ModernBERT, Llama)."
- warmup: A training phase where the learning rate gradually increases from a small value to stabilize optimization. "Models are fine-tuned using the AdamW optimizer with a linear learning rate scheduler and warmup"
- XLM-R: XLM-RoBERTa; a strong multilingual transformer model trained on large cross-lingual corpora. "While models like mBERT or XLM-R provide strong cross-lingual transfer baselines, their performance varies across language pairs and task specificities."
- zero-shot setting: Evaluation where the model is tested on languages or domains not seen during training. "In the zero-shot setting, where models were trained on a subset of languages and tested on unseen ones, performance varied depending on the specific language combinations."
Collections
Sign up for free to add this paper to one or more collections.