- The paper's primary contribution is Tangma, a learnable, tanh-guided activation function that leverages parameters α and γ to modulate nonlinearity and preserve gradients.
- It demonstrates superior accuracy and convergence on MNIST and CIFAR-10, achieving 99.09% and 78.15% validation accuracies respectively, outperforming ReLU, Swish, and GELU.
- The method offers architectural flexibility with minimal computational overhead, suggesting broad applicability to complex vision tasks and advanced deep network designs.
Tangma: A Tanh-Guided Activation with Learnable Parameters
Mathematical Characterization of the Tangma Activation
Tangma is formulated as Tangma(x)=x⋅tanh(x+α)+γx, where α and γ are learnable parameters integrated into every neuron. α acts as a horizontal shift for the nonlinear regime via an inflection point adjustment, while γ incorporates a direct linear skip connection, structurally reminiscent of parameterized activation approaches in the literature (2507.10560). This dual-parameter structure ensures not only smooth, non-saturating gradients but also provides architectural flexibility to adapt to varying input statistics across tasks and layers.
In the analysis, the derivative is given by tanh(x+α)+xsech2(x+α)+γ, giving nonzero gradients across the domain as long as γ=0. For small x, the output can be approximated as x⋅(tanh(α)+γ), ensuring linearity near the origin. In asymptotic regimes (x→±∞), the response saturates to (γ±1)x due to the limits of tanh, guaranteeing persistent gradients and mitigating vanishing/exploding gradient pathologies.
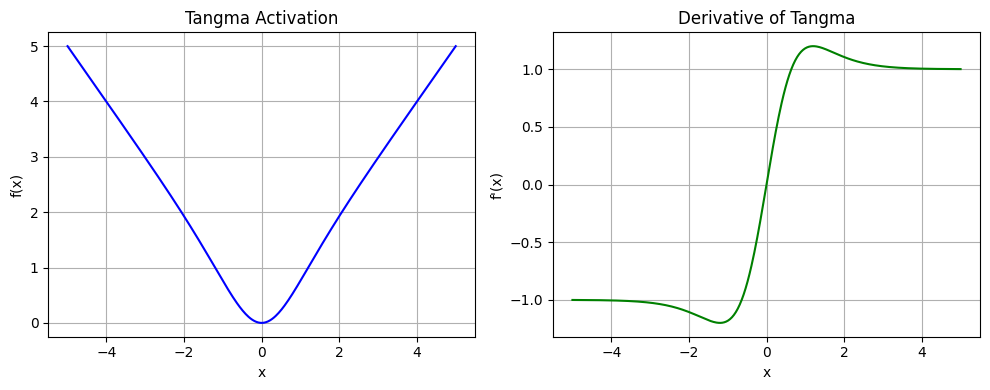
Figure 1: Tangma exhibits smooth activation with continuous derivatives, stabilizing gradient flow across the input domain.
The effect of each parameter is visualized: γ modulates output slope and gradient preservation, while α efficiently controls the center and threshold of nonlinear transition.
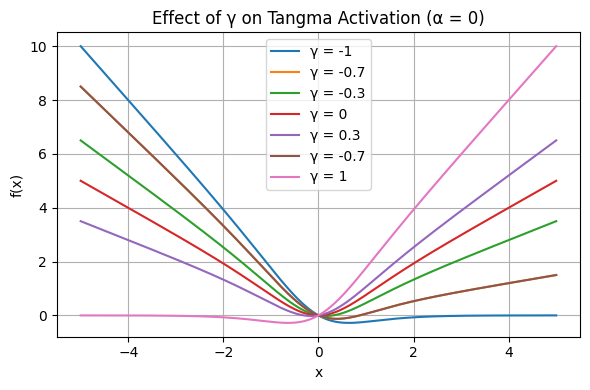
Figure 2: Varying γ shows monotonic slope changes, corresponding to gradient preservation in both activation tails.
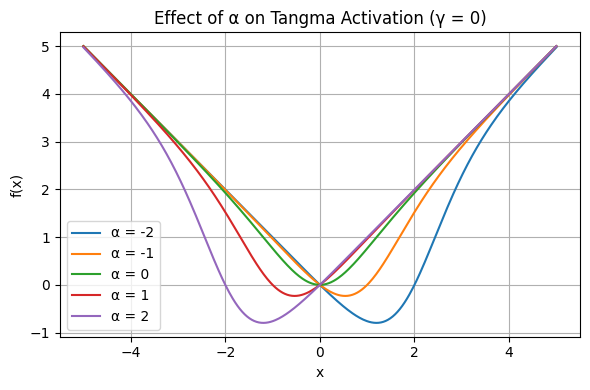
Figure 3: Modulating α horizontally shifts the nonlinearity, relocating the transition region for neuron responsiveness.
Architectural Integration and Experimental Paradigm
Tangma was benchmarked against ReLU, Swish, and GELU activations in two canonical vision tasks: MNIST digit classification and CIFAR-10 object recognition. Both tasks utilize moderate-depth CNNs structured to isolate the variance attributable to the activation layer. In all models, both α and γ are instantiated per layer as learnable tensors and optimized via backpropagation alongside model weights.
MNIST data (28×28 grayscale) employs a two-stage convolutional-MLP pipeline with aggressive dropout regularization, while CIFAR-10 leverages deeper convolutional stacks and normalization due to increased image complexity.
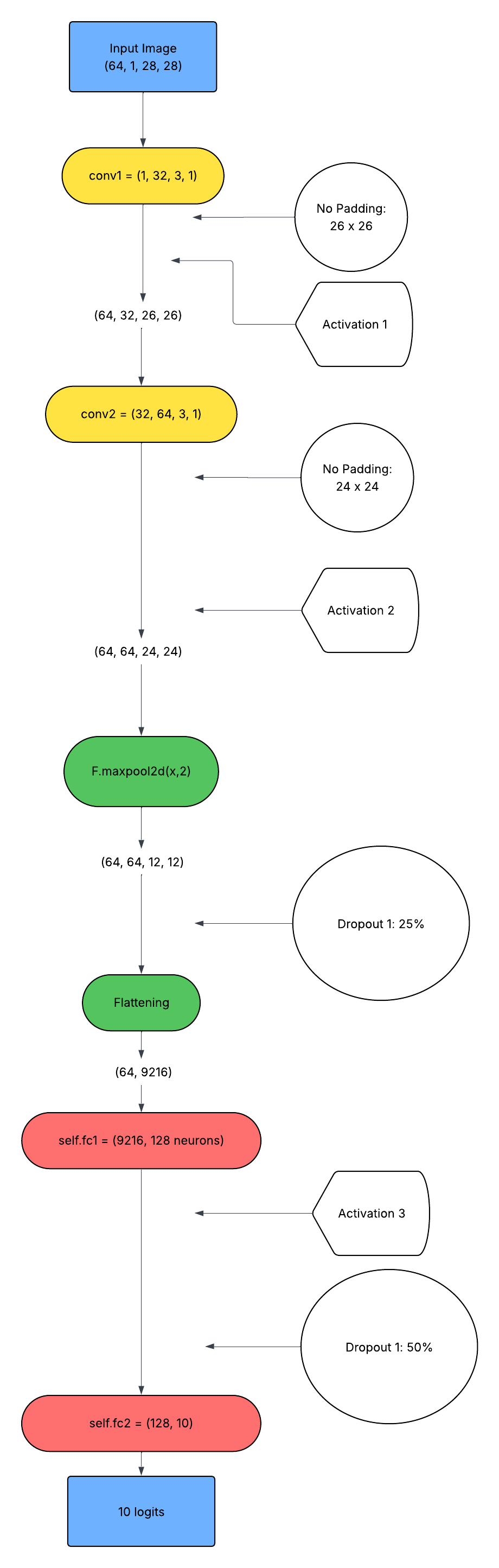
Figure 4: The MNIST pipeline employs dual convolutional layers followed by dense projection and classification.
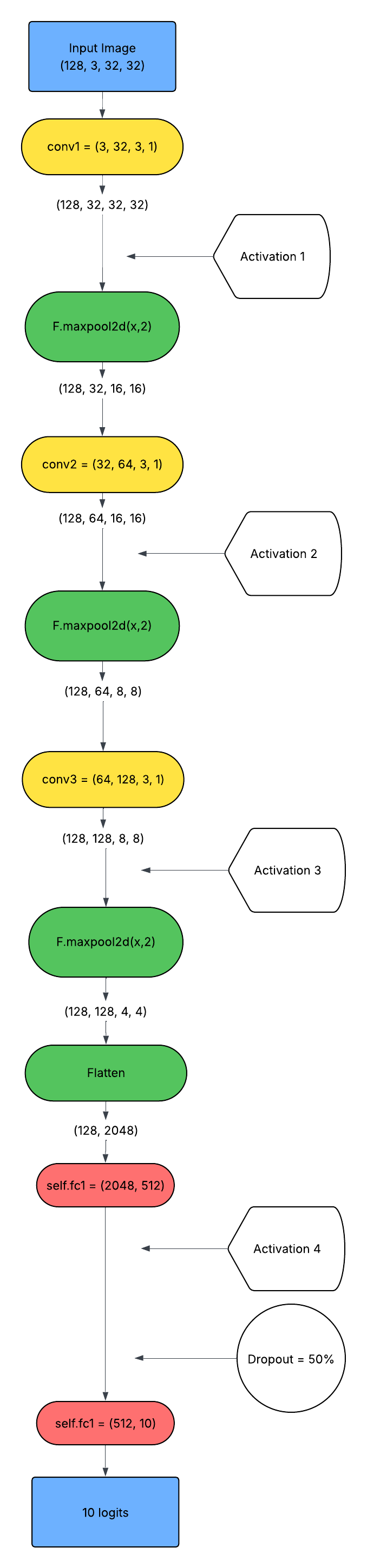
Figure 5: The CIFAR-10 architecture integrates three convolutional layers before dense categorization.
Empirical Analysis: MNIST and CIFAR-10
MNIST Results
Tangma achieves a final validation accuracy of 99.09%, outperforming ReLU (98.96%), Swish (98.91%), and GELU (98.94%). It consistently exhibits the lowest validation and training losses. Convergence is rapid and stable; Tangma achieves over 98.6% accuracy within three epochs, and both accuracy and loss curves demonstrate superior smoothness with minimal volatility throughout 10 epochs.
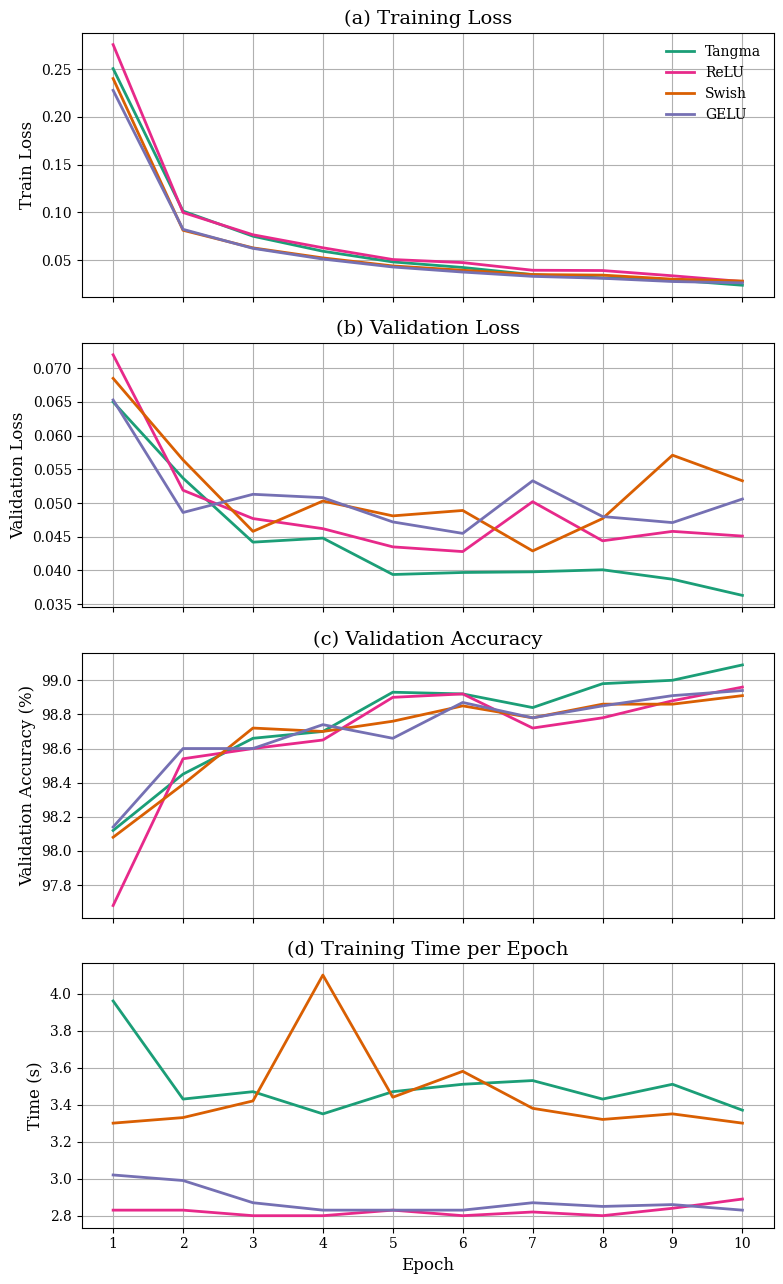
Figure 6: Tangma yields the lowest loss and highest accuracy curves on MNIST, coupled with competitive computational efficiency.
While computationally, Tangma (3.45s/epoch) is slightly slower than ReLU (2.82s) but on par with Swish and GELU, the empirical trade-off indicates favorable accuracy-to-runtime characteristics, especially on higher precision tasks.
CIFAR-10 Results
On CIFAR-10, Tangma attains the top validation accuracy (78.15%) after 10 epochs, outperforming Swish (77.59%), GELU (77.99%), and ReLU (77.42%). Training loss falls to 0.2270, matching or exceeding alternatives. The validation loss plateaus slightly higher than ReLU but remains well within the competitive margin. Crucially, Tangma is more computationally efficient (8.97s/epoch) compared to Swish (11.2s) and GELU (11.3s), with only a marginal speed difference compared to ReLU (9.4s).
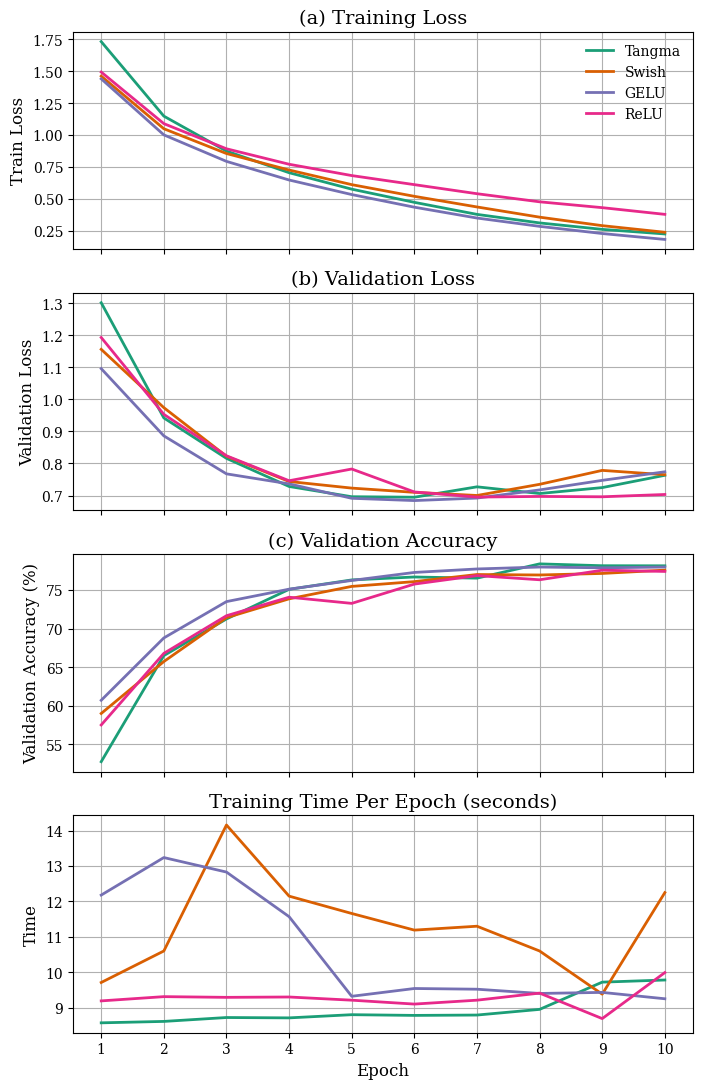
Figure 7: On CIFAR-10, Tangma achieves the top accuracy and fastest convergence with the lowest computational cost among nonlinear activation methods.
Parameter Dynamics
Examination of α and γ through training reveals rapid early increases during initial epochs, then plateauing as convergence is reached. On MNIST, both parameters remain modest in value but steadily rise as more structured patterns are learned, stabilizing once the network models complete digit structure. On CIFAR-10, α and γ increase faster and to higher values due to greater data heterogeneity and feature diversity.
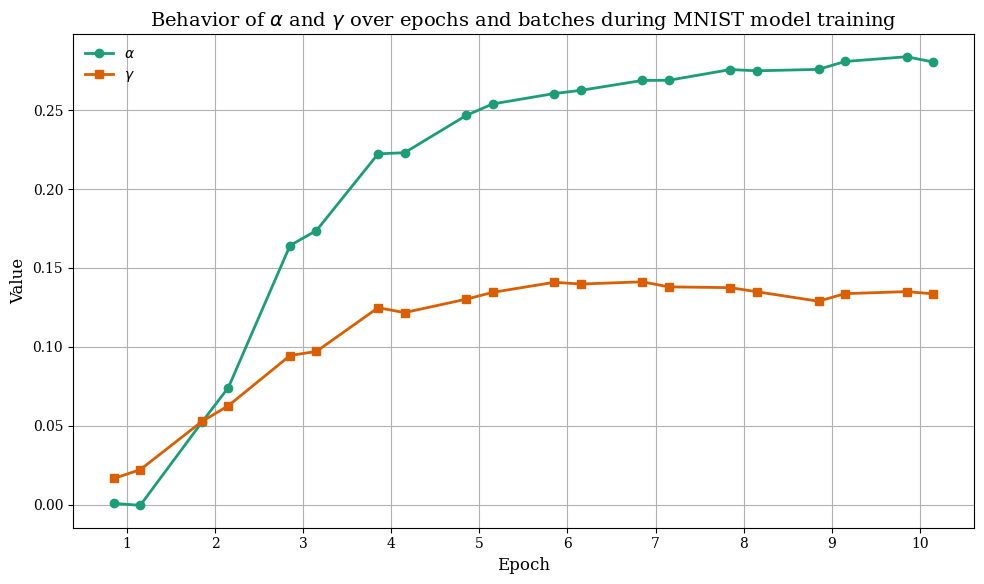
Figure 8: On MNIST, γ growth supports low-intensity signal preservation; α drifts upward for more robust saturation control.
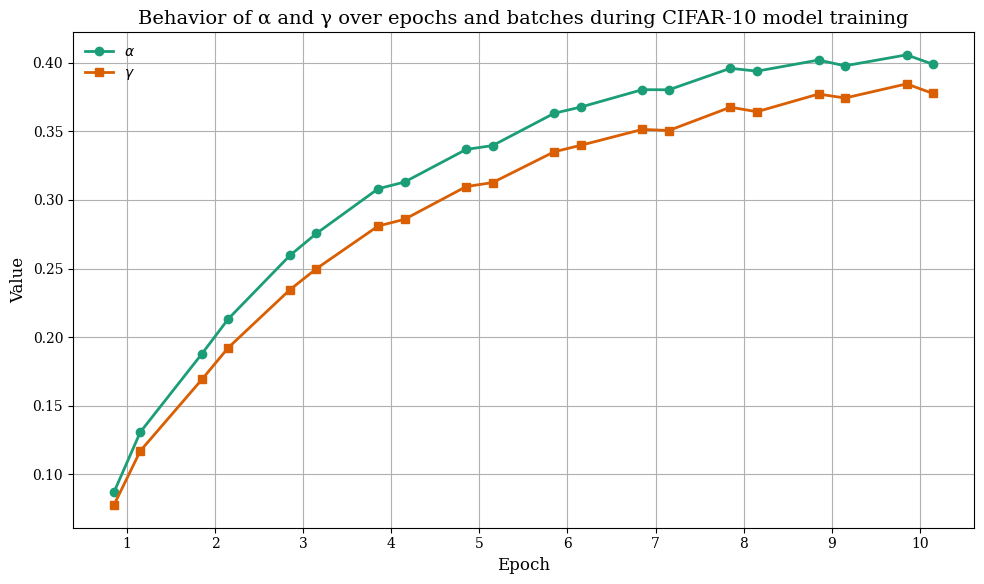
Figure 9: On CIFAR-10, both parameters rise rapidly, reflecting greater need for adaptivity in complex visual environments.
Theoretical and Practical Implications
The principal contribution of Tangma is the introduction of a tunable activation mechanism that directly integrates nonlinear inflection control (α) and gradient-preserving linearity (γ). Theoretically, this resolves historical limitations of piecewise activations (dying ReLUs, vanishing gradients in GELU/Swish under saturation) while endowing the model with the capacity to adapt activation regimes to data-dependent statistics. Practically, it translates into better optimization landscapes, faster convergence, increased sensitivity to subtle features, and stable gradients—critical for scalable vision architectures.
Tangma's learnable design means it can modulate the balance between feature selectivity and generalization per-layer, supporting efficient transfer to deeper or more complex models, including residual and transformer-based networks. Its computational profile is likewise favorable, yielding accuracy improvements without substantial runtime overhead.
Conclusion
Tangma, as a tanh-guided, parameterized activation, establishes empirically robust gains over canonical nonlinearities on image recognition tasks. The inclusion of per-neuron or per-layer α and γ ensures both flexibility and stability in gradient propagation, supporting efficient training and better generalization. Its demonstrated numerical and computational advantages advocate for further evaluation in deep and wide networks, large-scale vision, and sequence modeling problems. Given the generality of its formulation, future directions should include integration into architectures with layer-wise parameter sharing, transformer attention blocks, and differential learning rates for activation parameters. The evidence to date substantiates the relevance of Tangma as a strong, general-purpose activation function for advanced neural architectures.

