- The paper introduces a novel Wendland RBF activation function that enhances gradient flow and training stability in deep networks.
- It integrates compact support, smooth transitions, and adaptive tail behavior to address limitations of traditional activations.
- Empirical results in regression, classification, and image recognition tasks demonstrate faster convergence and improved accuracy.
Wendland RBF-Inspired Parametric Activation Functions for Deep Neural Networks
Introduction
This paper presents a parametric activation function for deep neural networks based on Wendland radial basis functions (RBFs), integrating principles of compact support, smoothness, and positive definiteness from approximation theory into neural activation design. The proposal aims to overcome limitations of canonical activation units such as ReLU, sigmoid, and tanh by introducing localized nonlinearity, tunable with learnable parameters, thereby enhancing gradient flow and stability in optimization.
Activation Function Landscape and Motivation
A comprehensive review of existing activation units highlights that, while ReLU and its derivatives mitigate vanishing gradient problems and encourage computational efficiency, they suffer from pathologies like the "dying ReLU" phenomenon. Sigmoid/tanh activations, conversely, ensure bounded responses but retrogress into saturation-induced gradient starvation for deeper architectures. Recent efforts such as ELU, Swish, GELU, and rational-based (PAU, FReLU) or composite (SinLU, SReLU) activations have explored the trade-space between smooth gradients, learnable parameters, and adaptability to data properties.
Smooth activations demonstrably yield superior gradient propagation in deep networks by enabling faster convergence of correlation matrices and improved representational stability, as articulated via edge-of-chaos analyses. However, most existing alternatives either lack locality or strong regularization effects. The paper thus positions Wendland RBFs as a rigorous basis for designing smooth, compactly supported, and parametrically adaptive activations.
Wendland RBFs as Neural Activation Primitives
Wendland functions are a family of positive-definite, compactly supported RBFs with flexible smoothness (controlled by parameter k). Their general form in dimension d is:
ϕd,k(r)=(1−r)+l+kp(r),
where r=∥x−y∥ and p(r) is a smoothness-inducing polynomial. Practically, C2 and C4 variants are of main interest for DNNs, offering C2 or C4 differentiability for propagation stability.
The proposed "enhanced Wendland" activation amalgamates three elemental parts:
- Wendland core: (1−αr)+k(kαr+1)
- Linear extension: λr
- Exponential tail: ϵe−βr
where r is a channel-wise norm, and α,λ,β,ϵ are learnable or fixed. This construction achieves: compact support (mitigating gradient explosion and encouraging sparsity), smooth transitions (preventing gradient starvation), and tail stabilization (through linear and exponential terms).
Empirical Evaluation
The paper rigorously benchmarks the Wendland-inspired activation versus conventional and recent alternatives through synthetic regression, low-dimensional classification, and standard image recognition tasks.
Sine Function Regression
The function learning experiment involves fitting a sine wave with a three-layer MLP using different activation paradigms. The Wendland activation not only achieves lower approximation error but, due to its smooth governing polynomial and localized support, yields faster and more stable convergence throughout training epochs.
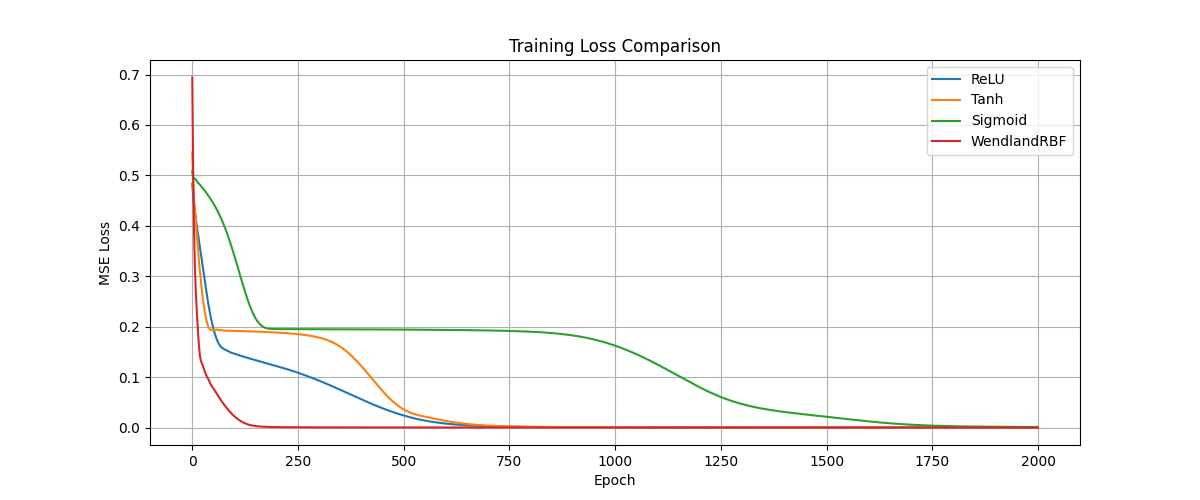
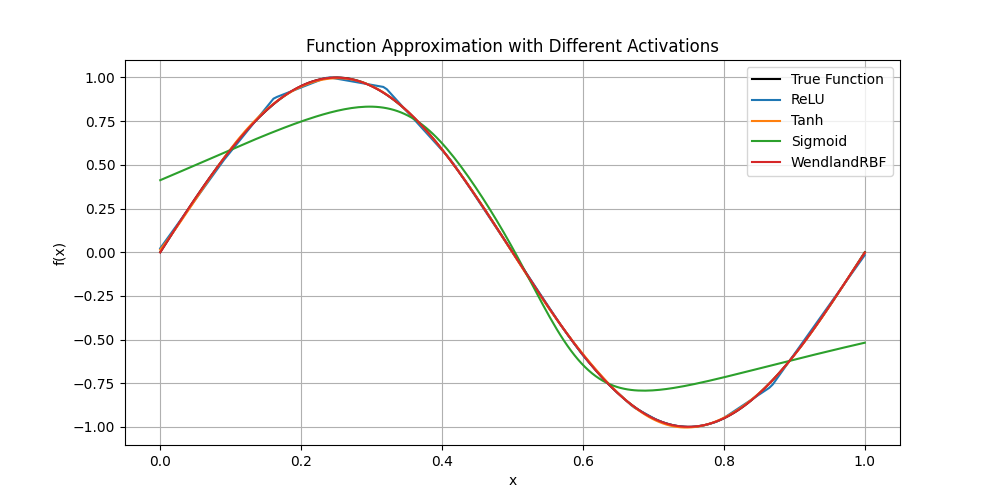
Figure 1: Comparative performance of activation functions approximating the sine function. The Wendland activation demonstrates superior fit and stable training.
Nonlinear Classification: Moons and Circles
To probe local structure modeling, the paper assesses the activations on "moons" and "circles" synthetic classification datasets. The Wendland activation, due to its locality and adaptability, delineates decision boundaries with higher fidelity and less overfitting, outperforming classical activations in test accuracy and learning dynamics.
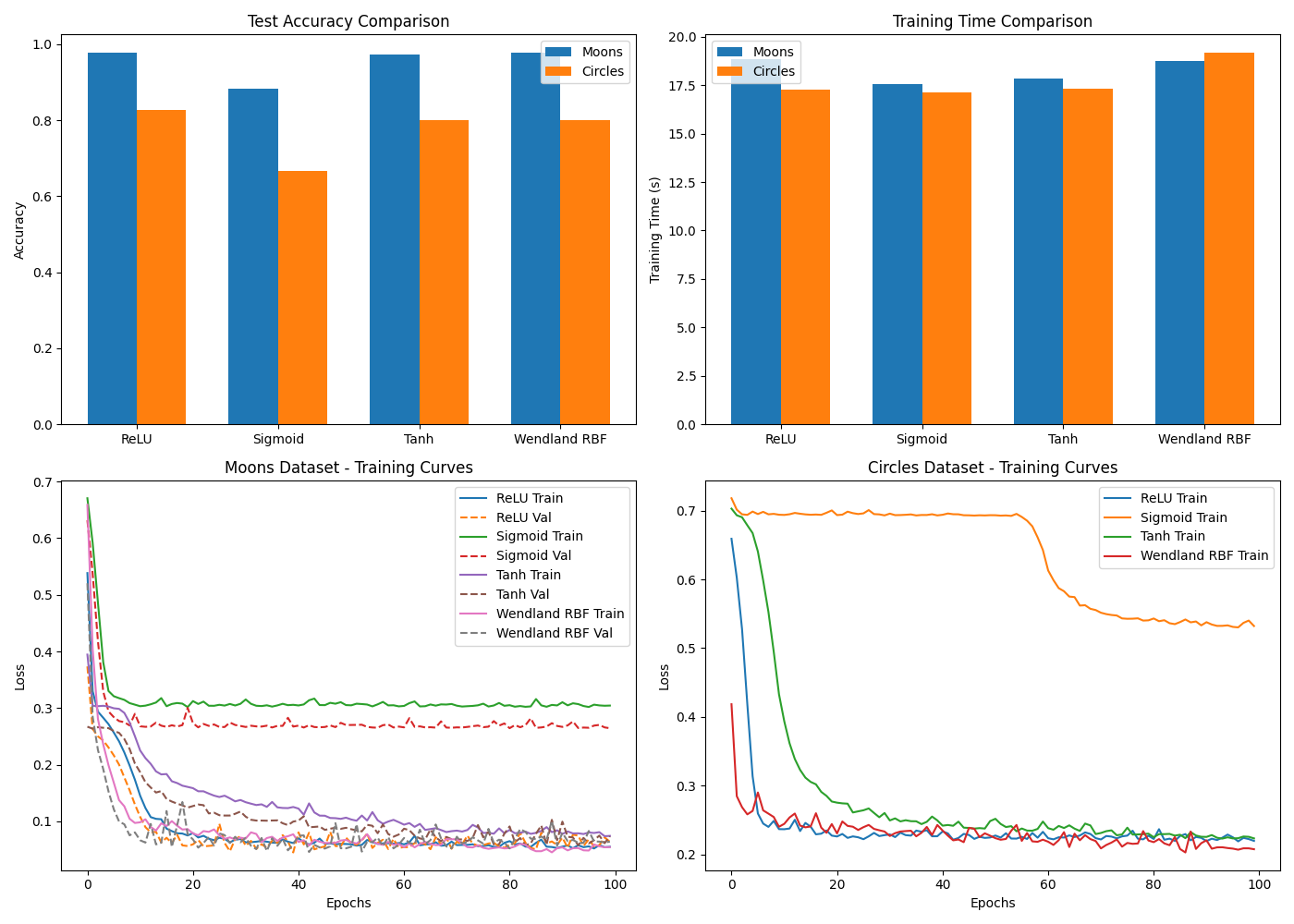
Figure 2: Activation function performance comparison on the moons and circles datasets. Localized support of the Wendland activation yields robust, smooth boundaries.
Benchmark Evaluation: MNIST and Fashion-MNIST
On MNIST and Fashion-MNIST, evaluated under VGG and LeNet, the Wendland activation marginally surpasses the best traditional activations on MNIST and demonstrates a notably higher accuracy on Fashion-MNIST (over 92% vs. ≤90.4% for all baselines). This indicates consistent generalization gains, attributable to the local, smooth expressivity of the activation.
Theoretical and Practical Implications
The theoretical exposition underscores that the enhanced Wendland activation maintains C2k smoothness, compact support (critical for preventing uncontrolled activation growth), and positive definiteness (ensuring benign optimization curvature). The adaptability via parameters (α,λ,β,ϵ) supports domain-specific fine-tuning and hybridization with other nonlinearities.
From a practical standpoint, the function’s locality acts as a built-in regularizer, discouraging overfitting. The smooth polynomial and tail terms stabilize both propagation and gradient backflow, supporting deep architectures without recourse to complex normalization layers. The compact support further optimizes sparse computation and limits the model's memorization capacity.
Future Directions
Potential avenues include hybridization of Wendland activations with global nonlinearities, searching for optimal polynomial/tail combinations for diverse domains, embedding the activation in physics-informed or operator-learning networks, and further theoretical analysis of its spectral properties in deep representation learning. Additional investigation into trainable locality radius for domain-adaptive explicit sparsity modulation is warranted.
Conclusion
The enhanced Wendland RBF-based activation function demonstrably advances the field of neural network nonlinearities by combining compactness, high-order smoothness, and parametric adaptability, yielding improved generalization and training stability, especially in tasks sensitive to overfitting and local structure. Its empirical superiority on nonlinear regression/classification and standard image data suggests broad utility, positioning it as a compelling alternative to classical and modern activations for future deep learning systems (2507.11493).

